
Лицо туториал: Как Нарисовать Лицо (Основы + Пропорции) Уроки для Начинающих
Как нарисовать лицо человека: несколько самых простых правил | DesigNonstop
Как нарисовать лицо человека: несколько самых простых правил
66
Сегодня я вновь обращаюсь к творчеству талантливой французской художницы Стефани Валентин. Ранее я уже размещала на сайте ее замечательные видео уроки. Теперь же она даст несколько практических советов о том, как правильно нарисовать лицо человека. Какие пропорции и расстояния нужно соблюдать, чтобы вышел реалистичный рисунок. Все оказалось очень просто!
Рисунок 1.
Рисуем круг
Рисуем овал в форме яйца
Рисунок 2.
Рисуем вертикальную линию посередине овала
Рисуем горизонтальную линию посередине овала (Eyes)
На горизонтальной линии рисуем глаза. Расстояние между глазами — ширина глаза
Рисунок 3.
Рисуем «линию подбородка» (chin line) по низу овала
Рисуем «линию носа» (nose line) по низу круга
Рисуем «линию бровей» (eyebrow line). Расстояние между подбородком и носом такое же, как и между носом и верхней точкой бровей
Рисуем две вертикальные линии, определяющие ширину носа. Расстояние между линиями равно ширине глаза
Рисунок 4.
Делим расстояние между носом и подбородком на 4 равные части
Рисуем рот (Mouth) между 2 и 3 линиями
Рисунок 5.
Рисуем форму лица
Рисуем уши между «линией носа» и «линией глаз»
Рисуем волосы
Вот вы познакомились с тем, как можно легко и просто нарисовать сносный рисунок лица человека, основываясь лишь на простейших фигурах и расстояниях. А вы знаете, что применение математических закономерностей в дизайне — это целая наука, и что если использовать точно выверенные расстояния, то ваша работа будет выглядеть гармонично.
Более того, можно пойти чуть дальше и познакомиться с основными принципами создания гармоничной композиции в дизайне или узнать побольше про такие элементы композиции, как линия, пространство, фигура, размер.
Кстати, если вы хотите бесплатно скачать один из моих премиум вордпресс шаблонов, то теперь это можно сделать — здесь.
Summary
Article Name
Как нарисовать лицо человека: несколько самых простых правил
Description
Статья о том, как правильно нарисовать лицо человека. Какие пропорции и расстояния нужно соблюдать, чтобы вышел реалистичный рисунок.
Author
Natasha Klever
Publisher Name
Designonstop
Publisher Logo
аниме лицо туториал les moins chers
Quel que soit l’objet de votre désir, la plateforme d’AliExpress est une véritable mine d’or. Une envie de аниме лицо туториал? N’allez pas plus loin! Nous proposons des milliers de produits dans toutes les catégories de vente, afin de satisfaire toutes vos envies. Des grandes marques aux vendeurs plus originaux, du luxe à l’entrée de gamme, vous trouverez TOUT sur AliExpress, avec un service de livraison rapide et fiable, des modes de paiement sûrs et pratiques, quel que soit le montant et la quantité de votre commande.
Sans oublier les économies dont vous pouvez bénéficier grâce aux prix les plus bas du marché et à des remises sensationnelles. Votre аниме лицо туториал va faire envie à tous vos proches, croyez-nous!»
AliExpress compare pour vous les différents fournisseurs et toutes les marques en vous informant des prix et des promotions en vigueur. Notre site regroupe également des commentaires de véritables clients, chaque produit étant noté selon plusieurs critères commerciaux.
Alors n’attendez plus, offrez-vous votre/vos аниме лицо туториал! Qualité et petits prix garantis, il ne vous reste plus qu’à valider votre panier et à cliquer sur «Acheter maintenant». C’est simple comme bonjour. Et parce que nous adorons vous faire plaisir, nous avons même prévu des coupons pour rendre votre achat encore plus avantageux. Pensez à les récupérer pour obtenir ce(s) аниме лицо туториал à un prix imbattable.»
Chez AliExpress, rien ne nous rend plus fier que la lecture des retours positifs de notre chère clientèle, c’est pourquoi nous nous engageons à leur offrir le meilleur.
Как нарисовать лицо аниме девушки поэтапно 5 уроков
Уже нарисовал +73 Хочу нарисовать +73 Спасибо +1233
На этой странице мы собрали много пошаговых уроков, благодаря которым нарисовать лицо аниме девушки карандашом теперь под силу каждому. Все что нужно это бумага, карандаш и желание.
Было много уроков на срисовывание какой то определенной картинки, но не было ни одного урока который помог бы нарисовать свою неповторимую анимешку. И вот к приближающемся трёхсотому уроку я решила сделать специальный урок по которому вы сможете нарисовать лицо своей аниме девушке. Начинаем с контура лица. У многих проблема с формой лица, но я нашла способ как проще всего нарисовать лицо. Рисуем овал. От по краям овала отводим две линии в низ так чтобы они встретились.
Ну рот это не так уж трудно.Так же как вы уже знаете по мимо традиционных выражений эмоций(улыбка, слезы) аниме есть свои уникальные значки как капелька на голове героя характеризующая тупость происходящих событий или покраснение щёк так называемое смущение персонажа и др. И кстати «жевание носовых платочков «(расстройстве персонажа) на зовём это так, является уникальным для аниме и не где больше не встречается.
Переходим к самой трудной части урока- ВОЛОСЫ. Да, да очень трудно…но все же без волос анимешка выглядит глупо. Есть множество разновидностей волос. Некоторые представлены на фото. P.S. при создании своего персонажа можете взять данные прически
Вообще рисование волос начинается с челки. Рисуем каждую прядь как бы накладывая их друг на друга. Но заметьте, что волосы рисуются чуть выше контура головы.
Рисуем нижнюю часть волос. Можно было взять хвостики, я захотела длинных волос.
Оттеняем волосы любым карандашом. Ластиком создаем блеск на волосах. Рисунок готов. Теперь ваша очередь нарисовать свою анимешку. Интересно у кого получиться оригинальнее? урок подготовила moonflower. P.S. комментирую каждый рисунок.
Для этого урока используется карандаши В2 В4.
Рисуем основу-голову.Разделяем её на линии на которых мы будем рисовать глаза, нос, рот.
Рисуем и оттеняем глаза.С начало берём карандаш В2 оттеняем весь глаз кроме внутреннего круга. Потом берём В4 и рисуем зрачок, обводим контур всего глаза., обратите внимания с верху контур жирнее чем с низу.
Начинаем штриховать волосы.
Дальше штриховка идёт с боку лица.Наклон чуть круче чем на челке.Карандаш В4.
Дорисовываем волосы.Заметь те часть волос принадлежат челке и по этому у них наклон и штриховка другая. В4
Рисуем и штрихуем руку.С начало используем карандаш В2 для и оттеняем светлыми штрихами.Потом накладываем тени карандашом В4.
Как я рисую аниме лица: (можно рисовать в традишке или на графическом планшете). Для традишки — карандаш, ластик, любая ручка, (возможно линейка)
От руки рисуем круг
К даному кругу пририсовываем трапецию и треугольник
Карандашом (возможно при помощи линейки) рисуем крест, предварительно вычислив середину даной трапеции
Стираем все внутри овала головы, оставляя крест
Все прорисуем ручкой, стирая после карандаш
Добавляем волосы, шею, одежду и так далее
Раскрашиваем или оставляем черно белый рисунок
создаем собственный дипфейк в DeepFaceLab
DeepFake – технология синтеза изображения, основанная на искусственном интеллекте и используемая для замены элементов изображения на желаемые образы. Если вы не слышали о дипфейках, посмотрите нижеприведенный видеоролик, в котором актер Джим Мескимен читает стихотворение «Пожалейте бедного пародиста» в двадцати лицах знаменитостей.
Если вы не слышали о дипфейках, посмотрите нижеприведенный видеоролик, в котором актер Джим Мескимен читает стихотворение «Пожалейте бедного пародиста» в двадцати лицах знаменитостей.
Название технологии – объединение терминов «глубокое обучение» (англ. Deep Learning) и «подделка» (англ. Fake). В большинстве случаев в основе метода лежат генеративно-состязательные нейросети (GAN). Одна часть алгоритма учится на фотографиях объекта и создает изображение, буквально «состязаясь» со второй частью алгоритма, пока та не начнет путать копию с оригиналом.
В следующем видео показаны процессы, происходящие за кулисами обучения нейросети. Как пишет автор проекта Sham00K, на итоговое видео было потрачено более 250 часов работы. При этом использовались 1200 часов съемочных материалов и 300 тыс. изображений. Объем сгенерированных данных составил приблизительно 1 Тб.
Области применения технологии
Уже имеются целые YouTube- и Reddit-каналы c дипфейк-роликами. Технология DeepFake может применяться для самых разных целей.
Кинопроизводство. Производство фильмов сегодня – крайне затратный процесс с арендой камер, студий и оплатой работы актеров. Развитие технологии DeepFake позволит сократить затраты на съемочный процесс, монтаж и спецэффекты.
Развитие технологии DeepFake позволит сократить затраты на съемочный процесс, монтаж и спецэффекты.
Локализация рекламы. Достаточно записать один рекламный ролик со знаменитостью, после чего лицо знаменитости можно переносить в видео с местными актерами, произносящими рекламные слоганы на родном языке. Так можно добиться эффекта, как будто знаменитость говорит на языке страны дистрибуции продукта.
Виртуальная и дополненная реальности. Технология переноса мимики может применяться для создания цифровых двойников в играх и виртуальной (или дополненной) реальности. Источниками лица могут служить сами участники игры или иного пространства. Это повышает эмоциональное вовлечение в продукт.
Очевидно, что технология должна использоваться с особой осторожностью. Злоумышленниками могут преследоваться цели компрометирования личности или создания фейковых новостей. В начале октября 2019 года члены Комитета по разведке Сената США призвали крупные технологические компании разработать план для борьбы с дипфейками. Ранее, в сентябре этого года, Google создала специальный датасет дипфейков.
Отметим, что данная публикация подготовлена исключительно в исследовательских целях.
Создадим собственный DeepFake
Для синтеза дипфейка мы будем использовать популярную библиотеку DeepFaceLab. Библиотека стремительно развивается, сейчас существует несколько релизов:
- Windows (magnet-ссылка) – последний релиз, для загрузки требуется торрент-клиент.
- Google Colab (GitHub) – можно использовать удаленные вычислительные мощности.
- DeepFaceLab для Linux (GitHub)
Ниже описан базовый процесс создания дипфейка на примере Windows с использованием более старой версии программы, чем доступна сейчас.
Важно понимать, что на качество результата влияет множество свойств исходных файлов (разрешение и длительность видеофайлов, разнообразность мимики персонажей, освещение и т. д.). За любыми подробностями и деталями настроек перенаправляем к оригинальному репозиторию.
Системные требования для DeepFaceLab
Минимальные системные требования для работы с инструментом:
- ОС Windows 7 или выше (64 бит).
- Процессор с поддержкой SSE-инструкций.
