
Как использовать noindex nofollow: Что такое и чем различаются noindex и nofollow
самая подробная справка от Q-SEO
В первую очередь давайте начнем с того, что существует несколько принципиально разных понятий: тег <noindex>, атрибут rel=”nofollow” и мета-тег <meta name=»robots» content=»noindex, nofollow» />. В этой статье мы подробно разберемся с их определениями и предназначениями.
Что такое тег <noindex>
<noindex>…</noindex> – тег, который предложили использовать поисковые системы для запрета индексации заключенного в него контента. Данный тег не входит в официальную спецификацию гипертекстовой разметки веб-страниц формата html.
Важно: распознается он лишь поисковыми системами Яндекс и Рамблер. Google не относится к числу поисковых систем, понимающих данный html тег.
Что такое атрибут rel=”nofollow”
rel=”nofollow” – значение, запрещающее поисковым системам переходить по ссылке, в которой используется данный атрибут.
Ниже будут рассмотрены все примеры использования тега <noindex> и атрибута rel=”nofollow”.
Тег noindex и атрибут rel=“nofollow”
Тег <noindex> для ссылок
Данный тег можно использовать для закрытия ссылок от индексации. Вот так это будет выглядеть в коде страницы:
<noindex><a href=»http://site.com/»>текст ссылки</a></noindex>
<noindex><a href=»http://site.com/»>текст ссылки</a></noindex> |
Тег <noindex> для контента
Данный тег можно использовать и для закрытия контента от индексации. Существует два способа. В коде страницы это будет выглядеть так:
<noindex>Текст, запрещённый к индексированию</noindex>
<noindex>Текст, запрещённый к индексированию</noindex> |
<!—noindex—>Текст, запрещённый к индексированию<!—/noindex—>
<!—noindex—>Текст, запрещённый к индексированию<!—/noindex—> |
Но стоит помнить, что данный тег понимают только поисковые системы Яндекс и Рамблер.
rel=”nofollow” для ссылок
Данный атрибут, чаще всего, используется оптимизаторами в том случае, если они хотят, чтобы поисковые системы не учитывали наличие исходящей ссылки, как фактор передачи веса, но ссылка всё равно будет изучена роботом. Вот как это выглядит в коде:
<a href=»http://site.com/» rel=»nofollow»>текст ссылки</a>
<a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Обычно, это уместно тогда, когда ссылки проставляются автоматически, например, в комментариях. Если вы не можете или не хотите поручиться за содержание страниц, на которые ведут ссылки с вашего сайта, следует вставлять в теги таких ссылок rel=»nofollow».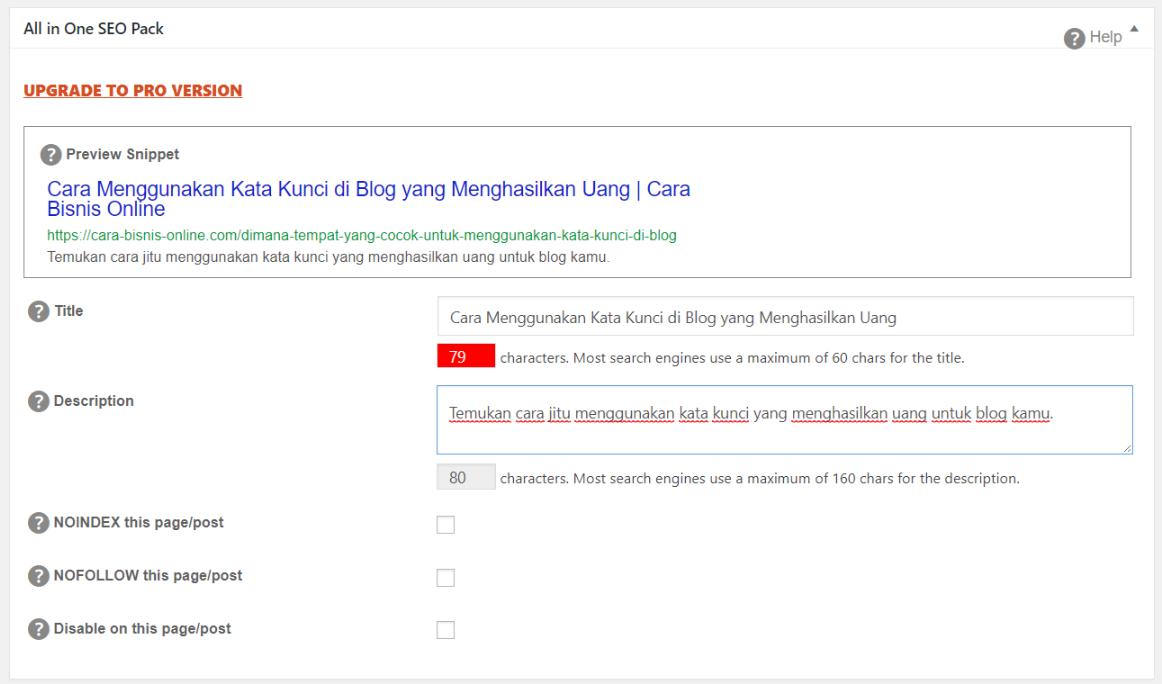 Такой атрибут понимают и Google-боты и Яндекс-боты, а в своих справках поисковые системы пишут следующее:
Такой атрибут понимают и Google-боты и Яндекс-боты, а в своих справках поисковые системы пишут следующее:
https://support.google.com/webmasters/answer/96569?hl=ru
https://yandex.ru/support/webmaster/controlling-robot/html.xml?lang=ru
Передает ли nofollow-ссылка вес
Если вы внимательно прочитали информацию по указанным выше ссылкам, теперь вы знаете, что вес по nofollow-ссылке не передается. Но из практики, мы можем смело сказать, что наличие таких ссылок в ссылочном профиле – очень полезный и достаточно естественный фактор в глазах поисковых систем. Но иметь много исходящих ссылок на своем сайте может быть негативным фактором, даже если они закрыты через данный атрибут.
Нужно ли использовать rel=”nofollow” для внутренних ссылок
Для того, чтобы сквозные ссылки, например на страницу регистрации или входа в личный кабинет не отнимали вес у других страниц, и не передавали его бесполезно, можно использовать rel=”nofollow”.
Как использовать совместно тег <noindex> и rel=”nofollow”
Вот пример кода, когда оптимизаторы используют тег <noindex> и атрибут rel=”nofollow” одновременно:
<noindex><a href=»http://site.com/» rel=»nofollow»>текст ссылки</a></noindex>
<noindex><a href=»http://site.com/» rel=»nofollow»>текст ссылки</a></noindex> |
Но этот метод полноценно работает только для роботов Яндекса. Google понимает только лишь rel=»nofollow»>.
Мета-тег <meta name=»robots» content=»noindex, nofollow» />
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и выглядит это следующим образом:
<head>
…
<meta name=»robots» content=»noindex, nofollow» />
. ..
</head>
..
</head>
<head> <meta name=»robots» content=»noindex, nofollow» /> … </head> |
Суть значений noindex и nofollow в мета-теге остается та же:
Noindex – запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.
Nofollow – запрещает поисковым роботам переходить по ссылкам на уровне страницы (и по внешним, и по внутренним).
Комбинации <meta name=»robots» content=»х, y» />
Есть несколько случаев, когда используют данный мета-тег на практике. Под эти случаи есть разные решения:
- <meta name=»robots» content=»noindex, follow» /> нужно использовать в случае, если вы не хотите, чтобы страница была проиндексирована поисковыми системами, но роботы смогли бы перейти по ссылкам с этой страницы на другие.
 Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой.
Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой. - <meta name=»robots» content=»noindex» />
- <meta name=»robots» content=»noindex, nofollow» /> – запрещает индексировать контент на соответствующей странице, а также запрещает роботам переходить по ссылкам.
- <meta name=»robots» content=»index, follow» /> – разрешает роботам индексировать страницу и ходить по ссылкам. Такой мета-тег не имеет смысла использовать, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия. Но если на вашем сайте он установлен и вы не собираетесь ограничивать работу робота, специально удалять его нет смысла.
- <meta name=»robots» content=»index, nofollow» /> — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.
- <meta name=»robots» content=»nofollow» /> — делает то же самое — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.
 Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой.
Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой.
Данный мета-тег можно использовать как для Google, так и для Яндекс отдельно
Если вам необходимо закрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />
Если закрыть от индексации только для Яндекса – <meta name=»yandex» content=»noindex»/>. Об этом также очень подробно написано в справке Яндекс.
Как сочетать meta name=»robots» с robots.txt и в чем принципиальная разница
Некоторые оптимизаторы не понимают разницу между мета-тегом <meta name=»robots» content=»noindex, nofollow» /> и закрытием соответствующей страницы в файле robots.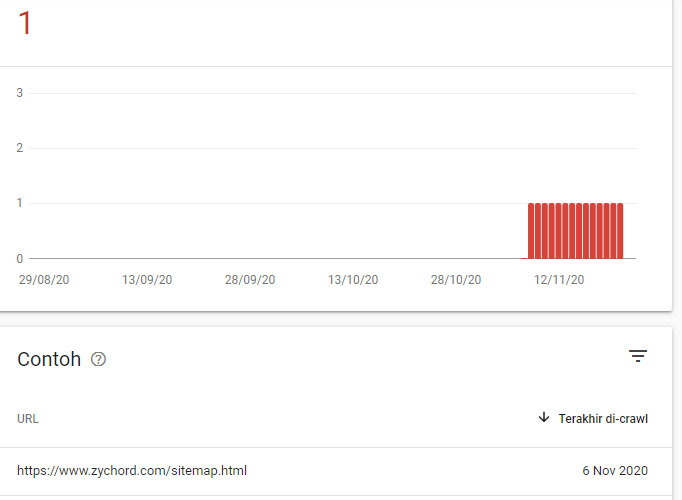 txt. Оба способа запрещают поисковым роботам индексировать страницу сайта, но отличие все же есть:
txt. Оба способа запрещают поисковым роботам индексировать страницу сайта, но отличие все же есть:
Первый – разрешает роботам зайти на эту страницу, увидеть мета-тег и исключить ее из индекса или не индексировать.
Второй – запрещает зайти на страницу, и если вдруг она ранее уже была проиндексирована, она может долго находится в индексе поисковых систем, даже если вы ее закроете в файле robots.txt, без права на переиндексацию, впоследствии вы можете видеть ее в поиске так:
Поэтому для непроиндексированных страниц можно использовать любой из вариантов.
Если же страница уже была проиндексирована, рекомендуется установить в секцию <head> мета-тег <meta name=»robots» content=»noindex, nofollow» />. Это исключит ее из индекса и предотвратит последующее попадение в него.
Если ваш сайт создан на WordPress, правильно настроить данные мета-теги поможет бесплатный плагин Yoast SEO. Примерно вот так это выглядит:
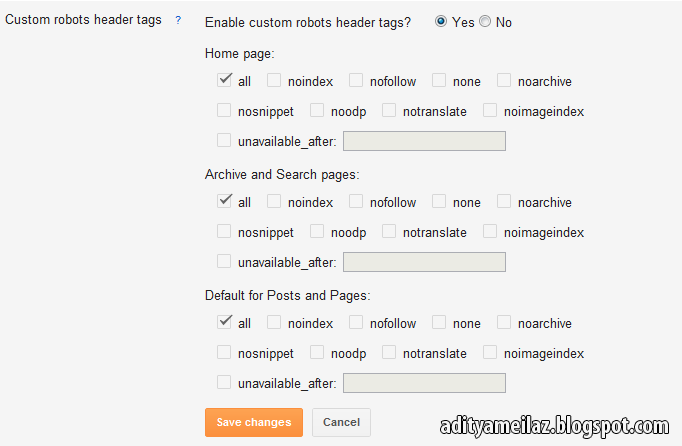
Помочь проанализировать наличие всех этих элементов (и мета-тегов и тегов и атрибутов) в коде страниц сайта может расширение для браузера RDS-бар:
Правильно настроив его, вы сможете видеть контент, завернутый в тег <noindex> (будет подсвечиваться):
Ссылки с rel=»nofollow» (ссылка будет перечеркнутой, а в данном случае она еще и завернута в тег <noindex>):
И использование мета-тега <meta name=»robots» content=»x, y» />:
Теперь вы знаете как с помощью данных методов настроить правильную индексацию страниц.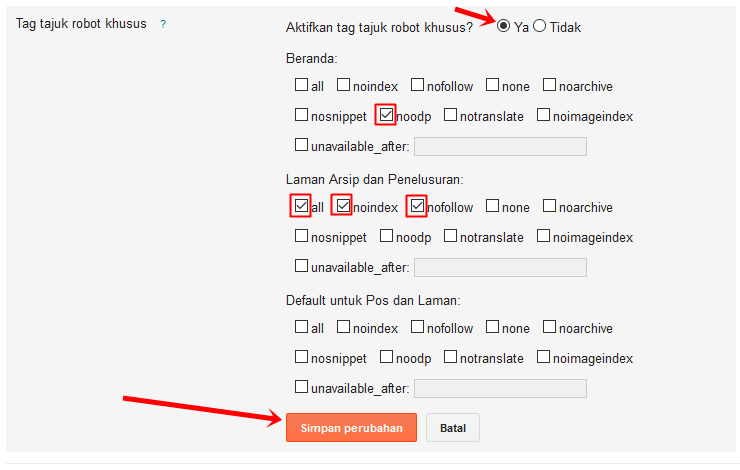 Это может оказать положительное влияние на процесс раскрутки веб-сайта.