- Оперативная память объемом не менее 2 Гб + файл подкачки.
- OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics).
Рекомендуемые системные требования:
- Процессор с поддержкой AVX-инструкций.

- Оперативная память объемом не менее 8 Гб.
- Видеокарта NVIDIA с объемом видеопамяти не менее 6 Гб.

Установка DeepFaceLab
Рассматриваемая сборка программы доступна на необновляемой торрент-раздаче (требуется VPN, форум трекера также пригодится в случае трудностей при установке и запуске, есть magnet-ссылка). Размер сборок – порядка 1 Гб.
Имеются три вида прекомпилированных сборок для ОС Windows:
DeepFaceLabCUDA9.2SSE– для видеокарт NVIDIA (вплоть до GTX1080) и любых 64-битных CPU.DeepFaceLabCUDA10.1AVX– для видеокарт NVIDIA (вплоть до RTX) и CPU с поддержкой AVX.DeepFaceLabOpenCLSSE– для видеокарт AMD/IntelHD и любых 64-битных CPU.
Алгоритм работы с DeepFaceLab
Предварительно договоримся о терминологии:
src(сокр. от англ. source) – лицо, которое будет использоваться для замены,dst(сокр. от англ. destination) – лицо, которое будет заменяться.
Архив сборки нужно распаковать как можно ближе к корню системного диска. После распаковки в каталоге DeepFaceLab вы найдете множество bat-файлов.
Местом хранения модели служит директория workspace.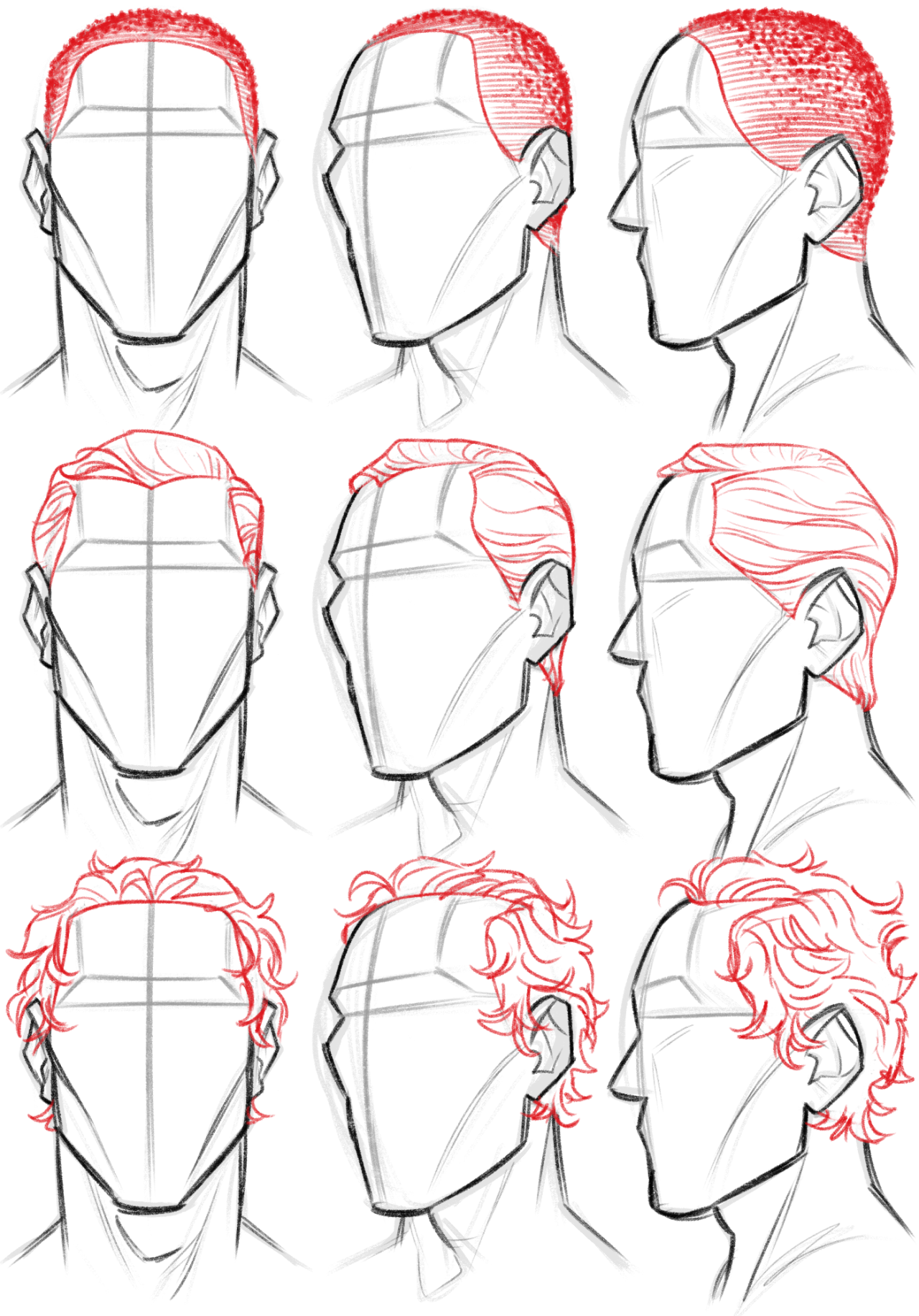 В ней будут содержаться видео, фотографии и файлы самой программы. Вы можете переименовывать каталог для сохранения резервных копий.
В ней будут содержаться видео, фотографии и файлы самой программы. Вы можете переименовывать каталог для сохранения резервных копий.
Как вы могли заметить, bat-файлы имеют в начале имени номер. Каждый номер соответствует определенному шагу выполнения алгоритма. Некоторые пункты опциональны. Пройдемся по этой последовательности.
1. Очистка рабочего каталога
На первом шаге запуском 1) clear workspace.bat и нажатием пробела очищаем лишнее содержимое папки workspace. Одновременно создаются необходимые директории.
Сразу после распаковки в workspace уже содержатся примеры видеороликов для теста. В соответствии с описанной терминологией вы можете заменить их видеофайлами с теми же названиями data_src и data_dst. Максимально поддерживаемое разрешение – 1080p. Приведенные в документации примеры расширений файлов: mp4, avi, mkv.
2. Извлечение кадров из видеофайла источника
На втором шаге извлекаем изображения из src-файла (2) extract images from video data_src.bat). Для этого запускаем bat-файл, получаем приглашение для указания кадровой частоты:
Enter FPS ( ?:help skip:fullfps ) :
Пропускаем пункт, нажав Enter, чтобы извлечь все кадры.
Output image format? ( jpg png ?:help skip:png ) : ?
В формат png файлы извлекаются без потерь качества, но на порядок медленнее и с большим объемом, чем в jpg. После задания настроек кадры извлекаются в каталог data_src.
3. Извлечение кадров сцены для переноса лица
При необходимости обрезаем видео с помощью 3.1) cut video (drop video on me).bat. Перетаскиваем файл data_dst поверх bat-файла. Указываем временные метки, номер дорожки (если их несколько), битрейт выходного файла. Появляется дополнительный файл с суффиксом _cut.
Запускаем 3.2) extract images from video data_dst FULL FPS.bat для извлечения кадров dst-сцены.
4. Составление выборки лиц источника
Теперь необходимо детектировать лица на src-кадрах. Получаемая выборка будет храниться по адресу workspace\data_src\aligned. Этому пункту соответствует множество bat-файлов, начинающихся с 4) data_src extract faces и имеющих разные дополнения после:
- Тип детектора лица:
MT– чуть более быстрый, но производит больше ложных лиц илиS3FD– рекомендованный, более точный, меньше ложных лиц. - Вариант использования GPU:
ALL(задействовать все видеокарты),Best(использовать лучшую). Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях. - Запись работы детекторов (
DEBUG). Каждый кадр с выделенными контурами лиц записывается по адресуworkspace\data_src\aligned_debug.
 Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях.
Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях.Пример вывода программы при запуске на видеокарте NVIDIA GeForce 940MX:
Performing 1st pass...
Running on GeForce 940MX. Recommended to close all programs using this device.
Using TensorFlow backend.
100%|################################################################################| 655/655 [03:32<00:00, 3.08it/s]
Performing 2nd pass...
Running on GeForce 940MX. Recommended to close all programs using this device.
Using TensorFlow backend.
100%|##########################################################################################################################################################| 655/655 [13:28<00:00, 1.23s/it]
Performing 3rd pass...
Running on CPU0.
Running on CPU1.
Running on CPU2.
Running on CPU3.
Running on CPU4.
Running on CPU5.
Running on CPU6.
Running on CPU7.
100%|#########################################################################################################################################################| 655/655 [00:05<00:00, 112.98it/s]
-------------------------
Images found: 655
Faces detected: 654
-------------------------
Done.
Bat-файл с параметром MANUAL применяется для ручного переизвлечения уже извлеченных лиц в случае ошибок на этапе 4.2.other) data_src util add landmarks debug images.bat.
4.1. Удаляем большие группы некорректных кадров
Запускаем 4., просматриваем результаты в обозревателе XnView MP (при закрытии запускайте этот bat-файл). 1) data_src check result.bat
1) data_src check result.bat
На этом этапе необходимо удалить большие группы некорректных кадров, чтобы далее не тратить на них вычислительный ресурс. К некорректным кадрам относятся все те, что не содержат четко различимого лица. Лицо также не должно быть закрыто предметом, волосами и пр. Не тратьте время на мелкие группы. Они будут удалены на следующем шаге.
4.2. Сортировка и удаление прочих некорректных кадров
Файлы с именами, начинающимися с 4.2, служат для сортировки и выявления групп некорректных кадров. Не закрывая обозреватель, последовательно запускайте bat-файлы и удаляйте группы некорректных кадров (обычно находятся в конце).
4.2.1) data_src sort by blur.batсортирует кадры по резкости, удаляем кадры с нечеткими лицами.4.2.2) data_src sort by similar histogram.batгруппирует кадры по содержанию, позволяет удалять ненужные лица группами.4.2.4) data_src sort by dissimilar histogram.batоставляет ближе к концу списка те изображения, у которых больше всего схожих (обычно это лица анфас). По усмотрению можно удалить часть конца списка, чтобы не проводить обучение на идентичных лицах.- Опционально:
4.2.5) data_src sort by face pitch.batсортирует лица так, чтобы в начале списка лицо смотрело вниз, а в конце – вверх. - Опционально:
4.2.5) data_src sort by face yaw.batсортирует лица по взгляду слева направо. - Рекомендованный пункт:
4.2.6) data_src sort by final.batделает финальную выборку целевого количества (по умолчанию 2000). Применяйте только после очистки набора предыдущими инструментами.
Дополнительные сортировочные bat-файлы, названия которых начинаются с 4.2.other, сортируют изображения по количеству черных пикселей, числу лиц в кадре (нужны кадры только с одним лицом) и т. д.
5. Составление выборки лиц принимающей сцены
Следующие операции с некоторыми отличиями идентичны выборке лиц источника. Главным отличием является то, что для принимающей сцены важно определить dst-лица во всех кадрах, содержащих лицо, даже мутные. Иначе в этих кадрах не будет произведено замены на источник.
Опция +manual fix позволяет вручную указать контуры лица на кадрах, где лицо не было определено. При этом в конце извлечения файлов открыто окно ручного исправления контуров. Элементы управления описаны вверху окна (вызываются клавишей H).
Запуск 5.1) data_dst check results debug.bat позволяет посмотреть все dst-кадры c наложенными поверх них предсказанными контурами лица. Удалите лица прочих, неосновных персонажей.
6. Тренировка
Обучение нейросети – самая времязатратная часть, длящаяся часы и сутки. Для тренировки необходимо выбрать одну из моделей. Выбор и качество результата определяются объемом памяти видеокарты:
- ≥ 512 Мб →
SAE. Наиболее гибкая модель с возможностью переносить стиль лица и освещение. - ≥ 2 Гб →
H64. Наименее требовательная модель. - ≥ 3 Гб →
h228. Аналогична моделиH64, но с лучшим разрешением. - ≥ 5 Гб →
DF– умная тренировка лиц, исключающая фон вокруг лица, илиLIAEF128– модель аналогичнаDF, но пытается морфировать исходное лицо в целевое, сохраняя черты исходного лица. - ≥ 6 Гб →
AVATAR– модель для управления чужим лицом, требуются квадратные видеоролики илиSAE HD– для самых последних видеокарт.
В руководстве не описана еще одна модель, присутствующая в наборе (Quick96), но она успешно запустилась при тренировке на видеокарте с 2 Гб памяти.
При первом запуске программа попросит указать параметры, применяемые при последующих запусках (при нажатии Enter используются значения по умолчанию). Большинство параметров понятно интуитивно, прочие – описаны в руководстве.
Отключите любые программы, использующие видеопамять. Если в процессе тренировки в консоли было выведено много текста, содержащего слова Memory Error, Allocation или OOM, то на вашем GPU модель не запустилась, и ее нужно урезать. Необходимо скорректировать опции моделей.
При корректных условиях параллельно с консолью откроется окно Training preview, в котором будет отображаться процесс обучения и кривая ошибки. Снижение кривой отражает прогресс тренировки. Кнопка p (английская раскладка) обновляет предпросмотр.
Процесс тренировки можно прерывать, нажимая Enter в окне Training preview, и запускать в любое время, модель будет продолжать обучаться с той же точки. Чем дольше длится тренировка, тем лучший результат мы получим.
7. Наложение лиц
Теперь у нас есть результат обучения. Необходимо совместить src-лица и кадры dst-сцены. Из списка bat-файлов выбираем ту модель, на которой происходила тренировка. Возможно несколько режимов наложения, по умолчанию используется метод Пуассона. В качестве остальных параметров для первой пробы можно использовать параметры по умолчанию (по нажатию Enter) и варьировать их, если вас не устроит результат наложения.
8. Склейка в видео
Следующие bat-файлы склеивают картинки в видео с той же частотой кадров и звуком, что и data_dst (поэтому файл должен оставаться в папке workspace). Итоговый файл будет сохранен под именем result. Готово! Ниже представлен пример, полученный для тестовых видео.
Если результат вас не удовлетворил, попробуйте разные опции наложения, либо продолжите тренировку для повышения четкости, используйте другую модель, другое видео с исходным лицом. О неописанных особенностях работы с библиотекой, прочих советах и хитростях читайте в оригинальном руководстве.
Планируете протестировать DeepFake? Делитесь результатами 😉
Как сделать deepfake-видео (Face Swap)
С момента появления дипфейки вызывали много вопросов касательно своей легитимности и опасности. По поводу этих вопросов ходят весьма противоречивые мнения: кто-то считает, что это всё невинная шалость и что в интернете должна быть свобода, кто-то, наоборот, видит в дипфейках лишь угрозу и считает, что их нужно полностью запретить. Кто же прав?
Чтобы это понять, нужно разобраться в том, что такое дипфейки и где они применяются. Павел Пармон, сотрудник аналитического отдела Falcongaze, изучил этот вопрос.
Что такое deepfake-видео (Face Swap) и как его сделать
Алина АлещенкоВы узнаете:
- Что такое дипфейки
- Как работают дипфейки
- Где применяются дипфейки
- Как создать свои дипфейки
- Как дипфейки влияют на жизнь людей
Читайте по теме: Несколько часов и никаких навыков программирования: как сделать дипфейк с синхронизацией губ
Что такое дипфейки?
Дипфейки — это синтетически произведённый медиаконтент, в котором оригинальный человек (тот, кто изначально находится на фото или видео) замещается другим человеком.
Началом истории дипфейков можно считать 19 век, когда разработали методики манипуляций над фото. Далее технология развивалась как в научных учреждениях, так и простыми энтузиастами интернет-сообщества. Сам термин «дипфейки» появился лишь в 2017 году, когда на RedditПопулярная на западе интернет-платформа для агрегации новостей и дискуссий. появилась ветка r/deepfakes. В основном там выкладывали контент либо порнографического содержания, в которых к актёрам «приклеивали» лица знаменитостей, либо видео, в которых лицо Николаса Кейджа вставляли в различные фильмы.
Как они работают?
В основе работы дипфейк-алгоритмов лежит нейросеть-автокодировщик. Позднее эту нейросеть улучшили генеративно-состязательной сетью.
Если рассматривать принцип создания дипфейков в общих чертах, то основные этапы в создании дипфейков следующие:
- Нейросети даётся большой массив данных;
- Она обрабатывает массив и изучает особенности лица и мимики;
- Как итог нейросеть учится воспроизводить лицо человека и её можно использовать для синтеза контента.
Где применяются дипфейки?
Практически везде, где можно использовать видео или звук. Фильмы, видео, записи голосов — во всех этих сферах применяются дипфейки.
Например, в фильме «Хан Соло. Звёздные войны: истории» с помощью дипфейк-технологий «омолодили» Хана Соло, которого играл Харрисон Форд.
Но основная доля использования дипфейков приходится на развлекательный или политический видеоконтент. Как правило, это либо создание видеомемов или видео категории «18+», в которые подставляют лица знаменитостей, либо манипуляции с видеозаписями политиков.
Как создать свои дипфейки?
На просторах сети есть куча программ, функция которых — создание дипфейков. С помощью них можно сделать многое, например, заменить лицо на видео на совершенно другого человека или изменить движения губ говорящего. А изменение движения губ и наложение новой звуковой дорожки с голосом говорящего (которую, кстати, тоже можно сделать с помощью отдельных дипфейк-программ) позволят сделать контент, в котором человек говорит совершенно другие вещи, нежели в оригинале.
Наиболее популярной программой для создания такого контента является DeepFaceLab. По заявлениям создателей продукта, с его помощью создаётся около 95% дипфейк-видеоконтента. Скачать программу можно с гитхаба.
Однако есть и другие программы, такие как:
У каждой программы есть свои нюансы, будь то необходимость технических знаний разного уровня или оплаты подписки. Но свою функцию они выполняют неплохо.
Теоретически можно создать свою нейросеть и её обучить. Однако такой вариант — дорогой, сложный и маловероятный в сегодняшних реалиях, поэтому в материале было решено опустить его как околомифический.
Как дипфейки влияют на жизнь людей?
В основном произведённый с помощью дипфейк-технологий контент не оказывает особого влияния на жизнь человека. Да, те же мемы развлекают и веселят людей, но какого-то вау-эффекта не будет.
Однако дипфейки, созданные в политических целях или нацеленные на конкретного человека, могут оказать ощутимый эффект на цель. Например, во время избирательной кампании в законодательное собрание Дели в феврале 2020 года партия Джаната использовала дипфейк-технологии для создания версии речи лидера на диалекте харьянви. В итоге изначально англоязычное видео с помощью технологии липсинкаСинхронизация движения губ со звуком.стало доступным для понимания людям, которые говорят на этом диалекте и английского не знают.
Аналогично можно и нанести ущерб. С помощью дипфейк-технологий можно обучить нейросеть воспроизводить необходимый текст голосом нужного человека, потом применить те же методы, что и в случае с индийской партии — и можно распространить видео, как человек говорит то, что нужно, без участия его самого.
Дипфейки также могут стать (и уже становятся) инструментом для мошенничества. Например, недавно мошенники запустили рекламу мастер-класса по якобы успешному использованию нейросетей и блокчейн-технологий. Всё это якобы разработано командой Dbrain, а на видео проект представляет Дмитрий Мацкевич. Только вот ни Dbrain, ни сам Дмитрий к этому проекту, который предлагает быстрые крупные доходы с минимальным капиталовложением, отношения никакого не имеют. Просто лицо спикера с помощью дипфейк-технологий «приклеили» к другому человеку, который уже от лица Дмитрия и рассказывал о проекте и зазывал людей на мастер-класс.
Или, например, случай летом 2019 года, когда мошенники применили дипфейк-технологии, чтобы сделать видео с участием Дмитрия Нагиева. В этом видео он предлагал поучаствовать в розыгрыше ценного приза. Перейдя на сайт розыгрыша, пользователи попадали на фишинговую страницу и, как правило, теряли деньги.
Вместо резюме
Дипфейки — это не добро, но и не зло. Это всего лишь инструмент. С его помощью можно как сделать смешной видеомем или донести важную информацию конкретной группе людей. Но в то же время можно нанести кому-то вред.
В итоге всё, как и всегда, зависит исключительно от того, к кому в руки этот инструмент попадёт. К сожалению, контролировать и регулировать распространение и использование подобных программ очень сложно.
Поэтому мы очень надеемся, что дипфейк-технологии подарят людям как можно больше полезных и весёлых видео и как можно меньше будут использоваться со злым умыслом.
Фото на обложке: shuttersv/ShutterstockИллюстрации предоставлены автором
Как делают deepfake-видео и почему лучше говорить «face swap»
Рассказываем о работе технологии face swap, создании известных сегодня deepfake-видео, как трансфер лиц поможет медиарынку и в каком направлении развивается эта область машинного обучения.