Это может оказать положительное влияние на процесс раскрутки веб-сайта.
Комментарии
Комментарии
Что это за теги Nofollow и Noindex, в чем разница и как правильно прописывать
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.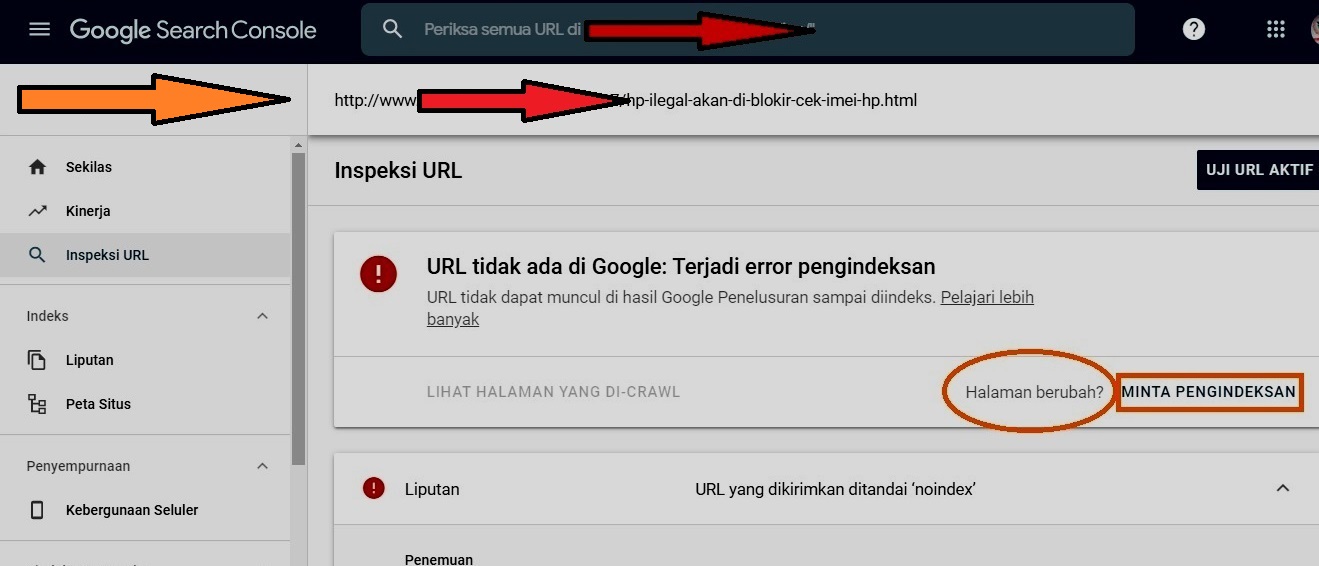
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
 Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots. txt заносите новые ссылки, неизвестные для Google и Яндекс.
txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots. txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
 txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots. txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
 txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически. Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
как, зачем и для чего используют в SEO
Noindex, nofollow имеют несколько разных понятий, и в зависимости от значений выполняют определенные функции.
- метатег <meta name=»robots» content=»noindex, nofollow» />;
- тег <noindex>;
- атрибут rel=”nofollow”.
Для чего же созданы эти элементы и в каких случаях их стоит применять? Давайте разберемся вместе.
1. Метатег robots
Поисковая выдача формируется из документов, просканированных и проиндексированных поисковым роботом. Но не вся информация должна попадать в индекс. И тогда на помощь приходит метатег robots, благодаря которому можно скрыть страницу от индексации поисковыми роботами.
Тег необходимо установить в секцию <head> для того, чтобы страница не попала в индекс.
Пример:
<head> <meta name = “robots” content = “noindex”/> </head> |
Большинство поисковых роботов понимают этот метатег. А при необходимости можно закрыть страницу только от определенного робота.
А при необходимости можно закрыть страницу только от определенного робота.
Например, от Google:
<meta name=«googlebot» content=«noindex»/>
Или только от Яндекс:
<meta name=«yandex» content=«noindex»/>
Что же тогда означает комбинация значений «noindex, nofollow»?
Как вы уже поняли, noindex запрещает индексировать страницу, включая весь контент, который на ней находится.
А nofollow запрещает поисковым роботам переходить как по внутренним, так и по внешним ссылкам, размещенным на странице.
Рассмотрим различные варианты значений метатега robots:
| <meta name=“robots” content=“noindex, nofollow”> | Запрещает индексировать страницу и переходить по ссылкам |
| <meta name=“robots” content=“index,follow”> | Разрешает индексировать страницу и переходить по ссылкам на ней. Но в этой комбинации нет необходимости, т. к. по умолчанию поисковые роботы выполняют те же действия |
| <meta name=“robots” content=“index,nofollow”> | Можно индексировать страницу, но нельзя переходить по ссылкам |
| <meta name=“robots” content=“noindex,follow”> | Нельзя индексировать страницу, но можно переходить по URL-адресам. Используется для того, чтобы страница не попала в индекс, но поисковые роботы могли посещать ссылки, размещенные на ней. |
Очень часто для запрета индексирования используют файл robots.txt. Но для поисковых роботов условия, написанные в нем, скорее служат рекомендациями и могут быть проигнорированы. Более надежным способом запрета от индексирования считается метатег <meta name=«robots» content=«noindex»/>.
Довольно часто для удаления уже проиндексированной страницы используют директиву Disallow в файле robots.txt. Это ошибка, ведь в таком случае вы запрещаете доступ к странице, и поисковый робот не удалит ее из индекса.
В выдаче поисковой системы вместо описания страницы вы увидите сообщение о том, что доступ к данной странице заблокирован с помощью файла robots.txt.
Чтобы удалить проиндексированную страницу из индекса, необходимо добавить метатег <meta name=“robots” content=“noindex,follow”>. Поисковый робот просканирует страницу, увидит атрибут noindex, и исключит страницу из индекса.
3. Атрибут rel=”nofollow”
rel=”nofollow” применим к тегу <а> и относится только к гиперссылке, для которой он прописан.
Как он выглядит:
| <a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Вид в коде страницы:
Рис. 1 — nofollow в коде страницы
История атрибута очень интересна. Изначально Google позиционировал nofollow как инструмент для борьбы со спамом в комментариях. Но это было в далеком 2005.
Затем шла борьба с накруткой PageRank. Все пытались манипулировать внутренним весом, чтобы у продаваемых страниц был самый высокий PageRank. Ведь ссылочный вес делился одинаково между всеми гиперссылками на странице, не учитывая rel=«nofollow». И поэтому в 2009 Google внес поправки, согласно которым ссылочный вес не передавался по ссылкам, к которым применим атрибут rel=«nofollow».
Более того, изменились правила передачи ссылочного веса. Например, если на странице Х размещены 3 ссылки (2 dofollow и 1 nofollow), а вес страницы Х равен 6 “баллам”, то до внесения изменений Гуглом каждая ссылка без nofollow получила бы по 3 “балла”. А сейчас такие ссылки получат по 2 “балла”. Это означает, что ссылочный вес разделяется между всеми внутренними ссылками, но передается только по dofollow.
Когда специалисты стали меньше заморачиваться над передачей ссылочного веса, Google заявил, что все купленные ссылки должны иметь атрибут rel=«nofollow», утверждая, что некоторые проплаченные ссылки ничем не отличаются от тех, что были получены естественным путем (когда люди просто делятся тем, что по их мнению может быть интересным и полезным для других). Таким образом Google стимулирует получать естественные ссылки путем создания качественного контента.
В каких случаях сейчас стоит использовать ссылки с атрибутом «nofollow»?
Могу порекомендовать вам использовать nofollow ссылки для того, чтобы:
- сделать ссылочный профиль сайта разнообразным;
- обезопасить себя от санкций, применив атрибут к некачественным ссылкам.
Noindex и nofollow – надежные помощники оптимизатора
Содержание:
Зачем использовать тег <noindex> и атрибут rel=«nofollow»
Невзирая на то, что мы упоминаем тег <noindex> и атрибут rel=«nofollow» в пределах одной статьи, они являются совершенно разными элементами кода страниц сайта и соответственно используются для различных целей. Для каких именно, читайте далее по тексту.
Тег <noindex>. Значение и условия применения
Тег <noindex> – размещаемый в HTML-коде странички тег, который запрещает боту поисковой системы Яндекс индексировать часть текста (заключенную внутри него). Тег noindex Яндекс ввел по собственной инициативе, которую до сегодняшнего дня разделяет лишь Рамблер.
Поэтому при использовании тега noindex, Google не будет обращать на него внимания.
Если нужно, чтобы не индексировалась ссылка, noindex не сможет помочь.
В данном примере от индексации будет закрыт лишь анкор «Курсы SEO», а сама ссылка все же будет учтена и по ней передастся вес.
Кстати, довольно часто встречающаяся в сети конструкция rel=«noindex» является ошибочной, поскольку это не атрибут, а тег.
Еще один момент, к которому нужно быть готовым – закрывая от робота часть текста, <noindex> приводит к тому, что валидация сайта будет содержать множество ошибок в коде. Причина все та же: среди тех, кто понимает тег noindex – Яндекс и никто более из существенных поисковиков. Кроме того, этот тег не является стандартизированным.
Но выход все же есть. Для того, чтобы исключить ошибки, связанные с использованием этого тега, существует вариант его написания, который устраивает абсолютно всех:
В этом случае тег будет распознан Яндексом, другие поисковики не обратят на него внимания, а проверка кода не будет воспринимать его, как ошибку.
Несмотря на явную пользу от возможности использовать тег noindex, Google так и не принял его и не создал ничего аналогичного.
Кстати о пользе – вот несколько конкретных ситуаций, в которых данный тег незаменим (не забываем, это актуально только для Яндекса):
- Когда нужно спрятать неуникальный текстовый контент.
- Закрыть от глаз поисковых роботов коды различных счетчиков.
- Убрать из индексации текст, который слишком часто меняется и его добавление в индекс является бессмысленным.
rel=«nofollow». Атрибут, который «работает» со всеми поисковиками
Для того чтобы дать роботу поисковика указание о том, что не нужно переходить и передавать вес по ссылке, существует атрибут тега <a> rel=«nofollow». Он является стандартизированным элементом HTML-кода и воспринимается абсолютно всеми поисковиками.
Причем его использование не делает ссылку невидимой, а лишь указывает, что по ней не нужно переходить и заниматься индексацией страницы, на которую она указывает.
Пример использования:
Использование rel=«nofollow» позволяет:
- Исключить передачу веса на «плохой» (с точки зрения поисковых систем) или нетематичный сайт, чтобы не «испортить» свою репутацию.
- Повлиять на перераспределение веса между присутствующими на странице ссылками.
- Управлять количеством учитываемых исходящих ссылок на страничке.
- Закрыть в комментариях ссылки, по которым не предполагается передача веса.
С использованием атрибута rel=«nofollow» важно не переусердствовать: если постоянно скрывать с его помощью ссылки, это может значительно повлиять на уровень доверия поисковиков к Вашему сайту.
Где еще используются noindex и nofollow
Также noindex и его постоянный спутник nofollow могут использоваться совершенно в ином виде – как значения атрибута content в составе мета-тега robots. Последний, в свою очередь, используется в HTML-коде страницы для указания поисковым ботам рекомендаций насчет индексации страничек и переходу по размещенным на них ссылкам.
Приведенный на скриншоте пример трактуется, как пожелание не выполнять индексацию содержимого странички и не анализировать ссылки, размещенные на ней. Наличие подобной конструкции в теле кода страниц может быть возможной причиной, по которой не индексируется сайт.
Основные выводы
Использование одного из вышеупомянутых элементов (или обоих сразу) зависит от условий, которые преследуются (сокрытие части текста, ссылки или всей страницы при использовании с мета-тегом robots).
Если нужно скрыть от робота Яндекса отдельный текст, noindex это сделает, но когда закрывается ссылка, noindex не поможет. В этом случае следует выбрать атрибут rel=«nofollow», не скрывающий анкор ссылки.
Теперь, когда Вы разобрались с особенностями применения <noindex> и rel=«nofollow», не забудьте поделиться этой важной информацией с теми, кто может в ней нуждаться!
Как использовать NOINDEX и NOFOLLOW?
Общаясь с клиентами и посещая тематические форумы по SEO не редко можно встретить вопрос, как, каким образом и в каких случаях использовать запрет индексации, «NOINDEX» и «NOFOLLOW»?
Прежде чем погрузиться в эту тему полностью уточним синтаксис, как объявляются эти правила.
«NOINDEX» можно объявить как HTML-тег:
<noindex>текст или код, запрещаемый для индексирования</noindex>
Но, написав код именно так, вы получите ошибку валидатора, потому что такой синтаксис не валиден. Если вы стремитесь к валидному коду, следует написать так:
<!-- noindex -->текст или код, запрещаемый для индексирования<!--/ noindex -->
Если вы хотите запретить индексировать всю страницу, можно использовать META-тег:
<meta name="robots" content="noindex"/>
Теперь рассмотрим синтаксис объявления «NOFOLLOW».
«NOFOLLOW» можно объявить как содержимое атрибута REL – (relationship) дословно-отношения. Атрибут указывает на отношение текущего документа к документу, на который ведёт ссылка, указанная в атрибуте «HREF» тега «A»:
<a href=”” rel="nofollow">анкор</a>
или как META-тег:
<meta name="robots" content="nofollow"/>
Как именно использовать эти инструкции, решать вам. А вот разницу давайте рассмотрим вместе.