{«id»:94457,»url»:»https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap»,»title»:»\u041a\u0430\u043a \u0434\u0435\u043b\u0430\u044e\u0442 deepfake-\u0432\u0438\u0434\u0435\u043e \u0438 \u043f\u043e\u0447\u0435\u043c\u0443 \u043b\u0443\u0447\u0448\u0435 \u0433\u043e\u0432\u043e\u0440\u0438\u0442\u044c \u00abface swap\u00bb»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap&title=\u041a\u0430\u043a \u0434\u0435\u043b\u0430\u044e\u0442 deepfake-\u0432\u0438\u0434\u0435\u043e \u0438 \u043f\u043e\u0447\u0435\u043c\u0443 \u043b\u0443\u0447\u0448\u0435 \u0433\u043e\u0432\u043e\u0440\u0438\u0442\u044c \u00abface swap\u00bb»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap&text=\u041a\u0430\u043a \u0434\u0435\u043b\u0430\u044e\u0442 deepfake-\u0432\u0438\u0434\u0435\u043e \u0438 \u043f\u043e\u0447\u0435\u043c\u0443 \u043b\u0443\u0447\u0448\u0435 \u0433\u043e\u0432\u043e\u0440\u0438\u0442\u044c \u00abface swap\u00bb»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap&text=\u041a\u0430\u043a \u0434\u0435\u043b\u0430\u044e\u0442 deepfake-\u0432\u0438\u0434\u0435\u043e \u0438 \u043f\u043e\u0447\u0435\u043c\u0443 \u043b\u0443\u0447\u0448\u0435 \u0433\u043e\u0432\u043e\u0440\u0438\u0442\u044c \u00abface swap\u00bb»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0434\u0435\u043b\u0430\u044e\u0442 deepfake-\u0432\u0438\u0434\u0435\u043e \u0438 \u043f\u043e\u0447\u0435\u043c\u0443 \u043b\u0443\u0447\u0448\u0435 \u0433\u043e\u0432\u043e\u0440\u0438\u0442\u044c \u00abface swap\u00bb&body=https:\/\/vc.ru\/ml\/94457-kak-delayut-deepfake-video-i-pochemu-luchshe-govorit-face-swap»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
73 180 просмотров
Каждый день из многочисленных Telegram-каналов, изданий об ИТ прилетают новости о создании алгоритмов, работающих над преобразованием контента.
Недавно компания Тимура Бекмамбетова и разработчики робота «Вера» придумали технологию синтеза голосов знаменитостей. Учёные из МФТИ научили компьютер воспроизводить изображения, которые видит человек в данный момент, а компания OpenAI создала алгоритм, пишущий почти осмысленный текст на основе минимальных исходных данных.
Сложнее обстоят дела с трансфером человеческих лиц или тел на изображениях. Эту сферу начинают осваивать стартапы, которые создают продукты для оптимизации процессов производства контента: Dowell (проект компании Everypixel Group, Россия), Synthesia (Великобритания), а также RefaceAI — создатели приложений Doublicat и Reflect (Украина).
Есть несколько сервисов вроде Reflect, Doublicat или Morhine, которые работают в реальном времени со статичным форматами или GIF. Недавно китайские разработчики зашли на поле видеоформата и выпустили приложение Zao, которое встраивает лица пользователей в известные фильмы.
В остальном широкая аудитория остаётся непричастной к созданию такого контента и потребляет deepfake-видео, которые выпускают известные продакшн-студии или свободные художники на YouTube.
Технология face swap в открытом доступе: как она работает
Существуют разные архитектуры алгоритмов, которые переносят лица с видео на видео. Мы расскажем о нескольких самых распространённых.
Autoencoder и decoder
Метод перемещения лица, в основе которого — кодировщик и декодировщик. Работает это так:
- Два видео: донорское (откуда берём лицо) и целевое (куда мы его помещаем, ресивер, реципиент). На них размечаются границы лица. Эти видео с помощью нарезки кадров превращаются в набор фотографий. По ним и будет обучаться модель.
- Кодировщик сжимает изображения (грубо говоря, упрощает до последовательности чисел). Мы получаем latent face (непроявленное лицо), потом оно восстанавливается до оригинального изображения инструментом декодирования. Две нейросети обучаются кодировать и декодировать изображения так, чтобы после восстановления они были максимально похожими на оригинал.
- Кодировщик и для донорского, и для целевого видео один и тот же, благодаря чему изображения latent face у обоих видео схожи. А вот декодировщики разные, и здесь начинается магия: как только нейросети обучились, декодировщики меняют местами, донорское изображение восстанавливается с использованием декодировщика целевого видео. Получается, что лицо донорского видео пришивается к лицу целевого видео, перенимая выражение лица, мимику и эмоции реципиента.
Один из распространённых кодов для переноса лиц таким методом написал российский разработчик-энтузиаст Иван Перов. В его репозитории DeepFaceLab на GitHub есть подробнейшие руководства с комментариями, системные требования к оборудованию и программному обеспечению и даже видеоинструкция.
В подходе с использованием этого метода улучшить результат можно только вручную, корректируя базы данных перед обучением или на постпродакшене.
Поэтому всё чаще в архитектуру с кодировщиком и декодировщиком вплетаются генеративно-состязательные сети. Их суть заключается в соревновании генератора и дискриминатора (отсюда — GAN, Generative Adversarial Network, генеративно-состязательная сеть).
GAN
Генераторы учатся создавать наиболее реалистичную картинку, дискриминаторы — определять, какая из них сгенерированная, а какая оригинальная. По мере того как генераторы обучаются обманывать дискриминатор, изображение получается всё более реалистичным.
Таким образом, кодировщик и декодировщик отвечают за перенос изображения, а дискриминатор от генеративных сетей — за улучшение результата. По этой логике работает архитектура Face Swap GAN, созданная японским разработчиком Shaoanlu.
Ещё один подход — архитектуры с использованием нескольких генеративно-состязательных сетей. Каждая сеть отвечает за свою операцию, что сводит к минимуму количество этапов с применением ручного труда.
Чтобы обучить такую нейросеть, требуется несколько суток и мощный кластер видеокарт. Несмотря на это, такой подход является наиболее перспективным, потому что даёт лучший результат.
Одно из решений, созданных по этой технологии, — FSGAN, которое в скором времени обещает опубликовать в открытом доступе его создатель, израильский исследователь Юваль Ниркин.
Здесь одна нейросеть учится подгонять лицо донора под параметры целевого видео (поворот головы, наклон вбок или вперёд), вторая переносит черты лица, а третья делает image blending (слияние изображений), чтобы картинка была более реалистичной, без разрывов или артефактов.
Сегодня перенос лиц, если он выполняется исключительно алгоритмами, всё ещё заметен человеческом глазу: выдают либо визуальные артефакты, например мимика или положение глаз, либо непохожесть нового лица ни на реципиента, ни на донора — в результате получается третья сущность.
Гладкий трансфер лиц всё ещё обеспечивают не нейросети, а навыки в CGI (многие широко известные сегодня создатели deepfake-видео вроде Corridor Crew и Ctrl Shift Face правят работу алгоритмов вручную на постпродакшене или же совершают манипуляции перед самим обучением).
Чего не может нейросеть: препродакшн и постпродакшн
Как правится контент до или после обучения нейросети, нам рассказал моушн-дизайнер студии Clan Андрей Чаушеску, который несколько месяцев назад создал нашумевший в России ролик с актёром Михаилом Ефремовым в трейлере фильма «Ангелы Чарли».
Недавно он опубликовал новую работу, поместив в фильм «Великий Гэтсби» изображение актёра Сергея Бурунова, который обычно озвучивает Леонардо Ди Каприо в русском дубляже. Свои проекты Андрей делает в программе DeepFaceLab, поэтому мы будем говорить о правках, которые требуются для работы именно с этим алгоритмом.
На этапе препродакшена проводится работа с данными перед началом обучения нейросети. Когда два видео разложены на наборы кадров, нужно отсмотреть эти базы и обратить внимание на несколько моментов.
Во-первых, не все люди могут обменяться друг с другом лицами незаметно. Сегодня переносимая алгоритмами область — от бровей до подбородка и от уха до уха (то есть уши, лоб и волосы остаются в целевом видео родными). Поэтому на схожесть результата влияют влияют пол, возраст, цвет кожи и волос, а также комплекция и форма лица.
Некоторые студии, делая поддельные видео с известными артистами, ищут максимально похожих на них людей: ребята из Corridor нашли человека, очень похожего на Тома Круза, а актёр, играющий в ролике с Киану Ривзом, надел чёрный парик, чтобы воссоздать образ актера.
Ctrl Shift Face недавно выпустил три ролика с разными актёрами в одной сцене из фильма «Старикам здесь не место». Лучше всего получился Арнольд Шварценеггер, так как форма его головы больше всего подходит под форму актёра Хавьера Бардема, в отличие от Дефо и Ди Каприо.
Андрей Чаушеску
моушн-дизайнер
Слева направо: Леонардо Ди Каприо, Уиллем Дефо и Арнольд Шварценеггер в роли Хавьера Бардема
Во-вторых, если в донорском видео лицо всегда анфас, а в целевом голова поворачивается и виден профиль, алгоритм не перенесёт лицо корректно, потому что не знает, как выглядит человек в профиль. Так же обстоят дела с положением глаз, движением губ, мимикой и эмоциями (смех или плач): оба человека должны побывать в максимально совпадающем диапазоне ситуаций.
Часто нейросеть некорректно распознаёт глаза. Конечно, больше пользы принесёт подбор фотографий с нужным положением глаз, хорошо считываемой мимикой, но «обман» нейросети тоже может дать хороший результат.
Андрей Чаушеску
моушн-дизайнер
Перенос, полученный с помощью алгоритма в чистом виде (1 — целевое видео, 2 — результат). Видно, что модель неверно распознала положение глаз Ди Каприо: он смотрит в одну сторону, Бурунов — в другую
Перенос, полученный с использованием прорисовки глаз в базе данных (3 — целевое видео, 4 — результат). Положение глаз в финальном видео стало больше похоже на их положение в оригинале у Ди Каприо
После обучения то, что не углядели в начале, и то, в чём оказался бессилен алгоритм, докрашивается на постпродакшене. В ролике с Сергеем Буруновым Андрею пришлось столкнуться с проблемой разной формы лица двух актеров, которую он решал уже на завершающем этапе.
Самый быстрый способ сделать поддельный ролик — наложить лицо, не выходя за рамки головы человека с целевого видео (в данном случае — Ди Каприо). Лицо Бурунова шире, и, как мне кажется, сходство терялось, поэтому приходилось вручную масками прорисовывать его овал.
Андрей Чаушеску
моушн-дизайнер
Изображение Сергея Бурунова до и после прорисовки масками
Основная программа, которой я пользуюсь на постпродакшене, — Adobe After Effects. Я делаю цветокоррекцию, добавляю размытие для имитации движения камеры и шум для эффекта кинопленки.
Андрей Чаушеску
моушн-дизайнер
Изображение Сергея Бурунова до и после цветокоррекции
Отдельная история — работа с изображениями, в которых перед лицом есть искажающая преграда: скафандр, искривлённое зеркало или очки. Тут единственный выход — ПО вроде After Effects, Cinema 4D.
В них вручную создаётся текстура материала, которая затем ставится перед лицом, чтобы выглядело, как в оригинале. Из-за таких ограничений часто бывает, что очень классные сцены фильмов сложно использовать в deepfake-роликах.
Андрей Чаушеску
моушн-дизайнер
Для YouTube-формата, когда каждый вышедший ролик становится информационным поводом и предполагает вау-реакцию аудитории, такой подход применим. Видео можно долго шлифовать, а потом ещё отдельно описывать процесс, как это часто делают в Corridor Crew.
Очевидно, рынок сервисов для пользователей не предполагает какой-либо постпродакшн: результат нужен сейчас. Того же хочет и профессиональная индустрия (кино и реклама), которая руками переносить лица уже умеет, но сейчас фокусируется на удешевлении и автоматизации процесса.
Ролик с переносом лица Киану Ривза от Corridor
Спичрайтинг — про текст, face swap — про видео: как технология прорвёт рынок медиа
Монетизируется технология face swap по двум стандартным моделям. Для b2c-аудитории создаются развлекательные приложения вроде Zao или Doublicat. Для b2b-аудитории — продукты, которые используются для оптимизации продакшена, маркетинговых коммуникаций, персонализации брендированного контента или в игровой индустрии.
Среди них Dowell и RefaceAI, создатели которых рассказали, по какой логике работает их продукт и какую нишу на рынке они планируют освоить.
Dowell вырос в офисе компании Everypixel Group, которая занимается производством контента и создаёт продукты на основе искусственного интеллекта. Изучив рынок, создатели стартапа поняли, что развитие продуктов для пользователей и демонстрация deppfake-публикаций на YouTube не их путь, и проработали сценарии использования в киноиндустрии и маркетинге.
Один из кейсов они реализовали с BBDO — рекламный ролик с изображением генерального директора крупного автомобильного бренда, в съёмках которого этот человек не принимал непосредственного участия.
Жизненный цикл сервисов, которые позволяют заменять лица, ограничен: пользователи не будут заходить туда каждый день. Это инструмент, который позволяет «пошуметь», рассказать о себе, оседлать волну хайпа. Но мы решили сосредоточиться на решении бизнес-задач.
Во-первых, это маркетинговая коммуникация брендов с аудиторией. Мы создаём персонализированный контент и с помощью видео помогаем обрести их клиентам пользовательский опыт перед покупкой.
Во-вторых, решаем проблему увеличения доходности агентств, работающих со звёздами, их клиентов. Представьте, что Джордж Клуни одновременно снимается в голливудском фильме, рекламном ролике Nespresso и проводит презентацию нового Mercedes в Штутгарте.
В таком формате доступ к «телу» звёзд появится у тех брендов и организаций (вроде благотворительных фондов), которые никогда не могли себе позволить пригласить звезду живьём.
Мария Чмир
генеральный директор компании Dowell
На старте разработки продукта изучение алгоритмов, находящихся в открытом доступе, помогло нам понять логику работы, увидеть слабые места, но зависеть от чужого кода — тупиковый путь. Это чёрный ящик, содержание которого слабо можно представить, результат будет непредсказуемым.
В процессе собственных разработок мы одновременно проводили несколько исследований. Во-первых, искали влияние одних признаков и черт лица на другие, чтобы ими можно было управлять независимо друг от друга, по отдельности переносить глаза, нос, форму лица и губы.
Во-вторых, мы разделяем персону (черты лица) и контент (условия, в которой лицо появляется: свет, сюжет, эмоции), после чего можем взять персону и поместить её в те условия, которые нам нужны.
Чем страдают все открытые алгоритмы, так это маленьким разрешением переносимой области — 256 на 256 пикселей. Продакшн-студии работают с более качественными изображениями, и здесь мы задались целью увеличить область до стороны в 1024 пикселей.
Проблему можно решить, обучив нейросеть наращивать разрешение с 256 до 1024 пикселей и с помощью дискриминатора оценивать, насколько хорошо это получилось сделать. По такому же принципу можно «деблюрить» изображения, делая из размытых чёткие.
Александр Широносов
руководитель R&D компании Dowell
Это видео создано искусственным интеллектом. Использовались только общедоступные данные и материалы
Компания RefaceAI, которая исторически занималась анализом текста и генеративными сетями, связанными с автоматической конвертацией 2D-видео в 3D, video inpainting (удаление или восстановление фрагментов на видео), пришла к технологии face swap случайно, получив запрос на модификацию лиц от одной киностудии.
Тогда они решили протестировать гипотезу: насколько востребованным формат станет для обычных пользователей, и сделали сервис Reflect, который создаёт изображения с заменой лиц.
Сейчас команда выводит на рынок второе приложение, Doublicat. Оно будет менять лица на видео (в бета-версии перенос перенос в формате GIF).
В начале мы провели глубокий анализ всех общедоступных решений, которые используются для создания deepfake, поняли фундаментальные недостатки этих подходов, не позволяющие их масштабировать.
Сейчас для тренировки сетей мы используем существующие фреймворки машинного обучения (PyTorch), но основной код полностью создан нашей командой.
Использование нейросетей позволяет нам работать в более абстрактном пространстве, чем пиксели. Мы не занимаемся вырезанием и вставкой лиц, а затем гармонизацией результата, что требует много ручной работы.
Вместо этого мы натренировали нейросеть модифицировать минимальное количество визуальных признаков лица для максимальной схожести с нужным человеком. Она делает это на основе изученного пространства всех возможных черт лиц людей. Таким образом, необходимость в ручной постобработке видео сведена к минимуму.
Олесь Петрив
CTO компании RefaceAI
Что касается приоритетов в разработке трансфера лиц в видео, для b2c-модели сейчас главное — максимально быстрое обучение алгоритма, чтобы сервис работал в режиме реального времени и обучение не занимало долгие часы. Китайское приложение Zao сделало это первым.
Но его слабая сторона — алгоритм работает с предобученными данными. Пользователь не может загрузить свой контент, он загружает туда лишь изображение, которое переносится в заданный разработчиками набор видео.
B2b-решения больше сфокусированы на качестве переноса лиц, схожести результата и увеличении разрешения переносимой области, оптимизации времени обучения. Команда RefaceAI планирует, помимо лиц, освоить перенос туловища.
Часть нашей команды работает над технологией замены всего тела, это будет следующий большой шаг после замены лиц. Технология тоже основана на концепции генеративно-состязательных сетей. Но в замене тела больше вызовов и проблем, которые нужно решить, прежде чем выводить технологию в производство.
Дмитрий Швец
CBO компании RefaceAI
Дипфейки и антидоты
Синхронно с развитием технологии встаёт вопрос о риске распространения ложных новостей и их определения. Разработчики RefaceAI одновременно со своими сервисами создают антидоты, помогающие распознать сгенерированные изображения и видео.
А Facebook недавно объявила конкурс на разработку технологии детекции поддельных видео с призовым фондом $10 млн, что предвосхищает появление большого количества новых методов.
Сейчас подделку можно определить по тем частям тела человека, перенос которых не предусмотрен технологией: уши, волосы, лоб. Если эти части тела особенно выдающиеся, определить можно и невооруженным взглядом, но есть базы данных для распознавания ушей. Но очевидно, что когда-то их тоже станут переносить, и этот способ перестанет работать.
Ещё один распространённый инструмент — бинарный классификатор, который учится определять реальные и поддельные изображения. Однако сама логика работы генеративных сетей подразумевает, что такой классификатор обречён оставаться обманутым.
Интересный подход использовал учёный Хао Ли: у каждого человека есть индивидуальные паттерны мимики и движения лица, которые при переносе наследуются от реципиента. Таким образом можно математическим методом вычислить, что лицо донора ведёт себя неестественным для него образом.
Face swap vs deep fake
У технологии трансфера лиц пока не устоялось одно название, и во многих источниках в пределах одной и той же публикации её могут называть и так, и так (этот текст — не исключение).
Термин «face swap», предположительно, пришёл в язык в 2000-х годах с появлением в графических редакторах функций, которые позволяли пользователям трансформировать лица на изображениях (иногда употребляли термины «face replacement», «face morphing»), а также из научных работ.
Но сфера применения была очень узкой, поэтому в 2017 году, когда интернет взорвали ложные порноролики с участием известных артистов, технологию стали называть deepfake — по нику пользователя Reddit, который эти ролики публиковал. И это слово легко подвинуло термин, которому на тот момент было полтора десятка лет, и стало употребляться наравне с ним.
Противостояние двух определений заключается в том, что первое удобнее для тех, кто стремится вывести технологию в правовое поле и адаптировать к современным реалиям коммуникации. В конце концов спичрайтинг — это тоже своего рода подделка, но никто его так не называет.
Второе — эмоциональнее и хлестче, но оно мешает отделиться от порно, утечек, подделок и прочих ужасов сингулярности. Какое из них победит — кто знает.
Painter Tutorial — базовые понятия, кисти, покраска
Этот урок запланирован как вводный курс в Corel Painter, «с чего начать», если можно так выразиться. Тем не менее, я буду предполагать у вас начиличе некоторых простейших знаний компьютерной графики, поскольку этот урок запланирован не как инструкция, а больше как руководство для людей, помогающее найти общий язык с Пейнтером, начать в нем работать и получать удовольствие, и находить свои собственные способы его использования.Тем не менее, мне так же стоит сказать, что Painter предназначен для работы с планшетом. Если же вы используете мышь, я действительно считаю, что другие программы, особенно Photoshop, являются лучшей альтернативой. Painter воспроизводит естественные техники живописи, а его название намекает, что больше всего он подходит для рисования, и, как я думаю, его лучше всего рассматривать (до известной степени) как очень простую программу: ничего сложного, просто куча кистей, чтобы помочь вам рисовать так, как вы бы это делали «живыми» материалами.
Прежде всего, в Painter’e существует несколько важных особенностей, которые могут отличаться по сравнению с другими редакторами.
Другая важная деталь, с которой можно поиграть — Brush Creator, который позволяет изменять или создавать собственные кисти, подходящие вашему стилю
Несмотря на то, что набор кистей и техник в Painter’e может показаться немного устрашаюшим, они воспроизводят все традиционные методы рисования, так что, если вы знаете, какого типа ощущения и общий вид могут быть достигнуты с помощью масла, акрила, и т.д., вы можете просто выбрать кисть, которая соответствует тому, что вы хотите.
Далее следует быстрый обзор некоторых кистей, которые я использую чаще остальных.
Tinting Brushes
Самые
мои любимые и наиболее часто используемые кисти — размер и
непрозрачность изменяются в зависимости от давления, они также хорошо
смешиваются, при этом получаются симпатичные градиенты, не выглядящие
слишком цифровыми или аэрографичными.
Oils and Acrylics (Масло и Акрил)
Это
чрезвычайно трудные для понимания кисти с переменной непрозрачностью.
Лессировочные масляные или акриловые кисти ведут себя по-разному, но и
множество кистей в этой категории могут выдавать хорошие,
традиционно-выглядящие мазки.
Contes, Pastels and Chalks (Пастель и Мелки)
Для
тех, кто не знаком с традиционными методами рисования, Contes — это
высококачественная пастель. Таким образом эти кисти и используются, при
этом достигается эффект зернистости.
Pens and Pencils (Ручки и Карандаши)
Предназначенные
прежде всего для черчения и графики, они, тем не менее, имеют хорошие,
непрерывные кисти, требующие одинаковой непрозрачности, такой как в цел-шейдинге c минимальной подгонкой под пользователя.
Digital Watercolour (Цифровая акварель)
Акварельные
кисти немного отличаются от других тем, что для них требуется
специальный слой, а кисти категории Digital Watercolour ведут себя, как
обычные кисти. Они слегка прозрачные, но, возможно, ближе к гуаши, чем к
акварели. Подсказка: Установите Wet Fringe на 0%, чтобы убрать края и
получить мягкое размытие.