<NOINDEX> и REL=»NOFOLLOW»
HTML-тег «NOINDEX» запрещает поисковой системе «Яндекс», только «Яндекс» поймёт эту инструкцию, и не будет индексировать выделенную этим тегом часть кода HTML-страницы. Только в Яндексе, потому что в поисковой системе «Google» возможность исключения части страницы не предусмотрена, что и указано в хелпе (помощи) поисковой системы.
Существует заблуждение, что если часть текста или кода страницы выделить тегом «NOINDEX», то Яндекс пропустит этот кусок кода при обходе роботом. Нет, не пропустит. Часть кода будет прочитана роботом и проанализирована поисковой системой, но не будет появляться и учитываться в поисковой выдаче системы. Чтобы лучше понять, почему так, поясним работу поисковых роботов, краулеров. Робот заходит на страницу вашего сайта и начинает её сканировать, читать. В какой-то момент обнаруживается объявление, открытие тега «NOINDEX». Так как страница роботом читается так же, как и людьми, слева направо и сверху вниз, разница в том, что робот читает не видимую часть, а код страницы, то краулер должен увидеть закрытие тега, то есть в какой точке страницы заканчивается отрывок кода, который вы запрещаете для индексации, значит, страница будет прочитана полностью. А значит, всё её содержимое будет известно поисковой системе. В связи с этим можно утверждать, что скрывать тегом «NOFOLLOW» часть неуникального текста – бессмысленно. Поисковая система поймёт и просчитает уникальность текста на вашей странице.
Встречается ещё один миф об этом теге. Если в тег «NOINDEX» поместить ссылку, то она не будет проиндексирована, а значит, не будет передавать свой «вес». Будет. Но в поисковую выдачу не попадёт текст, указанный в этой ссылке, сам анкор.
Какой смысл у тега «NOINDEX»?
Возникает резонный вопрос. А для чего нужен тег «NOINDEX»?
Тег «NOINDEX» предназначен для скрытия информации именно в поисковой выдаче, например, текст на странице посвящён описанию какой-либо одной характеристике товара, которая встречается у очень многих позиций вашего интернет-магазина, и вы в качестве примеров приводите описания этих товаров для сравнения и вам не нужно, чтобы в поиске всплывали эти второстепенные описания. Вот в этом случае ненужные подробные описания товаров и заключаются в тег «NOINDEX». Или ещё вариант, если на многих страницах повторяется один и тот же кусок текста. Конечно же, он может попасть в поисковую выдачу на всех этих страницах. Чтобы этого не произошло, используется тег «NOINDEX».
Как закрыть ссылку? Используем «NOFOLLOW».
С тегом «NOINDEX» разобрались. А для чего нужен «NOFOLLOW»?
Иногда нужно сослаться на информацию на другом интернет-ресурсе, но по каким-то причинам очень не хочется отдавать «вес» своей страницы. Вот в таких случаях и применяется атрибут отношения страницы-донора к акцептору (странице принимающей вес) – «NOFOLLOW».
Содержимое атрибута REL «NOFOLLOW» понимается обоими флагманами поиска, «Яндексом» и «Google». При указании «NOFOLLOW» роботы обойдут, прочитают и проанализируют сами ссылки, содержащиеся анкоры (текстовое содержание ссылки) и страницы, на которые идут ссылки, но вес вашей страницы передан не будет.
Синтаксис использования «NOINDEX» «NOFOLLOW» следующий:
Передаётся вес и индексируется анкор ссылки.
<a href=”http://reg50.ru/”> Поддержка и продвижение сайтов</a>
Вес страницы передаётся, но Яндекс не индексирует текстовое содержимое ссылки, анкор.
<!-- noindex --><a href=”http://reg50.ru/”> Поддержка и продвижение сайтов</a><!--/ noindex -->
Вес страницы не передаётся и Яндекс не индексирует текстовое содержимое ссылки, анкор.
<!-- noindex --><a href=”http://reg50.ru/” rel="nofollow"> Поддержка и продвижение сайтов</a><!--/ noindex -->
META-теги NOINDEX и NOFOLLOW
В начале статьи мы указали, что кроме тега «NOINDEX» и содержимого атрибута REL «NOFOLLOW» (rel=”nofollow”) есть ещё и META-теги с такими же именами. А зачем нужны они, если имеющегося функционала и так достаточно? Для чего используются<meta name="robots" content="noindex"/>
и<meta name="robots" content="nofollow"/>?
META-тег «NOINDEX», как и в случае с HTML-тегом запрещает индексирование только поисковой системе «Яндекс», всей страницы. То есть, в поисковую выдачу не попадёт только текстовая составляющая всей страницы, но страница будет прочтена и проанализирована, ссылки передадут «вес» страницам на которые ссылаются.
При наличии META-тега «NOFOLLOW» поисковые системы не будут индексировать ссылки, переходить по ним на акцепторы и передачи веса страниц не будет. Но, если на других страницах вашего сайта имеются такие же ссылки и они не закрыты META-тегом или атрибутом, то вес будет передан.
Итого
Теперь подведём итоги об использовании и значении «NOINDEX» и «NOFOLLOW».
Если нам нужно исключить какую-либо информацию из поисковой выдачи, используем «NOINDEX».
Если нам нужно сослаться на источник или материал на нашем сайте, но не нужно передавать вес страницы-донора, используем «NOFOLLOW».
При объявлении этих инструкций не забываем об описанных выше нюансах и принципах обработки этих команд поисковыми системами.
Успешного Вам продвижения!
#оптимизация сайта, #продвижение сайта, #техническая оптимизация
Что такое nofollow ссылка? Всё что вам нужно об этом знать
Тег rel=”nofollow” — один из самых простых HTML-тегов и один из самых важных для понимания, если вы занимаетесь SEO-оптимизацией. В этом руководстве вы узнаете о ссылках с атрибутом nofollow всё, что нужно, и даже больше.
Ссылки с атрибутом nofollow не новы. Они существуют уже 14 лет.
Если вам важен успех сайта в поисковых системах, то знать, когда стоит использовать ссылки с nofollow, а когда нет — не просто важно, а необходимо.
В этом руководстве я объясню, как появились ссылки nofollow, как они помогают в SEO и при правильном использовании защитят ваш сайт от фильтров Google.
Давайте сперва поговорим об основах.
Что такое nofollow ссылки?
Ссылки nofollow — это гиперссылки с атрибутом rel со значением “nofollow.”
Такие ссылки не влияют на ранжирование страниц на которые ведут, потому что Google не передаёт PageRank или анкорный текст через них. На самом деле, поисковый бот Google даже не посещает подобные страницы.
Рекомендуем к прочтению: Google PageRank не умер: почему он всё ещё имеет значение
Ссылки nofollow vs. dofollow ссылки
Ссылки с и без атрибута nofollow для среднестатистического пользователя выглядят одинаково.
Синий текст в этом предложении — это dofollow ссылка. А синий текст в этом предложении — nofollow. Разница между ними становится заметна только если покопаться в HTML-коде.
Ссылка dofollow:
<a href="https://ahrefs.com">Синий текст</a>
Ссылка nofollow:
<a href="https://ahrefs.com" rel="nofollow">синий текст</a>
Они идентичны, за исключением того, что во второй ссылке появляется тег rel=”nofollow”.
Можно сделать так, чтобы все ссылки на странице стали ссылками nofollow — просто добавьте тег в header страницы. Однако, тег rel=”nofollow” используется чаще, поскольку он позволяет добавлять атрибут nofollow только к определенным ссылкам на странице, а не ко всем.
Не уверены зачем это вообще нужно? Пришло время для небольшого экскурса в историю.
История возникновения
rel=”nofollow”В 2005 году компания Google представила тег nofollow, позиционируя его как инструмент для борьбы со спамом в комментариях.
Если вы блогер (или читатель блога), вам, вероятно, до боли знакомы люди, которые пытаются поднять позиции своих сайтов в поисковых системах через комментарии со ссылками, например, “Заглядывайте на мой сайт со скидками на лекарства”. Это называется спам в комментариях, и нам он тоже не нравится, поэтому мы тестируем новый тег, который его блокирует. С этого момента, когда Google видит атрибут (rel=“nofollow”) на гиперссылках, они не получают никакой пользы при ранжировании сайта в результатах поиска. Это не влияет на сайт, на котором был размещен этот самый комментарий, это всего лишь способ убедиться в том, что спамеры не получат выгоды от злоупотребления попыткой пропиариться в публичных пространствах типа комментариев в блоге, трекбеках и списках сайтов источников переходов.
Вскоре после этого Yahoo, Bing и несколько других поисковых систем также объявили о поддержке тега nofollow.
ВАЖНО
В разных поисковых системах определения тега nofollow немного отличаются. Вот таблица, демонстрирующая эти различияВ настоящее время WordPress, как и многие другие CMS, по умолчанию добавляет тег nofollow к ссылкам в комментариях. Так что даже если раньше вы никогда не слышали о ссылках с атрибутом nofollow, можете быть уверены, что любой спам-комментатор в вашем блоге, скорее всего, не получит никакой SEO-выгоды, несмотря на приложенные усилия.
Тем не менее, если вы переживаете, что к вашим комментариям не применяется атрибут nofollow, то вот простой способ это перепроверить:
- Найдите комментарий
- Щёлкните правой кнопкой мыши на ссылку
- Нажмите “Проверить”
- Посмотрите на выделенный HTML-код.
Если вы видите тег rel=nofollow, то ссылка nofollow, а если нет, то, соответственно, dofollow
Не хочется копаться в HTML-кодах? Установите расширение “nofollow” для Chrome, которое будет выделять все ссылки nofollow при просмотре веб-страниц.
Есть? Отлично. А теперь вернёмся к нашему уроку истории.
2009: Google ведёт борьбу с накруткой PageRank
PageRank передаётся по сайту через внутренние ссылки (ссылки с одной страницы сайта на другую).
Например, часть веса PageRank этой статьи перетекает на другие страницы этого сайта по гиперссылкам, подобным этой. И в целом, более высокий PageRank означает более высокое место при ранжировании. Гари Илш подтвердил эту информацию ещё несколько лет назад.
DYK that after 18 years we’re still using PageRank (and 100s of other signals) in ranking?
Wanna know how it works?https://t.co/CfOlxGauGF pic.twitter.com/3YJeNbXLml
— Gary “鯨理” Illyes (@methode) 9 February 2017
Однако, PageRank передаётся только по ссылкам dofollow.
Так было всегда, но с годами способ распределения PageRank между follow ссылками на странице изменился.
До 2009 года всё работало следующим образом:
Если у вас было три ссылки на странице, и одна из них — nofollow, то общий PageRank делился между двумя ссылками dofollow.
К сожалению, некоторые люди начали использовать это как возможность влиять на ранжирование путём наращивания PageRank для своих сайтов.
Другими словами, они перестали размещать ссылки на менее важные страницы, чтобы обеспечить максимальный приток PageRank на продающие страницы.
В 2009 году Google объявил об изменениях, направленных на пресечение подобной практики на корню.
Так что же всё-таки произойдет, если у вас будет страница с десятью “баллами” PageRank и десятью исходящими ссылками, где пять из них — nofollow? […] Первоначально пять ссылок без nofollow получили бы по два “балла” PageRank каждая […] А более года назад Google изменили это, и теперь PageRank проходит по ссылкам таким образом, что пять ссылок без nofollow получают только по одному значению PageRank.
Вот наглядный пример того, как это выглядело до и после:
ВАЖНО
PageRank — зверь очень загадочный и непростой. Прошло больше десяти лет с тех пор, как в Google внесли эти изменения. И хотя в последние годы от них не было слышно о каких-либо дальнейших изменениях, связанных с работой PageRank, вполне вероятно, что негласно они всё же происходили.
И хотя накрутка PageRank больше не практикуется, добавление атрибута nofollow к некоторым внутренними ссылками поможет с приоритетом сканирования, потому что, как было сказано ранее, поисковый бот Google даже не переходит по подобным ссылкам.
Поисковые боты не могут войти или зарегистрироваться на вашем сайте в качестве пользователя, поэтому нет смысла приглашать Google-бота переходить на страницы регистрации и авторизации. Использование тега nofollow даёт возможность боту Google сканировать другие более важные для вас страницы, которые и попадут в индекс Google.
Однако, это немного другая и более сложная тема, поэтому не будем углубляться в неё сегодня.
Рекомендуем к прочтению: Crawl budget for SEO: the ultimate reference guide
2013 год и далее: Google борется с проплаченными ссылками
Покупка и продажа ссылок, которые передают PageRank нарушают Руководство для вебмастеров.
Таким образом, все проплаченные ссылки должны быть nofollow.
Так было на протяжении многих лет, даже задолго до 2013 года.
Однако, судя по всему, с этого времени Google все больше беспокоится о влиянии проплаченных ссылок на алгоритм ранжирования.
Мэтт Каттс рассуждает о разоблачени таких ссылок в видео от 2013 года:
Подытожим: Google хочет поощрять заработанные, а не проплаченные ссылки.
Люди относятся к ссылкам как к рекомендациям от редакторов. Они ставят ссылки на что-то, что их вдохновляет. На что-то интересное. Они делятся ссылками с друзьями. Значит, есть причина, по которой они хотят выделить эту конкретную ссылку.
Проблема заключается в том, что некоторые “проплаченные” ссылки ничем не отличаются от заслуженных. Подумайте о том, какая разница между ссылками в проплаченном обзоре и независимом обзоре.
На первый взгляд обе ссылки будут выглядеть одинаково. Поэтому у Google должен быть способ обозначить “проплаченные” ссылки.
Думайте об этом в следующем ключе: Есть два способа получить Оскар:
Вариант #1: Жить ради актёрского искусства, постоянно оттачивать навыки, совершенствовать своё мастерство в течение долгих лет.
Вариант #2: Купить сразу 6 штук на Амазоне всего за $8.97…
Тег nofollow (на “проплаченных ссылках”) для Google — все равно Что ценник в $8.97 на обратной стороне вашего фальшивого Оскара: признак того, что вы не заслужили такую награду.
Помогают ли ссылки с атрибутом nofollow для SEO?
Давайте вкратце вспомним, что говорит Google о том, как они работают с nofollow-ссылками:
Google не передаёт PageRank и не учитывает анкорный текст по таким ссылкам.
Вроде всё понятно, пока вы не прочитаете предыдущее предложение:
Обычно мы не переходим по таким ссылкам. Это означает, что Google не передаёт по ним PageRank или анкорный текст.
Выражение “обычно” довольно размыто и абстрактно, как по мне. Оно подразумевает, что в некоторых случаях они всё же по таким ссылкам переходят.
Что это могут быть за случаи — остаётся только догадываться.
Некоторые считают, что все без исключения ссылки всё еще передают PageRank. Некоторые считают, что Google передаёт PageRank по ссылкам с атрибутом nofollow, но не по всем. Другие полагают, что некоторые слишком вчитываются в текст, который не менялся в течение добрых семи лет.
Ранее в этом году мы изучили 44,589 поисковых выдач на предмет корреляции между ранжированием в Google и различными атрибутами ссылок — одной из метрик было количество dofollow ссылок.
Вот что мы выяснили:
Корреляция обратных ссылок dofollow несколько слабее корреляции с общим количеством обратных ссылок.
Вот что на этот счёт говорит Тим:
Это может указывать на то, что Google ценит nofollow ссылки с “сильных” страниц больше, чем dofollow ссылки со “слабых” страниц. #ктознает
Но отнеситесь к этому скептически. Основной целью данного исследования не являлся анализ влияния ссылок nofollow vs. dofollow как таковой. Поэтому мы не изучали этот фактор в отдельности.
Но даже если предположить, что ссылки nofollow не оказывают прямого влияния на SEO, косвенно они все равно могут иметь влияние, поскольку:
1. Они помогают разнообразить ваш ссылочный профиль
Естественные ссылочные профили содержат разные ссылки.
Некоторые dofollow ссылки, а некоторые — nofollow. Это неизбежно, потому что кто-то обязательно будет ссылаться на вас через ссылки nofollow… как бы вы вам это не хотелось это изменить.
Более того, большинство обратных ссылок, которые вы получаете из следующих мест, автоматически будут ставиться в nofollow:
- Социальные сети (Facebook, Twitter, YouTube, и т.д.)
- Форумы (Reddit, Quora, и т.д.)
- Пресс-релизы
- Гостевые книги (привет, 1998 год!)
- Википедия (подсказка “почему”: любой может отредактировать страницу в Википедии)
- Пингбэки
- Каталоги
Короче говоря, если у веб-сайта есть только dofollow ссылки то это подозрительно.
Чтобы проверить количество dofollow ссылок и nofollow воспользуйтесь отчетом Overview в Сайт Эксплорере Ahrefs.
Site Explorer > введите любой домен, URL, или вложенную папку > Overview
Мы видим, что 85% ссылающихся доменов на блог Ahrefs это dofollow ссылки.
Хорошо это или плохо? Пока есть разнообразие, это хорошо.
Но если увидите 100% dofollow ссылок или около того, то это явный признак ссылочных манипуляций. Исходя из опыта, я бы сказал, что 60–90% — это вполне нормально, но этот диапазон не является каким-либо абсолютом оценивания. Если кажется, что что-то нечисто, копните немного глубже.
2. Они приводят трафик, а трафик даёт dofollow ссылки
Ссылки полезны не только для SEO. Это ещё и источник реферального трафика.
Вот почему мы так активны на Quora.
Если вы никогда ранее не слышали о Quora, это сайт вопросов и ответов, на котором каждый может ответить на вопросы, которые задают другие люди. Quora позволяет вставлять в ответах ссылки на соответствующие ресурсы.
Вот недавний ответ нашего менеджера по маркетингу Ребекки Бек, где она оставила ссылку на блог Ahrefs:
К сожалению, все исходящие ссылки на Quora являются nofollow. И эта ссылка прямо не повлияет на SEO.
Но вот что интересно:
Если мы проверим отчет по Backlinks (обратным ссылкам) в Сайт Эксплорере Ahrefs для ahrefs.com и поставим фильтр только на ссылки dofollow, то вот одна из многих обратных ссылок, которые мы увидим:
А теперь давайте рассмотрим ссылающуюся страницу (страницу, с которой идёт dofollow ссылка):
Единственная причина, по которой мы получили dofollow ссылку заключается в том, что автор этой статьи наткнулся на ответ Ребекки на Quora. Другими словами, nofollow ссылка косвенно привела к ссылке dofollow.
Поэтому стоит запомнить следующее: чтобы кто-то мог оставить на вас ссылку, следующие три события должны произойти в таком порядке::
- Люди должны увидеть ваш контент
- Он должен им понравиться
- Они рекомендуют его другим (через другие ссылки на сайте).
Поскольку ссылки с атрибутом nofollow могут помочь выполнить первый шаг, они часто являются катализаторами последующих ссылок.
3. Они могут защитить от санкций со стороны Google
Иногда есть справедливые основания для того, чтобы платить за ссылки.
Если сайт получает кучу трафика, есть смысл заказать рекламный пост на этом сайте. И если вы платите хорошие деньги за размещение, то вы, вероятно, захотите оставить обратную ссылку на ваш сайт, чтобы читатели могли легко на него выйти.
Проблема? Google утверждает, что использование платных ссылок противоречит Руководству для вебмастеров.
Учитывая сказанное, SEO-коммьюнити, как правило, делится на два лагеря:
- Те, кто считает, что Google может точно определить платные ссылки алгоритмически.
- Те, кто считает, что Google не может точно определить платные ссылки алгоритмически.
Кто из них прав — уже совсем другой вопрос.
Пока что предположим, что лагерь под номером 2 прав, и Google действительно с трудом определяет подобные ссылки. Это значит, что вы можете не беспокоиться и спокойно продавать и покупать ссылки на контент, который вам нравится, верно? Не спешите.
У Google есть инструмент, позволяющий любому пожаловаться на сайт, который покупает или продаёт ссылки..
Инструмент Google для жалоб на “проплаченные” ссылки.
Перевожу: возможно следует бояться не Google, а конкурентов.
Подумайте сами: Если конкурент видит, что вы хорошо ранжируетесь по его целевому запросу и использует такой инструмент, как Сайт Эксплорер Ahrefs для поиска ваших ссылок и находит dofollow ссылки вроде этой:
Пример “проплаченной” ссылки.
Почему бы ему на вас не пожаловаться?
Если благодаря этой жалобе команда, занимающейся веб-спамом в Google увидит сайт, найдёт проплаченные ссылки и применит ручные меры, то на одного конкурента в выдаче станет меньше.
И это подводит нас к следующему пункту:
Как проверить сайт на наличие проблем с nofollow ссылками
Рискованно иметь dofollow ссылки, которые противоречат Руководству для вебмастеров от Google.
То же самое относится и к исходящим ссылкам на вашем сайте, которые должны иметь атрибут nofollow.
Но дело не только в гневе Google (т.е. санкциях). Может случиться так, что некоторые внутренние ссылки nofollow будут ухудшать SEO.
Дальше мы научимся проводить беглый анализ, который поможет выявить и устранить любые подобные проблемы.
1. Ищите dofollow ссылки с вхождениями запросов в анкорных текстах
Чаще всего, ссылаясь на ваш сайт, люди не будут использовать точное вхождение запроса в анкорном тексте. Поэтому dofollow ссылки с точным вхождением обычно служат признаком манипуляций со ссылками.
Чтобы их найти, воспользуйтесь отчетом Anchors (Анкоры) в Сайт Эксплорере Ahrefs.
Site Explorer > введите свой домен > Anchors > фильтр dofollow
Здесь мы видим, что большинство анкоров этого сайта брендированные или общие (размытые с целью конфиденциальности), но есть также девятнадцать веб-сайтов (ссылающихся доменов), которые ссылаются, используя в качестве анкора фразу “кредиты”.
Если нажать на выпадающий список, а затем выбрать Referring domains (Ссылающиеся домены), мы сможем увидеть, что это за сайты.
Затем, если еще раз нажмем на выпадающий список, то увидим окружающий текст всех ссылок с каждого домена.
Вот некоторые рекомендации по работе с различными типами ссылок:
- Покупные ссылки на некачественных сайтах. Попросите убрать ссылку на ваш сайт (желательно) или добавить к ней атрибут nofollow. В противном случае, просто отклоните ссылки на уровне домена или страницы.
- Ссылки из блока об авторе в гостевых постах. Вы когда-нибудь оставляли ссылки с точным вхождением в блоке автора в гостевых постах? Попросите поставить ссылку на бренд, а не ключевое слово. А если хотите оставить ссылку с вхождением, то поставьте nofollow
- Ссылки c виджетов. Измените HTML вашего виджета так, чтобы ссылка была nofollow. Попросите того, кто уже встроил виджет, добавить к ссылке атрибут nofollow.
- “Сквозные” ссылки. Попросите поменять анкор с ключевого слова на бренд.
Обратите внимание, что точное вхождение ключевых слов в dofollow ссылках не всегда говорит о том, что сайт низкого качества или ссылка “проплачена”. Такие ссылки могут появляться и естественным образом.
Поэтому, прежде чем отклонять обратные ссылки или просить добавить к ним тег nofollow, стоит тщательно их изучить.
Если этого не делать, в конечном счёте можно нанести больше вреда, чем пользы.
СОВЕТ
Во вкладке с отчётами Anchors крупных сайтов может быть огромное количество различных анкоров.
Так что вот небольшая хитрость:
Сначала экспортируйте полный список всех анкоров.
Site Explorer > введите свой домен > Anchors > добавьте фильтр dofollow > Export > CSV
Затем скопируйте и вставьте их в Ahrefs Keywords Explorer пачками по 10000 за раз.
Нажмите на поиск, чтобы сгенерировать отчёт, затем отсортируйте по CPC от большего к меньшему.
Поскольку обычно анкоры с высоким CPC спамятся чаще, они будут вверху списка.
В отчёте Anchors в Сайт Эксплорере введите спамные анкоры в поисковую строку и исследуйте дальше.
2. Ищите проплаченные обратные ссылки follow
Обратные ссылки из проплаченных постов всегда должны иметь атрибут nofollow.
Потому что вы фактически платите за ссылку и она не должна передавать PageRank.
Чтобы найти такие ссылки, введите слово “sponsored” в поиск в отчёте Backlinks по вашему сайту, используя Сайт Эксплорер Ahrefs.
Site Explorer > Backlinks > поиск по слову “sponsored” > фильтр dofollow
Разберитесь с ними и попросите сделать такие ссылки nofollow.
3. Ищите на своём сайте исходящие ссылки с вхождениями ключевых слов
Знаете ли вы, что Forbes сделал все исходящие ссылки на сайте nofollow ещё в 2017 году?
Это произошло после того, как они обнаружили, что некоторые из их авторов продавали ссылки со своих статей. И поскольку авторов у них очень много, они решили, что проверять каждую ссылку будет очень долго, и воспользовались “ленивым” вариантом, чтобы не пропустить ни одной.
Как это относится к вам?
Если вы когда-либо публиковали гостевые публикации на своём сайте или у вас есть UGC контент, вы можете столкнуться с аналогичной проблемой.
Чтобы это выяснить, посмотрите на исходящие анкоры в Сайт Эксплорере Ahrefs.
Site Explorer > введите свой домен > Outgoing links > Anchors > фильтр dofollow
Ищите подозрительные слова и фразы, которые не ожидаете увидеть на своём сайте, и удаляйте или ставьте тег nofollow везде, где ссылка может показаться неестественной (например, анкоры с точными или частичными вхождениями ключевых слов в блоке автора в гостевых постах и т.д.).
Google лучше всех может объяснить почему это важно:
Если вы не можете или не хотите поручиться за содержание страниц, на которые ссылаетесь, например, комментарии или записи в “гостевой книге”, лучше сделать эти ссылки nofollow. Это может отбить у спамеров охоту использовать в своих корыстных целях ваш сайт, и поможет уберечь его от непреднамеренной передачи PageRank.
Нашли много анкоров?
Воспользуйтесь советом из пункта #1.
4. Ищите проплаченные follow ссылки на своём сайте
Вы когда-нибудь публиковали на сайте посты за деньги? А убедились, что ссылки обернуты в nofollow?
Если нет, то проверьте.
Для этого вбейте в строку Google <code>site:yourwebsite.com “sponsored post”</code>
Открывайте результаты один за другим и ищите эти самые ссылки.
Если вы установили расширение для Хрома nofollow, все ссылки с атрибутом nofollow на странице будут выделены, соответственно, спонсируемая ссылка тоже должна быть выделена. А если нет, то это dofollow ссылка.
Убедитесь в этом наверняка, проверив HTML код. Щёлкните правой кнопкой мыши по ссылке, нажмите “Inspect”и найдите тег <code>rel=”nofollow”<code>—HTML—
Если его нет, то это dofollow ссылка и вам следует добавить к ней тег nofollow.
5. Ищите внутренние nofollow ссылки
Ни одна внутренняя ссылка не должна быть nofollow если она не указывает на маловажные страницы или те, которые вы хотите исключить из индекса поисковых систем.