Palette Knifes (Мастихины)
Эта категория кистей по большей части используется для получения особых текстур, таких, как длинный мех, к примеру.
Airbrushes (Аэрографы)
Используются
в основном для оттенков и, в некоторых случаях, для добавления шумов
или зернистости вашему рисунку. Я использую эти кисти больше для
наложения последних штрихов, чем для фактического изменения тона.
Когда дело доходит непосредственно до рисования, использование Painter’a состоит вот в чем: для меня рисование, это по большей части поиск той, кисти, которая будет работать за меня, и рисование с ее помощью.
Это быстрый пример того, что я имел в виду, я использовал всего 4 кисти для этого быстрого рисунка, но я могу просто достигнуть весьма похожих результатов, используя другие кисти, например из подраздела Цифровая акварель или Акрил. Помните, что Brush Creator позволяет вам видоизменять их, так что пожалуйста — видоизменяйте.
1. Прежде всего я рисую скетч, используя Grainy Cover Pencil.
2. Обвожу скетч, используя Smooth Round Pen.
3. Теперь я создаю слой ниже и закрашиваю рисунок основными цветами, используя Basic Round Tint Brush. В обычной ситуации я держу различные части рисунка на отдельных слоях, чтобы было их проще редактировать, но для простого примера использую один слой.
4. На следующем шаге я просто рисую некоторые тени и блики — тут я использую только Soft Grainy Round Tinting Brush, меняя размер по необходимости.
5. Добавляю больше деталей и бликов, используя непрозрачную кисть, здесь я взял detail Oil Brush.
6. Заканчиваю с помощью Dodge Tool. В обычной ситуации, я бы перешел в Photoshop к этому моменту, чтобы сделать некоторые мелкие поправки, корректировки и т.д. Таким образом, лично для меня Painter — как раз для того, о чем говорит его название: для рисования. Редактирование и наложение эффектов проще делать a Photoshop.
Автор урока: Serio555
Перевод: Тигода
Последние авторы галереи
| Sketchdump, июнь 2016 г. [Faces] ДамайМиказ 1,291 64 Учебное пособие по уникальным возможностям: часть 2 Jeinu 12 857 432 Как рисовать лицо — основы Wysoka 547 9 Предварительный просмотр учебника по основам лица OlchaS 92 6 Учебник по портрету Чейз-Фалькенхаген 2 696 163 Учим мангу: как нарисовать женскую голову спереди Наски 18 135 489 18 — Стилизация Precia-T 757 36 Исследование лица персонажа нфук 84 6 Формы лица персонажей TAHOpaints 1,661 22 Типы стилизации 1 (учебник) Precia-T 4 027 145 Учебник по рисункам лица Снигом 18 567 715 Учебное пособие по уникальным возможностям: часть 3 Jeinu 10 475 282 Краткое руководство по лицу Exemi 2 861 85 |
Art Tutorial: How to Draw the Human Face
Снова добро пожаловать на очередной урок по искусству.Месяц или два назад мы рисовали кота со шрамами в битвах с помощью цифровых носителей. На этой неделе мы переключаемся на темы и используем традиционные методы для рисования человеческих лиц. На мой взгляд, это самое сложное, чему вы научитесь, хотя это лучший способ продвинуться в своем мастерстве.
Сегодня вам понадобятся следующие художественные принадлежности:
Графитовые карандаши — подойдет любой обычный повседневный карандаш, но если вы немного больше разбираетесь в технических аспектах карандашей, попробуйте найти карандаши 2B, 4B и 6B для этого проекта.
Ластик (желательно месеный ластик, но подойдет любой).
Бумага для принтера или альбом для рисования . Если вы используете бумагу для принтера, убедитесь, что вы работаете на ровной гладкой поверхности.
Терпение… и вменяемость. Да, это то, что вам понадобится сегодня, потому что слишком легко разочароваться в собственной работе. Не расстраивайтесь, если ваш рисунок будет немного изменен, или если вы не можете получить идеально прорисовку определенного аспекта. Каждый художник рисует в свое время, и даже самые опытные художники не будут рисовать картину ТОЧНО, как показано.Так что делайте все возможное и гордитесь собой за все, что вы делаете!
Вы собрали все необходимое? Что ж, тогда мы можем начать с «темы», которую мы будем рисовать. Вместо того, чтобы искать в Google бесплатные изображения лиц для рисования, я решил использовать лицо, которое не доставит мне неприятностей из-за неправильного изображения. Это лицо, это мое лицо, единственное лицо, которое я знаю, — мое, и да, мы собираемся его нарисовать. Ура! Вот изображение, с которым мы будем работать:
Для рисования, по крайней мере, для изучения основ рисования человеческого лица, вы всегда должны стараться найти в основном нейтральное лицо.Зубастые улыбки — это здорово, но правильно рисовать их — головная боль. По мере продвижения помните, что совершенно нормально вносить изменения в рисунок, если вы хотите или должны.
Шаг 1
Начните с карандаша 2B.
Первое, что вам нужно сделать, это изучить фото. Посмотрите на лицо объекта и выберите, какие формы вы видите. (Помните? Мы делали это и при рисовании кошки.) В конце концов, рисование — это всего лишь нахождение форм в жизни и их соединение по кусочкам.
Мы начнем с двух фигур, которые вы должны сразу выделить. Для головы у нас есть круг, затем большая U-образная форма для подбородка и для небольшой части шеи, которую мы видим, у нас есть треугольник. Не беспокойтесь о получении чего-либо еще прямо сейчас; просто нарисуйте овал и треугольник. Ваш рисунок на этом этапе должен выглядеть так, как на этом простом эскизе ниже.
Шаг 2
На следующем шаге я хочу, чтобы вы сначала нарисовали линию по центру круга / U-образной формы, который вы нарисовали, от макушки до середины подбородка.Затем я хочу, чтобы вы нарисовали линию, которая разрезает лицо пополам по горизонтали, примерно посередине лица. Начните с середины левой стороны лица, и, поскольку лицо немного наклонено, сделайте линию смещения вверх (только немного), когда вы проводите линию к правой стороне лица. Точно так же нарисуйте еще один, чуть выше того, который вы только что нарисовали. Это будут ваши рекомендации по размещению глаз, носа и рта.
Чтобы нарисовать нос, сначала посмотрите на нос объекта.Если вы посмотрите на формы, вы увидите, что нос на самом деле состоит только из круга и двух эллипсов. Нарисуйте выпуклую часть носа в виде круга примерно на полпути между нижней горизонтальной линией и подбородком. По обе стороны от этого маленького круга нарисуйте два эллипса (узкие овалы). С каждой стороны маленького круга нарисуйте переносицу двумя линиями. Нарисуйте эти линии полностью до верхней горизонтальной направляющей и сделайте так, чтобы они расходились друг от друга, чем выше они поднимаются.
Теперь, что касается бровей, скопируйте изображение как можно лучше и сделайте брови тем более узкими, чем дальше они удаляются от центра лица.
Для глаз нарисуйте два овала, а затем два круга внутри каждого из них. (Совет: чтобы добиться правильного интервала, нарисуйте третий овал между овалами для глаз. Общее правило состоит в том, что, как правило, вы должны уместить один глаз в центре лица между двумя другими). внутри угла каждого глаза нарисуйте крошечный треугольник и соедините его с овалами.Это твои слезные протоки. Для глаза слева овал должен почти касаться нарисованной брови.
Шаг 3
На этом этапе мы нарисуем контур того места, где находятся волосы. На самом деле это довольно просто. Не беспокойтесь о подробностях здесь; Просто уясните основную идею, только форму волос. (Вы уже заметили тему?) Часть волос объекта находится прямо над серединой брови, а затем вы следуете естественному изгибу лица / шеи, который вы уже нарисовали.Для челки нарисуйте изгибающуюся линию от прядей волос так, чтобы она касалась верхнего угла левой брови. Если хотите, вы можете добавить к прическе несколько указаний, как вы хотите, чтобы они расплывались.
Следующее, что я добавил на этом этапе, — это губы. Если вы действительно посмотрите на эти губы, вы почти сможете увидеть форму бантика. Нарисуйте изгибающуюся вверх линию посередине между носом и подбородком. Выше этого нарисуйте М-образную форму, которая кажется растянутой — по фотографии определите, где нарисуйте линию, разделяющую верхнюю и нижнюю губу.
Шаг 4
Вот здесь рисунок начнет выглядеть некрасиво, но не теряйте надежды! На этом этапе это всегда выглядит довольно странно, поскольку мы начинаем закрашивать более темные оттенки лица. Что вам нужно сделать, так это посмотреть на картинку и найти самые темные участки на лице — не на волосах, а только на коже прямо сейчас. Просто взглянув на лицо, можно увидеть, что самые темные оттенки находятся около линии роста волос, где волосы отбрасывают тень на лоб, по обе стороны от переносицы и где находятся области век / глазниц.Заштрихуйте шею, чтобы обозначить линию подбородка. Возьмите карандаш 4B (если он у вас есть) и заштрихуйте эти области, чтобы они выглядели как на фото ниже. Больше всего теней действительно на левой стороне лица, так как именно здесь волосы отбрасывают больше всего теней. На правой стороне лица обратите внимание на затенение, которое немного подчеркивает лицо, говоря вам, что это не плоская поверхность. Продолжайте затемнять эти области, но не затемняйте глаза или губы на этом этапе.
Шаг 5
Продолжая растушевывать более темные участки лица, начните слегка растушевывать остальную часть лица.Убедитесь, что ваши штрихи очень легкие, и используйте для этого карандаш 2B, если он у вас есть. Лицо не должно быть слишком темным, но при этом не должно быть видно белой бумаги. Когда вы закончите закрашивание всего лица и получите широкий диапазон значений, возьмите ластик и сотрите очень мягко на переносице и на каждой самой высокой точке щек.
То, что я посоветую вам сделать дальше, — это просто личный трюк, с которым не согласны некоторые художники, поэтому вы можете сами решить, делать это или нет.Возьмите палец и растушуйте растушевку, которую вы сделали на лице, чтобы создать более плавный переход к более темным или светлым областям. Это сделает кожу объекта более похожей на кожу и более гладкой, поэтому на коже не будет большого контраста между светлым и темным. Затемните брови сильными быстрыми движениями, заполнив оставленное вами пространство. Карандашом 6В обведите верхние веки и затемните ресницы.
(Это фото выше до размазывания; фото ниже в следующем шаге — то, как кожа выглядит с размазыванием).
Шаг 6
Теперь мы сосредоточимся на глазах и губах, которые сложнее всего правильно нарисовать. Что вы собираетесь сделать с глазами, это сначала посмотрите на фотографию и набросайте (слегка!), Где блики находятся на радужной оболочке глаза. Они покажут вам, где не следует затенять глаза, поэтому оставьте эти места белыми. Отсюда затемните зрачки и затемните верхнюю часть радужной оболочки над зрачками почти так же темно, как зрачок.Не забудьте оставить блики белыми, затемните радужную оболочку, становясь светлее по мере того, как вы продвигаетесь к нижней части каждой радужной оболочки.