Чтобы найти внутренние nofollow ссылки, используйте отчёт Best by Links в Ahrefs Site Explorer.
Site Explorer > введите свой домен > Best by Links > переключите на Internal > сортировать по nofollow
Если вы видите страницы с внутренними nofollow ссылками, нажмите на цифру с их количеством, чтобы увидеть где они появились и разбирайтесь подробнее. Возможно, они там нужны (например, если есть внутренние nofollow ссылки на страницу входа в систему).
Однако, если очевидной причины для добавления атрибута nofollow нет, просто удалите его.
У нас тоже есть такое. По какой-то причине у нас появилась nofollow ссылка с одной записи в блоге на другую.
СОВЕТ
Для более детального аудита проблем, связанных с внутренними nofollow ссылками, запустите последнюю версию Ahrefs Site Audit.
Это не только даст вам на 100% свежие данные, но и предупредит о множестве специфических проблем, связанных с внутренними и внешними ссылками nofollow.
Пример проблем, которые могут возникнуть со внутренними ссылками nofollow в Ahrefs Site Audit
Узнайте, как настроить первое сканирование в Site Audit в этом видео:
Заключительные мысли
Ссылки nofollow играют огромную роль в SEO.
Надеюсь, это руководство вооружит вас знаниями, необходимыми для того, чтобы ссылки nofollow работали на вас… а не против вас.
Прежде чем закончить, хочу поделиться заключительной и, возможно, довольно очевидной мыслью: если вы активно создаёте ссылки на сайт, то стоит отдать предпочтение созданию dofollow ссылок. Через них передаётся PageRank и они оказывают непосредственное влияние на SEO.
В Site Explorer все наши отчёты по обратным ссылкам имеют фильтры dofollow и nofollow.
Так проще выбирать нужное при анализе ссылочных профилей конкурентов, или при создании списка для методики “skyscraper” и т.д.
Всё ещё остались вопросы? Спросите в комментариях ниже или в Twitter.
Перевел Дмитрий Попов, владелец Affilimarketer.com
Какие страницы на вашем сайте использовать с помощью noindex или nofollow? • Yoast
Михиэль ХеймансМихиэль был одним из наших первых сотрудников и раньше был партнером Yoast. Начните оптимизацию своего сайта с его статей!
Некоторые страницы вашего сайта служат определенной цели, но эта цель не состоит в ранжировании в поисковых системах и даже не в привлечении трафика на ваш сайт. Эти страницы должны быть там, как клей для других страниц, или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте.Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, пожалуйста, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Что такое noindex nofollow?
noindex означает, что веб-страница не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поиска. nofollow означает, что пауки поисковых систем не должны переходить по ссылкам на этой странице.Вы можете добавить эти значения в свой метатег robots. Мета-тег robots — это фрагмент кода в разделе заголовка веб-страницы. Он сообщает поисковым системам, как сканировать и индексировать ли страницу.
Наше полное руководство по метатегу robots — отличное чтение, если вы хотите немного глубже погрузиться в эту тему.
Вкратце:
- Метатег robots в большинстве случаев выглядит следующим образом:
- VALUE1 и VALUE2 установлены на индекс
, по умолчанию используется, что означает данная страница может быть проиндексирована поисковыми системами, и по ссылкам на этой странице можно переходить для сканирования страниц, на которые они ссылаются. - VALUE1 и VALUE2 могут быть установлены на
noindex, nofollowили другую комбинацию, например,index, nofollow.
Но пусть вас не пугает этот код. Yoast SEO поможет вам! Если вы хотите узнать, как noindex пост в WordPress супер-простым способом, вам следует прочитать этот пост: Как noindexировать пост в WordPress: простой способ.
Но когда какое значение использовать?
Страниц для установки noindex
Авторский архив в блоге одного автора
Если вы единственный, кто пишет для своего блога, ваши страницы авторов, вероятно, на 90% совпадают с домашней страницей вашего блога.Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете noindex его. К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как нельзя индексировать архив автора.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения, который вы не хотите индексировать.Например, в Yoast мы используем персонализированные страницы для наших продуктов, поскольку мы не являемся типичным интернет-магазином, продающим физические продукты. Таким образом, нам не нужно изображение продукта, фильтры, такие как размеры и технические характеристики, на вкладке рядом с описанием. Поэтому мы не индексируем обычные страницы продуктов, которые выводит WooCommerce, и используем наши собственные страницы. Действительно, у нас noindex тип сообщения о продукте.
Соответственно, мы видели решения для электронной коммерции, которые также добавляли такие характеристики, как размеры и вес, в качестве настраиваемого типа сообщений.Эти страницы считаются некачественным контентом. Вы поймете, что эти страницы бесполезны ни для посетителей, ни для Google, поэтому их тоже нужно держать подальше от страниц результатов поиска.
Страницы благодарности
Эта страница служит только для того, чтобы поблагодарить вашего клиента / подписчика на новостную рассылку / впервые комментирующего. Эти страницы обычно представляют собой страницы с тонким контентом, с опциями допродажи и обмена в социальных сетях, но они не представляют ценности для тех, кто использует Google для поиска полезной информации. Следовательно, этих страниц не должно быть на страницах результатов поиска.
Страницы администратора и входа в систему
Большинство страниц входа не должны находиться в Google. Но это так. Не допускайте попадания своего в индекс, добавив к нему noindex . Исключение составляют страницы входа в систему, которые обслуживают сообщество, например Dropbox или аналогичные службы. Просто спросите себя, стали бы вы гуглить одну из своих страниц входа, если бы вы не работали в своей компании. В противном случае можно с уверенностью сказать, что Google не нужно индексировать эти страницы входа. К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS не индексирует страницу входа на ваш сайт автоматически.
Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, вы ссылаетесь на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Таким образом, необходимо переходить по всем ссылкам, а мета-настройка роботов должна быть:
Yoast SEO следит за тем, чтобы для ваших внутренних поисковых страниц по умолчанию было установлено значение noindex.Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.
Только для разработчиков: если вы действительно хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Страниц для установки на nofollow
Для всех примеров, упомянутых выше, нет необходимости nofollow для всех ссылок на этих страницах.Вы не хотите, чтобы они отображались в результатах поиска, но хотите, чтобы Google переходил по ссылкам на странице. Теперь, когда должен , вы добавляете nofollow в метатег роботов?
Если вы установите для страницы значение nofollow с метатегом robots, ни одна из ссылок на этой странице не будет переходить. Google придумал nofollow, чтобы иметь возможность различать ссылки на ненадежный контент (или, позже, оплаченный, например, рекламу). На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по по любой ссылке .
Пример: если у вас есть страница со списком книг по SEO с избытком партнерских ссылок Amazon, они могут быть полезны для вашего сайта для ваших пользователей. Но я бы дал nofollow всю страницу, если на странице нет ничего важного. Однако вы могли бы проиндексировать его. Просто убедитесь, что вы правильно скрываете свои ссылки.
Одинарные ссылки Nofollow
Если у вас есть сообщение или страница с несколькими ссылками, вы можете помочь поисковым системам квалифицировать их.В настоящее время вы можете nofollow для одной ссылки или даже установить для нее спонсируемый или пользовательский контент. Добавление правильных атрибутов rel к вашей ссылке позволяет вам это сделать. Например, ссылка на рекламу будет выглядеть так: пример ссылки . С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
Заключение
Как мы видели, независимо от того, будет ли ссылка на noindex на страницу или на nofollow на ссылку сводится к двум вопросам: хотите ли вы, чтобы эта страница отображалась на страницах результатов поиска и , если поисковые системы переходят по ссылкам на эта страница? Например, для страниц с благодарностями или страниц входа в систему ответ на первый вопрос — «нет».Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
PS. Вы noindex пост или страницу, хотя не хотели? Не беспокойтесь, вы можете легко исправить случайную ошибку noindex !
Подробнее: Как не индексировать сообщение »
Как сказать Google не индексировать страницу в поиске
Индексирование как можно большего количества страниц вашего веб-сайта может быть очень заманчивым для маркетологов, которые пытаются повысить авторитет своей поисковой системы.
Но, хотя это правда, что публикация большего количества страниц, релевантных определенному ключевому слову (при условии, что они также высокого качества) улучшит ваш рейтинг по этому ключевому слову, иногда на самом деле больше пользы от сохранения определенных страниц на вашем веб-сайте из из индекс поисковой системы.
… Сказать что ?!
Оставайтесь с нами, ребята. В этом посте вы узнаете, почему вы можете захотеть удалить определенные веб-страницы из SERPS (страниц результатов поисковой системы), и как именно это сделать.
Почему вы хотите исключить определенные веб-страницы из результатов поискаВ ряде случаев вам может потребоваться исключить веб-страницу или ее часть из сканирования и индексации поисковой системой.
Для маркетологов одной из распространенных причин является предотвращение индексации дублированного контента (когда поисковыми системами индексируется несколько версий страницы, как в версии вашего контента для печати).
Еще один хороший пример? Страница благодарности (т.д., страница, на которую посетитель попадает после конверсии на одной из ваших целевых страниц). Обычно здесь посетитель получает доступ к тому предложению, которое обещала целевая страница, например, к ссылке на электронную книгу в формате PDF.
Вот как выглядит страница с благодарностью за нашу электронную книгу с советами по SEO, например:
Вы хотите, чтобы любой, кто попал на ваши страницы благодарности, попал туда, потому что они уже заполнили форму на целевой странице — , а не , потому что они нашли вашу страницу благодарности в поиске.
Почему нет? Потому что любой, кто найдет вашу страницу благодарности в поиске, может получить прямой доступ к вашим предложениям по привлечению потенциальных клиентов — без необходимости предоставлять вам свою информацию для прохождения через форму для сбора потенциальных клиентов. Любой маркетолог, который понимает ценность целевых страниц, понимает, насколько важно сначала привлечь этих посетителей в качестве потенциальных клиентов, прежде чем они смогут получить доступ к вашим предложениям.
Итог: Если ваши страницы с благодарностью можно легко обнаружить с помощью простого поиска в Google, возможно, вы оставляете на столе ценных потенциальных клиентов.
Что еще хуже, вы можете даже обнаружить, что некоторые из ваших страниц с самым высоким рейтингом для некоторых из ваших длиннохвостых ключевых слов могут быть вашими страницами благодарности — что означает, что вы можете приглашать сотни потенциальных клиентов в обход ваших форм для захвата лидов. Это довольно веская причина, по которой вы захотите удалить некоторые из своих веб-страниц из поисковой выдачи.
Итак, как вы делаете «деиндексирование» определенных страниц из поисковых систем? Вот два способа сделать это.
2 способа деиндексировать веб-страницу из поисковых системВариант №1: Добавить роботов.txt на свой сайт.
Используйте, если: вам нужен больший контроль над тем, что вы деиндексируете, и у вас есть необходимые технические ресурсы.
Один из способов удалить страницу из результатов поиска — добавить на сайт файл robots.txt. Преимущество использования этого метода заключается в том, что вы можете получить больший контроль над тем, что вы разрешаете индексировать ботам. Результат? Вы можете заранее исключить нежелательный контент из результатов поиска.
В файле robots.txt вы можете указать, хотите ли вы блокировать ботов с одной страницы, со всего каталога или даже с одного изображения или файла.Также есть возможность запретить сканирование вашего сайта, но при этом разрешить работу объявлений Google AdSense, если они у вас есть.
При этом из двух доступных вам вариантов этот требует самого технического кунг-фу. Чтобы узнать, как создать файл robots.txt, прочтите эту статью из Инструментов Google для веб-мастеров.
Клиенты HubSpot: Здесь вы можете узнать, как установить файл robots.txt на свой веб-сайт, а также узнать, как настроить содержимое роботов.txt здесь.
Если вам не нужен полный контроль над файлом robots.txt и вы ищете более простое и менее техническое решение, тогда этот второй вариант для вас.
Вариант № 2: Добавьте метатег «noindex» и / или метатег «nofollow».
Используйте, если: вам нужно более простое решение для деиндексации всей веб-страницы и / или деиндексации ссылок на всей веб-странице.
Использование метатега для предотвращения появления страницы в поисковой выдаче и / или в ссылках на странице — это просто и эффективно.Для этого требуется совсем немного технических ноу-хау — на самом деле, это просто копирование / вставка, если вы используете правильную систему управления контентом.
Теги, которые позволяют делать это, называются «noindex» и «nofollow». Прежде чем я перейду к тому, как добавлять эти теги, давайте определим их и проведем различие. В конце концов, это две совершенно разные директивы, и их можно использовать как по отдельности, так и вместе друг с другом.
Что такое тег noindex?
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что, даже если она может сканировать страницу, она не может добавить страницу в свой поисковый индекс.
Таким образом, любая страница с директивой noindex будет , а не попадет в поисковый индекс поисковой системы и, следовательно, не может отображаться на страницах результатов поисковой системы.
Что такое тег nofollow?
Когда вы добавляете на веб-страницу метатег «nofollow», запрещает поисковым системам сканировать ссылок на этой странице. Это также означает, что любой рейтинг, который страница имеет в поисковой выдаче, будет передан , а не страницам, на которые она ссылается.
Таким образом, на любой странице с директивой nofollow все ссылки будут игнорироваться Google и другими поисковыми системами.
Когда бы вы использовали «noindex» и «nofollow» по отдельности или вместе?
Как я сказал ранее, вы можете добавить директиву noindex либо отдельно, либо вместе с директивой nofollow. Вы также можете добавить директиву nofollow отдельно.
Добавьте только тег «noindex»: , если вы, , не хотите, чтобы поисковая система индексировала вашу веб-страницу в поиске, но вы, , хотите, чтобы переходила по ссылкам на этой странице, тем самым давая рейтинг на другие страницы, на которые ссылается ваша страница.
Платные целевые страницы — отличный тому пример. Вы не хотите, чтобы поисковые системы индексировали целевые страницы в поиске, за просмотр которых люди должны платить, но вы можете захотеть, чтобы страницы, на которые они ссылаются, извлекали выгоду из его авторитета.
Добавьте только тег «nofollow»: , когда вы хотите, чтобы поисковая система проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице.
Не так много примеров, когда вы добавляете тег «nofollow» на всю страницу без добавления тега «noindex».Когда вы выясняете, что делать на данной странице, больше возникает вопрос, добавлять ли ваш тег «noindex» с тегом «nofollow» или без него.
Добавьте теги «noindex» и «nofollow»: , если вы, , не хотите, чтобы поисковые системы индексировали веб-страницу в поиске, и вы не хотите, чтобы они переходили по ссылкам на этой странице.
Страницы с благодарностями — отличный пример такого рода ситуаций. Вы не хотите, чтобы поисковые системы индексировали вашу страницу с благодарностью, и вы также не хотите, чтобы они перешли по ссылке на ваше предложение и начали индексировать содержание этого предложения.
Как добавить метатег «noindex» и / или «nofollow»
Шаг 1: Скопируйте один из следующих тегов.
Для «noindex»:
Для «nofollow»:
Для noindex и nofollow:
Шаг 2: Добавьте тег в раздел
HTML-кода вашей страницы, a.к.а. заголовок страницы.Если вы являетесь клиентом HubSpot, это очень просто — щелкните здесь или прокрутите вниз, чтобы просмотреть инструкции, предназначенные для пользователей HubSpot.
Если вы , а не клиент HubSpot, , вам придется вручную вставить этот тег в код на своей веб-странице. Не волнуйтесь — это довольно просто. Вот как ты это делаешь.
Сначала откройте исходный код веб-страницы, которую вы пытаетесь деиндексировать. Затем вставьте полный тег в новую строку в разделе
HTML-кода вашей страницы, известном как заголовок страницы.Скриншоты ниже помогут вам в этом.Тег
обозначает начало вашего заголовка:Вот метатег для «noindex» и «nofollow», вставленный в заголовок:
И тег означает конец заголовка:
Бум! Это оно. Этот тег указывает поисковой системе развернуться и уйти, оставив страницу вне результатов поиска.
Клиенты HubSpot: Добавить метатеги noindex и nofollow стало еще проще.Все, что вам нужно сделать, это открыть инструмент HubSpot на странице, на которую вы хотите добавить эти теги, и выбрать вкладку «Настройки».
Затем прокрутите вниз до Advanced Options и нажмите «Edit Head HTML». В появившемся окне вставьте соответствующий фрагмент кода. В приведенном ниже примере я добавил теги «noindex» и «nofollow», поскольку это страница с благодарностью.
Нажми «Сохранить», и ты золотой.
Ta Da!
Вы только что волшебным образом удалили свою страницу из результатов поиска.Теперь вы можете снова начать собирать больше потерянных потенциальных клиентов.
Имейте в виду, что вы не увидите результаты мгновенно. Ваши изменения не вступят в силу до тех пор, пока поисковая система не просканирует вашу страницу в следующий раз. В зависимости от того, как часто вы обычно публикуете новые страницы на своем веб-сайте, на самом деле это может занять несколько недель. Чем чаще вы публикуете контент, тем чаще поисковые системы будут сканировать ваш сайт. Лучший способ отслеживать, как часто Google посещает ваш веб-сайт, — это просматривать статистику сканирования в Инструментах Google для веб-мастеров.
Итог: если вы заметили, что ваша страница все еще отображается в результатах поиска Google даже с тегом «noindex», вероятно, это потому, что Google не сканировал ваш сайт с тех пор, как вы добавили этот тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента Fetch as Google.
Также обратите внимание, что веб-сканеры некоторых поисковых систем могут интерпретировать эти директивы иначе, чем Google, поэтому возможно, что ваша страница все еще может отображаться в результатах других поисковых систем.Но для Google это будет нормально — как только он просканирует ваш сайт. Если вы хотите узнать, как поисковые системы сканируют, индексируют и обслуживают контент, пройдите наш курс по SEO.
Тем не менее, вы сможете спать немного легче, зная, что в конечном итоге вы сделали свой веб-сайт лучшим местом для маркетинга.
Какие еще советы вы можете дать по деиндексации веб-страниц и когда это будет полезно для маркетологов? Поделитесь своими мыслями в комментариях.
Страницы веб-роботов
О теге
роботовВ двух словах
Вы можете использовать специальный тег HTML, чтобы запретить роботам индексировать содержание страницы и / или не сканировать его на предмет наличия ссылок.
Например:
...
При использовании тега robots необходимо учитывать два важных момента:
- роботы могут игнорировать ваш тег. Особенно вредоносные роботы, которые сканируют Интернет на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами не обращаю внимания.
- директива NOFOLLOW применяется только к ссылкам на этой странице.Это вполне вероятно, что робот найдет такие же ссылки на других страница без NOFOLLOW (возможно, на каком-то другом сайте), и так далее попадает на вашу нежелательную страницу.
Не путайте это NOFOLLOW с rel = «nofollow» атрибут ссылки.
Детали
Как и /robots.txt, robots META tag является стандартом де-факто. Он возник в результате встречи «птиц пера» в 1996 году. распределенный семинар по индексированию, который был описан в заметках о совещании.
Тег META также описан в HTML Спецификация 4.01, Приложение B.4.1.
Остальная часть этой страницы дает обзор того, как использовать роботов. Теги на ваших страницах с некоторыми простыми рецептами. Чтобы узнать больше, см. Также FAQ.
Как написать метатег для роботов
Куда девать
Как и любой тег, он должен быть помещен в раздел HEAD HTML-кода. page, как в примере выше. Вы должны поместить его на каждую страницу своего сайт, потому что робот может найти глубокую ссылку на любой страницу на вашем сайте.
Что туда класть
Атрибут «ИМЯ» должен быть «РОБОТЫ».
Допустимые значения атрибута CONTENT: «ИНДЕКС», «НОИНДЕКС», «СЛЕДУЮЩИЕ», «НЕ СЛЕДУЕТ». Допускается несколько значений, разделенных запятыми, но очевидно, только некоторые комбинации имеют смысл. Если нет тег роботов, по умолчанию — «INDEX, FOLLOW», так что нет необходимости объяснять это. Остается:
Как скрыть веб-страницы с помощью noindex, nofollow и disallow
Это руководство по использованию noindex, nofollow и disallow пригодится, если ваши веб-страницы должны быть невидимы для поисковых систем, индексирующих роботов и сканеров веб-страниц.
Бывают случаи, когда вам нужно сделать свои веб-страницы невидимыми для поисковых систем, роботов-индексаторов и сканеров веб-страниц. В этих случаях вы можете подумать о добавлении «noindex», «nofollow» и / или «disallow» к атрибутам, тегам, метаданным и командам вашей веб-страницы; это включает в себя сайты, используемые для разработки, тестирования или подготовки, или если вы хотите ограничить доступ к страницам (например, вход на порталы или фотогалереи), или если страницы или определенные ссылки считаются избыточными, устаревшими, заархивированными или содержат тривиальный контент.
Это руководство поможет вам понять, как использовать «noindex», «nofollow» и / или «disallow» как часть процедуры обслуживания и управления вашим веб-сайтом.
Примеры синтаксиса
Индексные веб-страницы
В следующих примерах выделено несколько вариантов и комбинаций, доступных для тегов метаданных, которые могут быть добавлены в тег
.Этот тег метаданных сообщит всем поисковым системам, что нужно проиндексировать весь ваш веб-сайт; он также проиндексирует все ваши другие веб-страницы.
Этот тег метаданных даст указание поисковым системам не индексировать эту страницу в частности, но он будет сканировать остальные веб-страницы вашего веб-сайта.
Этот тег метаданных сообщает поисковым системам только проиндексировать эту страницу и прекратить сканирование дальше.
Этот тег метаданных предписывает поисковым системам не индексировать эту страницу и не сканировать ее дальше.
Предположим, вы хотите запретить роботу googlebot индексировать ваш веб-сайт; вы бы использовали этот синтаксис.
Связывание
Вы также можете использовать «nofollow» в определенных активных ссылках на страницах, которые вы, возможно, не хотите индексировать. Синтаксис ссылки nofollow похож на этот пример тега привязки ColdFusion cfm.
Robots.txt запретить
Вы также можете использовать файл robots.txt и поместить его в корневой каталог веб-сайта или в другой каталог, в зависимости от конфигурации вашего веб-сервера. Типичный файл robots.txt будет содержать всего несколько строк кода, который дает команду роботам с использованием так называемого протокола / стандарта исключения роботов. Приведенные ниже примеры синтаксиса иллюстрируют несколько способов реализации этой функции.
В этом примере все роботы не заходят на ваш сайт.
Пользовательский агент: * Disallow: /
В этом примере всем роботам дается команда держаться подальше от определенных каталогов.
Пользовательский агент: * Запретить: / резервное копирование / Запретить: / архив / Disallow: / cgi-mail /
В этом примере всем роботам предписывается избегать доступа к определенному файлу.
Пользовательский агент: * Запретить: /any-directory/any-file.htm
Вы можете указать несколько конкретных роботов, чтобы они не попадали в определенные или все области вашего веб-сайта. Ниже приведены несколько примеров.
Пользовательский агент: badbot Disallow: / private / Пользовательский агент: anybot-news Запретить: / Пользовательский агент: googlebot Disallow: /
Caveat
Хотя эти стратегии помогут вам в поисках управления доступом, их использование не гарантирует автоматически, что назначенные вами теги или команды noindex, nofollow и / или disallow будут соблюдаться всеми поисковыми системами. , пауки и ползунки. Для того, чтобы эти методы вступили в силу, может потребоваться время, особенно если страницы ранее были разрешены для индексации или отслеживания, а затем для них было установлено значение nofollow или noindex.Вы все еще можете видеть страницы в результатах поисковой системы, потому что их индексирование не обновлялось или обновлялось в последнее время.
Что такое теги NoIndex и как они влияют на SEO?
Директивы «Без индекса» предписывают поисковым системам исключать страницу из индекса, что делает ее непригодной для отображения в результатах поиска.
«Noindex» мета-роботы Теги
Самый распространенный способ запретить поисковым системам индексировать страницу — это включить тег Meta Robots в тег
HTML-страницы с помощью директивы noindex, как показано ниже:Примерно в 2007 году основные поисковые системы начали реализовывать поддержку директив noindex в тегах Meta Robots.Теги Meta Robots могут также включать другие директивы, такие как директива «follow» или «nofollow», которая предписывает поисковым системам сканировать или не сканировать ссылки, найденные на текущей странице.
Обычно веб-мастера используют директиву noindex для предотвращения индексации контента, не предназначенного для поисковых систем.
Некоторые распространенные варианты использования директив noindex:
- Страницы, содержащие конфиденциальную информацию
- Страницы корзины покупок или оформления заказа на веб-сайте электронной коммерции
- Альтернативные версии страниц для активных A / B или сплит-тестов
- «Промежуточные» (или незавершенные) версии страниц, еще не готовые для публичного использования
Кроме того, поисковые системы поддерживают директиву noindex, передаваемую через заголовки HTTP-ответа для данной страницы.Хотя этот подход менее распространен и его труднее определить с помощью обычных инструментов SEO, иногда инженерам или веб-мастерам проще включить его в зависимости от конфигурации их сервера.
Имя и значение для заголовка ответа «noindex» следующие:
X-Robots-Tag: noindex
Лучшие практики SEO для директив noindex
1. Избегайте использования «noindex» на ценных страницах.
Случайное включение тега или директивы noindex на ценную страницу может привести к тому, что эта страница будет удалена из индексов поисковой системы и перестанет получать весь органический трафик.
Например, если новая версия веб-сайта запущена, но теги «noindex», которые были включены для предотвращения индексации поисковыми системами новых версий страниц до того, как они были готовы, остались на месте, новая версия веб-сайта может немедленно перестать получать трафик. из поиска
2. Поймите, что «noindex» в конечном итоге рассматривается как «nofollow»
Веб-мастера часто используют теги Meta Robots или заголовки ответов, чтобы сигнализировать поисковым системам, что текущая страница не должна индексироваться, но ссылки на странице должны сканироваться, как со следующим тегом Meta Robots:
Обычно используется для страниц с разбивкой на страницы.Например, «noindex, follow» может применяться к спискам архивов блога, чтобы сами страницы архива не появлялись в результатах поиска, но позволяли поисковым системам сканировать, индексировать и оценивать сами сообщения блога.
Однако этот подход может работать не так, как предполагалось, поскольку Google объяснил, что их системы в конечном итоге обрабатывают директиву «noindex, follow» как «noindex, nofollow» — другими словами, они в конечном итоге перестанут сканировать ссылки на любой странице с директива noindex.Это может помешать вообще проиндексировать страницы назначения ссылок или снизить их PageRank или авторитет, снизив их рейтинг по релевантным ключевым словам.