Белки глаз растушевать легкими штрихами, и только около верхних век, прямо под ресницами.
Теперь что касается губ, затемните области, где встречаются верхняя и нижняя губа, и затемните их, чтобы было ясно, где губы начинаются на лице. Оставьте более светлое пространство около середины нижней губы, но не оставляйте его белым.
Шаг 7
А теперь перейдем к волосам! Это, вероятно, самая увлекательная часть рисунка, но вы должны понимать, что когда вы рисуете волосы, вы рисуете не каждую прядь волос… даже не сотню из них. Вы рисуете контрастирующие значения и формы, которые видите, точно так же, как мы это делали с лицом.
На этом этапе вам нужно взять самый темный карандаш (6B) и обвести самые темные части волос. Этими местами могут быть макушка или макушка головы, волосы на левой стороне лица и несколько других мест по всей голове объекта.Оставьте некоторые области в тех местах, где вы заштриховываете белый цвет, чтобы, когда вы вернетесь, чтобы нарисовать остальные волосы, вы заштриховали их полутемным оттенком.
Как видите, в самых темных областях нет видимых линий волос; это действительно просто сплошной оттенок. Вытяните самые темные тени на челку, чтобы она хорошо сочеталась, когда вы начинаете укладывать несколько прядей волос. Когда вы затемняете лицо рядом с лицом, делайте линии резкими, чтобы получился хороший контраст между самой темной частью волос и светлым лицом.
Шаг 8
Наносите слой на волосы равномерными мазками и затемняйте самые темные участки. Изучите рисунок, выбирая разные контрасты и формы в складках волос.
Не торопитесь и двигайтесь плавными движениями, следя за естественным течением волос. Сразу за челкой добавьте темную полоску и несколько волосков на шее, чтобы придать всему более реалистичный вид. Во время рисования сделайте самые темные области несколькими разными оттенками, чтобы добавить глубину рисунку.
Как только вы закончите наслоение волос, вы успешно нарисовали человеческое лицо! Теперь отправляйтесь в мир и распространяйте знания о рисовании!
____________________
Хейли Вернер — молодой писатель, который следует своей мечте. Она один из тех… интровертов, если хотите. Свою страсть она находит в писательстве, рисовании, пении и служении в своей школьной команде прославления. Некоторые называют ее творческой, интуитивной, тихой, нежной и грациозной, хотя иногда и вспыльчивой.Она живет в прекрасном штате Вирджиния со своей семьей из семи человек и любит наблюдать за сменой времен года в горах. Вы можете часто видеть, что она сидит одна, придумывает новые способы рассказать старую сказку или создает мелодии для новой песни, которую она написала, но она всегда приветствует беседу с теми, кто подходит к ней! Просто следите за собой, или она может найти способ втянуть вас в свой следующий роман. Вы можете следить за ней в ее блоге Facebook.
Как нарисовать лицо за 9 шагов
Прежде чем вы попытаетесь нарисовать реалистичный портрет определенного персонажа, вы должны сначала понять некоторые основные принципы, касающиеся пропорций.У каждого человека разные черты лица, но многие пропорции примерно одинаковы. В этом руководстве вы точно научитесь рисовать лицо с учетом этих принципов пропорциональности. Следуйте инструкциям и сделайте следующий шаг к красиво нарисованному портрету.
Рекомендуемые расходные материалы для рисования
Если вы хотите научиться правильно рисовать лицо, вам потребуются некоторые базовые принадлежности для рисования. Вот наше рекомендуемое оборудование, чтобы можно было нарисовать пропорции лица и затем растушевать изображение.
Шаг 1: Проведите поддерживающие линии
Нарисуйте круг, представляющий череп и вертикальную осевую линию.
Шага 2: Разделение линии поддержки в трети
Участка направляющих линий в треть, начать с линией, выше которой будет направляющей для роста волос. А нижняя линия будет краем линии подбородка.
Шаг 3: Нарисуйте челюсть
Шаг 4: Завершите форму головы
Нарисуйте верхнюю часть головы, а также нарисуйте несколько линий, чтобы обозначить полые части черепа и полую область щек.
Шаг 5: Как нарисовать лицо — Нарисуйте глаза
Глаза обычно находятся в центре, измеряя расстояние от макушки до подбородка. Ширина головы в области глаз около 5 глаз. Пространство между глазами равно ширине глаза.
Шаг 6: Нарисуйте нос
Крылья носа выровнены с слезными путями глаз. А расстояние по вертикали от глаз до верхней части крыльев носа равно высоте глаза.
Шаг 7: Нарисуйте рот
Расстояние от нижней части носа до верхней части рта — это высота глаза.Нижняя часть губ находится в центре низа носа и краю подбородка, а уголки губ совпадают с радужной оболочкой.
См. ТакжеШаг 8: Нарисуйте ухо и линию роста волос
Высота уха обычно идет от бровей до крыльев носа.
Нарисуйте линию роста волос по направляющим линиям, вы можете переходить по линии выше или ниже, в зависимости от того, насколько высоко или низко вы хотите, чтобы линия роста волос была.
Шаг 9: Нарисуйте детали и удалите поддерживающие линии
Волосы обычно имеют объем, поэтому они проходят над линией черепа.Удалите направляющие, затем визуализируйте и уточните остальные детали.
Загрузите шпаргалку по рисованию лица
Подпишитесь на нашу рассылку новостей
Получайте уведомления об эксклюзивных предложениях каждую неделю!
Искажение и ретуширование лица
Spark AR Studio можно использовать для изменения формы лиц людей. Вы также можете добавить эффект ретуши к лицам и всей сцене. В этом руководстве вы научитесь делать и то, и другое.
Все необходимое для создания этого эффекта вы найдете в папке с примерами содержимого.Загрузите его, чтобы следовать.
Начало работы
Чтобы изменить форму лица, вам понадобится объект, называемый blendshape, созданный в программе для 3D-моделирования. Мы включили один в образец файла содержимого. Используйте его для создания всевозможных эффектов лица.
Откройте незавершенный эффект в папке с примерами содержимого и проследите за ним. Чтобы помочь вам быстро приступить к работе, мы уже импортировали набор необходимых вам форм наложения. Он указан на панели Assets как faceDistortionPack .
Добавление сетки лица и средства отслеживания лиц
Начните с добавления средства отслеживания лиц на сцену:
- Щелкните Добавить объект в нижней части панели «Сцена».
- Выберите в меню Face Tracker .
Он будет указан как faceTracker0 на панели Scene.
Затем добавьте сетку лица в качестве дочернего элемента средства отслеживания лиц. Сетка лица — это трехмерная модель лица. Он работает с функцией отслеживания лица, чтобы создать поверхность, которая воссоздает чьи-то выражения.Затем мы будем использовать blendshape, чтобы изменить форму сетки лица, создав эффект искажения.
Чтобы добавить сетку лица в ваш проект:
- Щелкните правой кнопкой мыши на faceTracker0 на панели Scene.
- Выбрать Добавить .
- Выберите Face Mesh из меню.
Вы увидите faceMesh0 на панели Scene и объект, отслеживающий лицо во Viewport и Simulator:
Применение blendshapes
Вы примените blendshape к сетке лица.Для этого:
- Выберите сетку лица на панели Scene.
- Перейти к Деформация в Инспекторе.
- Щелкните + рядом с Деформация .
- Выберите faceDistortionPack .
Снимите флажки «Глаза» и «Рот».
Перед тем, как настраивать форму наложения, вам необходимо снять флажки рядом с полями Глаза и Рот в свойствах сетки лица.Это предотвратит закрытие и искажение отверстий для глаз и рта смесью.
Регулировка формы наложения
Теперь, когда вы добавили форму наложения, вы увидите параметр с надписью Morph Object . Ниже приведен список из 14 вариантов:
Вы можете настроить их, чтобы внести всевозможные изменения в форму лица — от настройки размера чьих-либо глаз до полного изменения формы лица.
Поэкспериментируйте с различными параметрами, регулируя ползунки, пока не добьетесь желаемого результата.
Когда вы применяете свой собственный объект к сетке лица, вы увидите здесь другой список опций.
Добавление ретуширования
В Spark AR Studio эффект ретуширования создается путем добавления материала к сетке лица и изменения типа шейдера в материале на Ретуширование .
Добавить сетку лица
Начните с добавления еще одной сетки лица в сцену в качестве дочернего элемента средства отслеживания лиц:
- Щелкните правой кнопкой мыши средство отслеживания лиц.
- Выбрать Добавить .
- Выберите Face Mesh .
Создайте материал
Затем создайте материал для сетки лица:
- Выберите сетку лица на панели «Сцена».
- В Инспекторе щелкните + рядом с «Материалы».
- Выберите Создать новый материал , чтобы создать новый материал.
Вот как будет выглядеть ваш проект:
Теперь выберите материал для изменения Shader Type .Он будет указан как material0 на панели Assets. В инспекторе:
- Измените тип шейдера на Ретуширование .
- Вы увидите параметр с надписью Skin Smoothing с ползунком рядом с ползунком — настройте его, чтобы изменить эффект сглаживания. Установите ползунок на 100% .
В Инспекторе вы увидите опцию, обозначенную Full Screen с флажком рядом с ней. Это применяет эффект сглаживания ко всему эффекту.Снимите этот флажок, чтобы применить ретуширование только к лицу.
Вы закончили эффект с ретушью и искажением лица.
Нарисуйте абстрактное лицо · Детские художественные проекты
Покажите ученикам, как нарисовать абстрактное лицо с помощью этого простого пошагового руководства. Результат всегда будет заполнять всю бумагу, а также будет иметь невероятно креативный вид.
Если кажется, что ваши ученики с каждым днем рисуют все меньше и меньше и стирают свою бумагу до смерти, пока они это делают, попробуйте этот проект по рисованию абстрактных лиц.Вам не нужно создавать его цветными карандашами и акварелью (хотя это мое любимое сочетание), вы можете закончить его фломастерами, темперой или чем угодно, что у вас есть под рукой. Дело в том, что это заставит учащихся сделать нетрадиционный рисунок, который заполнит их бумагу, и, скорее всего, приведет к чему-то очень отличному от их обычного подхода к рисованию лица. Это была моя любимая книга на протяжении многих лет, и она работала одинаково хорошо как для пятиклассников, так и для детей.
МАТЕРИАЛЫ- Рисование абстрактного лица PDF Учебное пособие
- Бумага для акварели *
- Маркер Sharpie, наконечник зубила *
- Мелки *
- Жидкая акварельная краска *
* Ссылки на продукты выше рефералы.Если вы перейдете по ссылке и примете меры, я получу небольшую компенсацию без каких-либо дополнительных затрат для вас.
НАПРАВЛЕНИЯНеобходимое время: 1 час.
Нарисуйте и раскрасьте абстрактное лицо
- Составьте руководящие принципы. Нарисуйте нос.
- Вытяните обе стороны до верха бумаги.