3. Избегайте использования правил «noindex» в файлах Robots.txt
Хотя никогда официально не поддерживался, поисковые системы какое-то время соблюдали директивы noindex в правилах robots.txt. Поскольку правила robots.txt с подстановочными знаками могут применяться ко многим страницам одновременно без каких-либо изменений самих страниц, этот метод был предпочтен многими веб-мастерами.Google не рекомендует использовать файлы robots.txt для установки директив noindex и устаревшего кода, который поддерживал эти правила в сентябре 2019 года.
Хотите больше трафика? Деиндексируйте свои страницы. Вот почему.
Большинство людей беспокоятся о том, как заставить Google индексировать их страницы, а не деиндексировать их. Фактически, большинство людей стараются избежать деиндексации, как чумы.
Если вы пытаетесь повысить свой авторитет на страницах результатов поисковых систем, может возникнуть соблазн проиндексировать как можно больше страниц на вашем веб-сайте.И в большинстве случаев это работает.
Но это не всегда может помочь вам получить максимально возможное количество трафика.
Почему? Это правда, что публикация большого количества страниц, содержащих целевые ключевые слова, может помочь вам получить рейтинг по этим конкретным ключевым словам.
Однако на самом деле может быть более полезным для вашего рейтинга, если некоторые страницы вашего сайта не попадут в индекс поисковой системы.
Вместо этого он направляет трафик на релевантные страницы и предотвращает появление неважных страниц, когда пользователи ищут контент на вашем сайте с помощью Google.
Вот почему (и как) вам следует деиндексировать свои страницы, чтобы привлечь больше трафика.
Для начала давайте рассмотрим разницу между сканированием и индексированием.
Объяснение сканирования и индексирования
В мире SEO сканирование сайта означает следование по пути.
Под сканированием понимается поисковый робот (также известный как «паук»), который следует по вашим ссылкам и просматривает каждый дюйм вашего сайта.
Сканерымогут проверять HTML-код или гиперссылки.Они также могут извлекать данные с определенных веб-сайтов, что называется веб-парсингом.
Когда боты Google заходят на ваш сайт, чтобы сканировать, они переходят по другим связанным страницам, которые также есть на вашем сайте.
Затем боты используют эту информацию для предоставления поисковикам актуальных данных о ваших страницах. Они также используют его для создания алгоритмов ранжирования.
Это одна из причин, почему карты сайта так важны. Файлы Sitemap содержат все ссылки на вашем сайте, поэтому боты Google могут легко изучить ваши страницы.
Индексирование, с другой стороны, относится к процессу добавления определенных веб-страниц в индекс всех страниц, доступных для поиска в Google.
Если веб-страница проиндексирована, Google сможет сканировать и проиндексировать эту страницу. После деиндексации страницы Google больше не сможет ее проиндексировать.
По умолчанию индексируются все записи и страницы WordPress.
Хорошо проиндексировать релевантные страницы, потому что присутствие в Google может помочь вам заработать больше кликов и привлечь больше трафика, что приведет к увеличению доходов и увеличению узнаваемости бренда.
Но если вы позволите проиндексировать части вашего блога или веб-сайта, которые не являются жизненно важными, вы можете принести больше вреда, чем пользы.
Вот почему деиндексирование страниц может увеличить трафик.
Почему удаление страниц из результатов поиска может увеличить посещаемость
Вы можете подумать, что чрезмерно оптимизировать свой сайт невозможно.
Но это так.
Слишком много SEO может помешать вашему сайту занимать высокие позиции. Не переусердствуйте.
Есть много разных случаев, когда вам может потребоваться (или вы захотите) исключить веб-страницу (или, по крайней мере, ее часть) из индексации и сканирования поисковой системой.
Очевидная причина — предотвратить индексирование дублированного контента.
Дублированный контент означает, что существует более одной версии одной из ваших веб-страниц. Например, одна версия может быть удобной для печати, а другая — нет.
Обе версии не должны появляться в результатах поиска. Только один. Деиндексируйте версию для печати и сохраните индексируемую обычную страницу.
Еще один хороший пример страницы, которую вы, возможно, захотите деиндексировать, — это страница с благодарностью — страница, на которую посетители переходят после выполнения желаемого действия, такого как загрузка вашего программного обеспечения.
Обычно на этой странице посетитель сайта получает доступ ко всему, что вы ему обещали, в обмен на их действия, например, к электронной книге.
Вы хотите, чтобы люди попадали на ваши страницы с благодарностью только потому, что они выполнили действие, которое вы хотите, чтобы они предприняли, например, приобрели продукт или заполнили форму для потенциальных клиентов.
Не потому, что они нашли вашу страницу благодарности через поиск Google. Если они это сделают, они получат доступ к тому, что вы предлагаете, без необходимости выполнять желаемое действие.
Это не только бесплатная раздача вашего самого ценного контента, но также может испортить аналитику всего вашего сайта из-за неточных данных.
Если эти страницы проиндексированы, вы подумаете, что привлекаете больше потенциальных клиентов, чем есть на самом деле.
Если на ваших страницах благодарности есть ключевые слова с длинным хвостом, и вы не деиндексировали их, они могут иметь довольно высокий рейтинг, хотя в этом нет необходимости.
Что делает еще проще , чтобы их находило все больше и больше людей.
Вам также необходимо деиндексировать страницы профилей сообщества, распространяющие спам.
Удалить спам на страницах профилей сообщества
Бритни Мюллер из Moz недавно деиндексировала 75% веб-сайта Moz и добилась огромного успеха.
Большинство типов страниц, которые она деиндексировала? Страницы профилей сообщества, рассылающие спам.
Она заметила, что когда она выполняла поиск по сайту: moz.com, более 56% результатов приходилось на страницы профилей сообщества Moz.
Были тысячи этих страниц, которые ей нужно было деиндексировать.
Профили сообществаMoz работают по системе баллов. Пользователи зарабатывают больше очков, называемых MozPoints, за выполнение действий на сайте, например, за комментирование сообщений или публикацию блогов.
Поговорив с разработчиками, Бритни решила деиндексировать страницы профиля, набрав менее 200 баллов.
Мгновенно вырос органический трафик и рейтинг.
Деиндексируя страницы профилей сообщества таких пользователей, как этот, с небольшим количеством MozPoints, нерелевантные профили не попадают на страницы результатов поисковой системы.
Таким образом, только наиболее известные пользователи сообщества Moz с тоннами MozPoints, такие как Бритни, будут отображаться в поисковой выдаче.
Затем профили с наибольшим количеством комментариев и действий появляются, когда кто-то их ищет, так что на сайте легко найти влиятельных людей.
Если вы предлагаете профили сообщества на своем веб-сайте, следуйте примеру Moz и деиндексируйте профили, которые не принадлежат влиятельным или известным пользователям.
Вы можете подумать, что отключения «видимости для поисковых систем» в WordPress достаточно, чтобы уменьшить видимость для поисковых систем, но это не так.
На самом деле поисковые системы должны выполнить этот запрос.
Вот почему вам нужно деиндексировать их вручную, чтобы убедиться, что они не появятся на странице результатов. Во-первых, вы должны понять разницу между тегами noindex и nofollow.
Объяснение тегов Noindex и nofollow
Вы можете легко использовать метатег, чтобы страница не отображалась в поисковой выдаче.
Все, что вам нужно знать, это копировать и вставлять.
Теги, позволяющие удалять страницы, называются «noindex» и «nofollow».”
Прежде чем мы перейдем к тому, как вы можете добавлять эти теги, вам необходимо знать разницу между тем, как работают эти два тега.
Это два разных тега, но их можно использовать по отдельности или вместе.
Когда вы добавляете на страницу тег noindex, он сообщает поисковым системам, что, хотя они все еще могут сканировать страницу, они не могут добавить страницу в свой индекс.
Любая страница с директивой noindex не попадает в индекс поисковой системы, а это означает, что она не будет отображаться на страницах результатов поисковой системы.
Вот как выглядит тег noindex в HTML-коде сайта:
Когда вы добавляете на веб-страницу тег nofollow, он запрещает поисковым системам сканировать любые ссылки на странице.
Это означает, что любой рейтинг, присвоенный странице, не будет передан страницам, на которые она ссылается.
Тем не менее, любая страница с тегом nofollow может индексироваться при поиске. Вот как выглядит тег nofollow в коде веб-сайта:
Вы можете добавить тег noindex отдельно или с тегом nofollow.
Вы также можете добавить тег nofollow отдельно. Добавляемые вами теги будут зависеть от ваших целей для конкретной страницы.
Добавьте только тег noindex, если вы не хотите, чтобы поисковая система индексировала вашу веб-страницу в результатах поиска, но вы хотите, чтобы она продолжала переходить по ссылкам на этой странице.
Если у вас есть платные целевые страницы, было бы неплохо добавить к ним тег noindex.
Вы не хотите, чтобы поисковые системы приводили к ним посетителей, поскольку люди должны платить за их просмотр, но вы можете захотеть, чтобы связанные страницы извлекали выгоду из его авторитета.
Добавьте только тег nofollow, если вы хотите, чтобы поисковая система проиндексировала определенную страницу на страницах результатов, но вы не хотите, чтобы она переходила по ссылкам, которые есть у вас на этой конкретной странице.
Добавьте на страницу теги noindex и nofollow, если вы не хотите, чтобы поисковые системы индексировали страницу или могли переходить по ссылкам на ней.
Например, вы можете добавить теги noindex и nofollow к страницам благодарности.
Теперь, когда вы знаете, как работают теги noindex и nofollow, вот как добавить их на свой сайт.
Как добавить метатег «noindex» и / или «nofollow»
Если вы хотите добавить тег noindex и / или nofollow, первым делом нужно скопировать нужный тег.
Для тега noindex скопируйте следующий тег:
Для тега nofollow скопируйте следующий тег:
Для обоих тегов скопируйте следующий тег:
Добавить теги так же просто, как добавить тег, который вы скопировали, в раздел
HTML-кода вашей страницы.Он также известен как заголовок страницы.Просто откройте исходный код веб-страницы, которую вы хотите деиндексировать. Затем вставьте тег в новую строку в разделе
HTML.Вот как выглядит тег для noindex и nofollow в заголовке.
Имейте в виду, что тег обозначает конец заголовка. Никогда не вставляйте теги noindex или nofollow за пределами этой области.
Сохраните обновления кода, и все готово.Теперь поисковая система исключит вашу страницу из результатов поиска.
Вы можете сделать невозможным сканирование нескольких страниц, изменив файл robots.txt.
Что такое robots.txt и как получить к нему доступ?
Robots.txt — это просто текстовый файл, который веб-мастера могут создать, чтобы сообщить роботам поисковых систем, как именно они хотят сканировать свои страницы или переходить по ссылкам.
ФайлыRobots.txt просто указывают, разрешено или не разрешено определенное программное обеспечение для сканирования определенных частей веб-сайта.
Если вы хотите «nofollow» сразу нескольких веб-страниц, вы можете сделать это из одного места, открыв файл robots.txt на своем сайте.
Во-первых, неплохо сначала выяснить, есть ли на вашем сайте файл robots.txt. Чтобы в этом разобраться, перейдите на свой веб-сайт и добавьте файл robots.txt.
Это должно выглядеть примерно так: www.yoursitehere.com/robots.txt.
Вот как выглядит наш файл robots.txt.
На наш сайт добавлена задержка сканирования 10, из-за которой роботы поисковых систем не будут сканировать ваш сайт слишком часто.Это предотвращает перегрузку серверов.
Если по этому адресу ничего не появляется, значит, на вашем веб-сайте нет файла robots.txt. На Disney.com нет файла robots.txt.
Вместо пустой страницы вы также можете увидеть ошибку 404.
Вы можете создать файл robots.txt практически в любом текстовом редакторе. Чтобы узнать, как именно добавить его, прочтите это руководство.
Чистый костяк файла robots.txt должен выглядеть примерно так:
User-agent: *
Disallow: /
Затем вы можете добавить конечные URL-адреса всех страниц, сканирование которых не должно выполняться роботом Googlebot.
Вот несколько кодов robots.txt, которые могут вам понадобиться:
Разрешить индексирование всего:
User-agent: *
Disallow:
или
User-agent: *
Allow: /
Запретить индексирование:
Пользовательский агент: *
Запретить: /
Деиндексировать определенную папку:
User-agent: *
Disallow: / folder /
Запретить роботу Googlebot индексировать папку, кроме одного определенного файла в этой папке:
User-agent: Googlebot
Disallow: / folder1 /
Allow: / folder1 / myfile.html
Google и Bing позволяют людям использовать подстановочные знаки в файлах robots.txt.
Чтобы заблокировать доступ к URL-адресам, которые содержат специальный символ, например вопросительный знак, используйте следующий код:
User-agent: *
Disallow: / *?
Google также поддерживает использование noindex в файле robots.txt.
Для noindex из robots.txt используйте этот код:
User-agent: Googlebot
Disallow: / page-uno /
Noindex: / page-uno /
Вместо этого вы также можете добавить заголовок X-Robots-tag на определенную страницу.
Вот как выглядит тег X-Robots, запрещающий сканирование:
HTTP / 1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Этот тег можно использовать как для кодов nofollow, так и для кодов noindex.
Могут быть случаи, когда вы добавляли теги nofollow и / или noindex или изменяли файл robots.txt, но некоторые страницы по-прежнему отображаются в результатах поиска. Это нормально.
Вот как это исправить.
Почему ваши страницы все еще могут отображаться в поисковой выдаче (сначала)
Если ваши страницы по-прежнему отображаются в результатах поиска, возможно, это связано с тем, что Google не сканировал ваш веб-сайт с тех пор, как вы добавили тег.
Отправьте запрос на повторное сканирование вашего сайта в Google с помощью инструмента «Просмотреть как Google».
Просто введите URL своей страницы, нажмите, чтобы просмотреть результаты Fetch, и проверьте статус отправки URL.
Другая причина того, что ваши страницы все еще отображаются, заключается в том, что в вашем файле robots.txt могут быть ошибки.
Вы можете отредактировать или протестировать файл robots.txt с помощью инструмента robots.txt Tester. Выглядит это примерно так:
Никогда не используйте теги noindex вместе с тегом disallow в robots.текст.
Не использовать мета-индекс noindex И запретить в robots.txt
Когда вы используете метатег noindex для группы страниц, но по-прежнему запрещаете их использование в файле robots.txt, боты проигнорируют ваш метатег noindex.
Никогда не используйте оба тега одновременно. Также рекомендуется оставить карты сайта на некоторое время, чтобы их видели сканеры.
Когда Moz деиндексировал несколько страниц своего профиля сообщества, они оставили карту сайта профиля сообщества на месте на пару недель.
Было бы неплохо сделать то же самое.
Существует также возможность запретить сканирование вашего сайта вообще, при этом позволяя Google AdSense работать на страницах.
Подумайте об одной из своих страниц, например, о странице «Свяжитесь с нами» или даже о странице политики конфиденциальности. Вероятно, он связан с каждой страницей вашего веб-сайта либо в нижнем колонтитуле, либо в главном меню.
На эти страницы идет огромное количество ссылок. Вы же не хотите просто выбросить его. Особенно, когда он появляется прямо из главного меню или нижнего колонтитула.
Имея это в виду, вы никогда не должны включать страницу, которую вы блокируете, в robots.txt в карту сайта XML.
Не включать эти страницы в карты сайта XML
Если вы заблокируете страницу в файле robots.txt, но затем включите ее в карту сайта XML, вы просто дразните Google.
В карте сайта написано: «Вот блестящая страница, которую нужно проиндексировать, Google». Но затем ваш файл robots.txt удаляет эту страницу.
Вы должны поместить весь контент на своем сайте в две разные категории:
- Качественные поисковые лендинги
- Служебные страницы, которые полезны для пользователей, но не обязательно должны быть целевыми страницами поиска
Нет необходимости блокировать что-либо в первой категории в robots.текст. Этот контент также никогда не должен иметь тега noindex. Включите все эти страницы в карту сайта XML, несмотря ни на что.
Вы должны заблокировать все, что находится во второй категории, с помощью тегов noindex, nofollow или robots.txt. Вы действительно не хотите включать это содержание в карту сайта.
Google будет использовать все, что вы отправляете в свою карту сайта XML, чтобы понять, что должно или не должно быть важным для инструмента на вашем сайте.
Но то, что чего-то нет в вашей карте сайта, не означает, что Google полностью проигнорирует это.
Сделайте сайт: выполните поиск, чтобы увидеть все страницы, которые Google в настоящее время индексирует с вашего сайта, чтобы найти любые страницы, которые вы, возможно, пропустили или забыли.
Самые слабые страницы, которые Google все еще индексирует, будут перечислены последними на вашем сайте: search.
Вы также можете легко просмотреть количество отправленных и проиндексированных страниц в Инструментах Google для веб-мастеров.
Заключение
Большинство людей беспокоятся о том, как они могут индексировать свои страницы, а не деиндексировать их.
Но индексация слишком большого количества неправильных страниц может на самом деле повредить вашему общему рейтингу.
Для начала вы должны понять разницу между сканированием и индексированием.
Сканирование сайта означает сканирование ботов по всем ссылкам на каждой веб-странице, принадлежащей сайту.
Индексирование означает добавление страницы в индекс Google всех страниц, которые могут отображаться на страницах результатов Google.
Удаление ненужных страниц со страниц результатов, таких как страницы с благодарностями, может увеличить трафик, потому что Google будет сосредоточиваться только на ранжировании релевантных страниц, а не незначительных.
Удалите страницы профилей сообщества, содержащие спам, если они у вас есть. Moz деиндексировал страницы профилей сообщества, набравшие менее 200 баллов, и это быстро увеличило их посещаемость.
Затем выясните разницу между тегами noindex и nofollow.
Теги Noindex удаляют страницы из индекса Google, доступных для поиска. Теги Nofollow не позволяют Google сканировать ссылки на странице.
Вы можете использовать их вместе или по отдельности. Все, что вам нужно сделать, это добавить код для одного или каждого тега в HTML-заголовок вашей страницы.
Затем узнайте, как работает ваш файл robots.txt. Вы можете использовать эту страницу, чтобы заблокировать сканирование Google нескольких страниц одновременно.
Ваши страницы могут по-прежнему отображаться в поисковой выдаче, но используйте инструмент «Просмотреть как Google», чтобы решить эту проблему.
Не забудьте никогда не индексировать страницу и не разрешать ее в robots.txt. Кроме того, никогда не включайте страницы, заблокированные в файле robots.txt, в карту сайта XML.
Какие страницы вы собираетесь деиндексировать в первую очередь?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш веб-сайт
- SEO — разблокируйте огромное количество SEO-трафика.Смотрите реальные результаты.
- Контент-маркетинг — наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Paid Media — эффективные платные стратегии с четким ROI.
Заказать звонок
мета-тегов роботов | Как использовать мета-тег роботов для SEO
- WooRank
- Руководства по SEO
- Как использовать мета-теги роботов для SEO
Вы можете использовать метатег robots, чтобы контролировать, где и как Google и другие сканеры поисковых систем перемещаются по вашему сайту и передают ссылочный вес со страницы на страницу.Если это звучит знакомо для другого текстового файла на вашем веб-сайте, следите за новостями …
В этом руководстве мы рассмотрим
- Что такое метатег роботов и почему он важен
- Как вы используете метатег robots для SEO
- Преимущества использования метатега роботов
Метатег robots — это HTML-тег, который является тегом заголовка страницы и предоставляет инструкции ботам. Как и файл robots.txt, он сообщает сканерам поисковых систем, разрешено ли им индексировать страницу.
Чтобы найти метатег robots на странице, просто щелкните веб-страницу правой кнопкой мыши, выберите «Просмотреть исходный код» и затем выполните поиск для «robots». Это будет выглядеть примерно так:
В этом примере верхняя строка относится ко всем ботам поисковых систем, а 4 строки после нее относятся к конкретным пользовательским агентам.В этом конкретном примере метатег роботов сообщает поисковым системам не индексировать страницу. Однако боты могут свободно переходить по ссылкам, которые они находят на странице.
Метатег robots имеет значение, потому что он добавляет дополнительный уровень защиты к файлу robots.txt. Когда сканер переходит по внешней ссылке и попадает на одну из ваших страниц, он все равно может сканировать и индексировать эту страницу, поскольку он не видел файла robots.txt.
Мета-тег robots предотвращает сканирование и индексирование.
Метатег robots применяет только к странице, содержащей этот тег. Файлы robots.txt применяются ко всему вашему сайту.
Как работает метатег robots?
Как видите, тег состоит из двух частей: name = ”” и content = ”” .
Прочтите руководство по сканерам поисковых систем и сканированию, чтобы узнать больше о том, как они работают.
Часть имени определяет пользовательский агент бота, которого вы инструктируете, точно так же, как строка user-agent в файле robots.txt файл. В отличие от robots.txt, вы не используете подстановочный знак для включения всех ботов. Для этого вы просто напишите «роботы».
Отсюда и название мета-тега роботов.
Вторая часть, content = ”” — это место, где вы говорите ботам, что делать.
Какие существуют значения метатегов роботов?
Есть много разных значений, которые вы можете добавить в поле content в теге robots. Каждое из этих значений имеет свои особенности:
- Индекс: Указывает поисковым системам проиндексировать страницу.На первый взгляд это может показаться бессмысленным, поскольку по умолчанию используется «Индекс», но может быть полезно, если вы хотите, чтобы страницу проиндексировала только определенная группа поисковых систем.
- NoIndex: Указывает поисковым системам не индексировать страницу, чтобы она не отображалась в результатах поиска.
- NoImageIndex: Указывает поисковым системам не индексировать изображения на странице. Однако, если кто-то добавит это изображение в другое место в Интернете, Google все равно проиндексирует его и отобразит в результатах поиска.
- Нет: Это работает как ярлык для «noindex, nofollow».Он говорит поисковым системам игнорировать страницу и делать вид, что они никогда ее не видели.
- Follow: Указывает поисковым системам переходить по ссылкам, которые они находят на странице. Как и в случае с «Индексом», это статус по умолчанию, когда бот не находит применимый к нему метатег robots.
- NoFollow: Указывает поисковым системам вообще не переходить по ссылкам на странице. Вы также можете добавить это значение к отдельной ссылке.
- NoArchive: Указывает поисковым системам не показывать кэшированные копии страницы.
- NoCache: То же, что и «NoArchive», за исключением того, что используется MSN / Live.
- NoSnippet: Запрещает поисковым системам показывать фрагмент этой страницы в результатах поиска. Это также предотвращает кеширование страницы.
- NoTranslate: Указывает поисковым системам не предлагать переведенные версии страницы в результатах поиска.
- Unavailable_after: Указывает поисковым системам не отображать страницу в результатах поиска после определенной даты.
- NoYDir: Указывает поисковой системе не использовать Yahoo! Описание страницы каталога в поисковом фрагменте.
- NoODP: Запрещает поисковым системам использовать описание страницы из DMOZ в поисковом фрагменте. ODP — это сообщество, которое запускает и поддерживает каталог DMOZ.
Последние два значения — NoYDir и NoODP — сейчас не используются. Ни Yahoo! Каталог или DMOZ больше не существуют. Тем не менее, вы все еще можете видеть их в Интернете.
Немного усложняет тот факт, что не все поисковые системы поддерживают все значения. Итак, вот удобная таблица, которая разбивает это:
| Значение | Bing | Яндекс | |
|---|---|---|---|
| индекс | Есть | Есть | Есть |
| noindex | Есть | Есть | Есть |
| нет | Есть | Сомнение | Есть |
| noimageindex | Есть | № | № |
| следовать | Есть | Сомнение | Есть |
| nofollow | Есть | Есть | Есть |
| noarchive / nocache | Есть | Есть | Есть |
| № | Есть | № | № |
| notranslate | Есть | № | № |
| недоступен_после | Есть | № | № |
| лапша | № | № | № |
| нойдир | № | № | № |
Используя запятые, вы можете создавать многонаправленные метатеги вместо создания одного тега для каждой директивы.Фактически, вы будете видеть это довольно часто, поскольку многие метатеги роботов используют значения noindex, nofollow:
Обеспечение того, чтобы определенные малоценные страницы не попадали в индекс Google и результаты поиска, является такой же частью SEO, как и включение страниц в результаты поиска. Отсутствие индексации малоценных страниц может помочь увеличить так называемую «потребность в сканировании» вашего сайта, что может способствовать более частому сканированию вашего сайта.
Meta robots также добавляет дополнительный уровень защиты страниц, которые вы заблокировали через своих роботов.txt файл. Эти страницы все еще могут быть проиндексированы, если Google перейдет на них по внешней обратной ссылке. Отсутствие индексации страницы предотвратит это.
Использование метатега robots для предотвращения индексации страницы и перехода по ссылкам выглядит следующим образом:
Значения noindex и nofollow — два наиболее часто используемых значения в метатеге robots. Однако другие значения, перечисленные выше, также имеют значение SEO:
.NoImageIndex: Указывает поисковым системам не сканировать изображения на странице.
Нет: Это эквивалентно использованию «noindex, nofollow» в одном значении. Поисковые роботы не будут индексировать страницу и переходить по ссылкам.
NoArchive: Запретить поисковым системам показывать кешированную версию вашей страницы. Убедитесь, что люди всегда видят самую последнюю версию вашего контента. MSN / Live использует «NoCache» вместо «NoArchive».
NoSnippet: Это запрещает поисковым системам отображать фрагмент вашего сайта в результатах поиска. и не отображают кешированную версию страницы.
Если весь смысл SEO состоит в том, чтобы страницы попадали в результаты поиска, как, черт возьми, мета-роботы на странице помогают SEO?
Предотвращает индексирование и отображение любых личных файлов или папок в результатах поиска. Обычно рекомендуется не публиковать этот контент на своем сайте или защитить его паролем. Однако, если по какой-то причине вам нужно разместить его на своем сайте, метатег robots не позволит ему попасть в Google.
Это помогает поисковым системам более эффективно сканировать ваш сайт.У поисковых роботов ограниченный бюджет сканирования, поэтому теоретически они могут тратить все свое время на сканирование страниц, рейтинг которых вам не важен, и игнорировать самые важные из них. Блокирование индексации этих неважных файлов поможет поисковым роботам перейти на ваши более ценные страницы.
Если у вас есть страница, на которую набралось много ссылок, но вы не хотите, чтобы она индексировалась, используйте директиву follow, чтобы передать эту ссылочную массу на другие страницы вашего сайта.
Хотя никогда не рекомендуется публиковать конфиденциальную информацию на вашем веб-сайте, но иногда это случается.Блокировка этих URL-адресов через robots.txt говорит всем, кто его читает, что им следует взглянуть на эти страницы. Добавление «noindex» к метатегу robots убережет эту страницу от результатов поиска, не указав ее там, где ее можно найти.
Самая важная часть использования метатега robots — убедиться, что вы используете его правильно. Это не редкость, когда деиндексируется весь сайт, потому что кто-то случайно добавил тег noindex для роботов ко всему сайту. Поэтому понимание того, как работает метатег robots, абсолютно необходимо для SEO.
.