- Нарисуйте простой рот.
- Нарисуйте подбородок.
- Нарисуйте четыре изогнутые линии для глаз.
- Обработайте внутреннюю часть каждого глаза. Добавьте шею.
- Добавьте центр глаз. Проведите вертикальные линии над и под ртом.
- Обведите черным маркером. Добавьте линии мелками.
- Все закрасить акварельными красками.
Похожие сообщения
- Половина портрета
- Каракули летний автопортрет
- Нарисуйте портрет в солнцезащитных очках
Как нарисовать лицо — пошаговое руководство с инструкциями
В этом уроке я покажу вам, как нарисовать структуру лица с помощью нескольких простых шагов.
Я сделал небольшую видеоинструкцию, которая поможет вам следовать руководству и воспроизводить его столько раз, сколько вам нужно, чтобы запомнить все шаги.Смотрите перед чтением! (прокрутите вниз, чтобы посмотреть)
Это руководство по рисованию лиц создано в Procreate с использованием iPad Pro 12,9 дюйма и Apple Pencil.
Шаг 1 (только для пользователей планшетов):
Вам нужно создать 2 слоя, первый для направляющих, а второй для эскиза / штрихового рисунка.
Шаг 2:
Следуйте видеоуроку, чтобы набросать руководящие принципы. Важно соблюдать порядок, чтобы не было диспропорций.
Важно: Вам необходимо скорректировать структуру направляющих, если вы хотите нарисовать определенную грань.Например, сделать челюсть меньше, подбородок шире, глаза дальше друг от друга или нос побольше. Этот метод легко адаптируется, поэтому не стоит слишком усердствовать. Вы можете посмотреть это видео прямо здесь , чтобы получить полное подробное объяснение по этой теме. Вы также можете прочитать наш блог о структурах лица здесь.
Шаг 3:
Для цифровых художников: Установите первый слой, на котором вы нарисовали рекомендации по более низкой непрозрачности, и выберите второй слой, который вы создали на первом шаге.
Прежде чем вы начнете делать набросок лица, попробуйте представить, какой формы должна быть каждая часть лица. Это упрощает получение вашего рисунка так, как вы хотите. Теперь вы можете начать рисовать, делайте это медленно и не бойтесь стирать! Прежде чем разогреться как следует, может потребоваться даже 10 попыток, чтобы сделать первый глаз, но это нормально. Даже самому лучшему артисту в мире нужно немного разогреться.
Шаг 4:
Добавьте детали, и готово! При необходимости удалите слой с направляющими, но не обязательно.Лично мне нравится оставлять светлый слой с эскизом на заднем плане, он добавляет рисунку характера (по крайней мере, в моем стиле).
Как разработать систему распознавания лиц с помощью FaceNet в Керасе
Последнее обновление 24 августа 2020 г.
Распознавание лиц — это задача компьютерного зрения по идентификации и проверке личности человека по фотографии его лица.
FaceNet — это система распознавания лиц, разработанная в 2015 году исследователями Google, которая достигла на тот момент самых современных результатов на ряде наборов данных тестов распознавания лиц.Система FaceNet может широко использоваться благодаря множеству сторонних реализаций модели с открытым исходным кодом и доступности предварительно обученных моделей.
Система FaceNet может использоваться для извлечения высококачественных функций из лиц, называемых встраиваниями лиц, которые затем могут использоваться для обучения системы идентификации лиц.
В этом руководстве вы узнаете, как разработать систему обнаружения лиц с использованием FaceNet и классификатора SVM для идентификации людей по фотографиям.
После прохождения этого руководства вы будете знать:
- О системе распознавания лиц FaceNet, разработанной Google, реализациях с открытым исходным кодом и предварительно обученных моделях.
- Как подготовить набор данных для обнаружения лиц, включая сначала извлечение лиц с помощью системы обнаружения лиц, а затем извлечение черт лица с помощью встраивания лиц.
- Как подобрать, оценить и продемонстрировать модель SVM для прогнозирования идентичностей по встраиваемым лицам.
Начните свой проект с моей новой книги «Глубокое обучение для компьютерного зрения», включающей пошаговых руководств и файлов исходного кода Python для всех примеров.
Приступим.
- Обновление ноябрь / 2019: Обновлено для TensorFlow v2.0 и MTCNN v0.1.0.
Как разработать систему распознавания лиц с использованием FaceNet в Keras и классификатора SVM
Фотография Питера Вальверде, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на пять частей; их:
- Распознавание лиц
- FaceNet Модель
- Как загрузить модель FaceNet в Keras
- Как определять лица для распознавания лиц
- Как разработать систему классификации лиц
Распознавание лиц
Распознавание лиц — это общая задача идентификации и проверки людей по фотографиям их лиц.
В книге 2011 года по распознаванию лиц под названием «Справочник по распознаванию лиц» описаны два основных режима распознавания лиц:
- Проверка лица . Однозначное сопоставление данного лица с известной личностью (например, это человек? ).
- Идентификация лица . Отображение «один ко многим» для данного лица с базой данных известных лиц (например, , кто этот человек? ).
Ожидается, что система распознавания лиц будет автоматически определять лица, присутствующие на изображениях и видео.Он может работать в одном или обоих из двух режимов: (1) проверка лица (или аутентификация) и (2) идентификация лица (или распознавание).
— Стр. 1, Справочник по распознаванию лиц. 2011.
В этом уроке мы сосредоточимся на задаче идентификации лиц.
Хотите результатов с помощью глубокого обучения для компьютерного зрения?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
FaceNet Модель
FaceNet — это система распознавания лиц, описанная Флорианом Шроффом и др. в Google в их статье 2015 года под названием «FaceNet: унифицированное встраивание для распознавания лиц и кластеризации».
Это система, которая по изображению лица извлекает высококачественные черты лица и предсказывает 128-элементное векторное представление этих черт, называемое встраиванием лица.
FaceNet, который непосредственно изучает отображение изображений лиц в компактное евклидово пространство, где расстояния напрямую соответствуют мере сходства лиц.
— FaceNet: унифицированное встраивание для распознавания лиц и кластеризации, 2015 г.
Модель представляет собой глубокую сверточную нейронную сеть, обученную с помощью функции потерь триплетов, которая побуждает векторы для одной и той же идентичности становиться более похожими (меньшее расстояние), тогда как векторы для разных идентичностей, как ожидается, станут менее похожими (большее расстояние). Акцент на обучении модели непосредственному созданию вложений (а не извлечению их из промежуточного слоя модели) был важным нововведением в этой работе.
В нашем методе используется глубокая сверточная сеть, обученная непосредственно оптимизации самого встраивания, а не промежуточный слой узких мест, как в предыдущих подходах к глубокому обучению.
— FaceNet: унифицированное встраивание для распознавания лиц и кластеризации, 2015 г.
Эти вложения лиц затем были использованы в качестве основы для обучения систем классификаторов на стандартных наборах данных тестов распознавания лиц, что позволило получить самые современные результаты.
Наша система снижает количество ошибок по сравнению с лучшим опубликованным результатом на 30%…
— FaceNet: унифицированное встраивание для распознавания лиц и кластеризации, 2015 г.
В документе также исследуются другие применения встраивания, такие как кластеризация для группировки похожих лиц на основе их извлеченных функций.
Это надежная и эффективная система распознавания лиц, и общий характер извлеченных вложений лиц позволяет использовать этот подход для целого ряда приложений.
Как загрузить модель FaceNet в Keras
Существует ряд проектов, которые предоставляют инструменты для обучения моделей на основе FaceNet и используют предварительно обученные модели.
Пожалуй, наиболее известным из них является OpenFace, который предоставляет модели FaceNet, построенные и обученные с использованием инфраструктуры глубокого обучения PyTorch.Существует порт OpenFace для Keras, который называется Keras OpenFace, но на момент написания для моделей, похоже, требуется Python 2, что весьма ограничивает.
Другой известный проект под названием FaceNet Дэвида Сэндберга предоставляет модели FaceNet, построенные и обученные с использованием TensorFlow. Проект выглядит зрелым, хотя на момент написания не предусматривает ни установки на основе библиотек, ни чистого API. Полезно то, что проект Дэвида предоставляет ряд высокопроизводительных предварительно обученных моделей FaceNet, и есть ряд проектов, которые переносят или конвертируют эти модели для использования в Keras.
Ярким примером является Keras FaceNet Хироки Таниаи. Его проект предоставляет скрипт для преобразования модели Inception ResNet v1 из TensorFlow в Keras. Он также предоставляет предварительно обученную модель Keras, готовую к использованию.
Мы будем использовать предварительно обученную модель Keras FaceNet, предоставленную Hiroki Taniai в этом руководстве. Он был обучен на наборе данных MS-Celeb-1M и ожидает, что входные изображения будут цветными, с белыми значениями пикселей (стандартизованными для всех трех каналов) и квадратной формой 160 × 160 пикселей.
Модель можно скачать отсюда:
Загрузите файл модели и поместите его в текущий рабочий каталог с именем файла « facenet_keras.h5 ».
Мы можем загрузить модель прямо в Keras, используя функцию load_model () ; например:
# пример загрузки модели keras facenet из keras.models импортировать load_model # загружаем модель модель = load_model (‘facenet_keras.h5’) # суммировать форму ввода и вывода печать (модель.входы) печать (модель. выходы)
# пример загрузки модели keras facenet из keras.models import load_model # загрузить модель model = load_model (‘facenet_keras.h5’) # суммировать входную и выходную форму print (model. входы) печать (модель. выходы) |
При выполнении примера загружается модель и печатается форма входных и выходных тензоров.
Мы можем видеть, что модель действительно ожидает в качестве входных данных квадратных цветных изображений с формой 160 × 160 и будет выводить вложение лица в виде вектора из 128 элементов.
# [
# [ # [ |
Теперь, когда у нас есть модель FaceNet, мы можем изучить ее использование.
Как определять лица для распознавания лиц
Прежде чем мы сможем выполнить распознавание лиц, нам необходимо определить лица.
Распознавание лиц — это процесс автоматического обнаружения лиц на фотографии и их локализации путем рисования ограничивающей рамки вокруг их экстента.
В этом руководстве мы также будем использовать многозадачную каскадную сверточную нейронную сеть, или MTCNN, для обнаружения лиц, например.грамм. поиск и извлечение лиц из фотографий. Это современная модель глубокого обучения для обнаружения лиц, описанная в статье 2016 года под названием «Совместное обнаружение и выравнивание лиц с использованием многозадачных каскадных сверточных сетей».
Мы будем использовать реализацию, предоставленную Иваном де Пасом Сентено, в проекте ipazc / mtcnn. Это также можно установить через pip следующим образом:
Мы можем подтвердить, что библиотека была установлена правильно, импортировав библиотеку и распечатав версию; например:
# подтверждаем, что mtcnn был установлен правильно import mtcnn # версия для печати печать (mtcnn.__version__)
# подтвердить, что mtcnn был установлен правильно import mtcnn # print version print (mtcnn .__ version__) |
При выполнении примера распечатывается текущая версия библиотеки.
Мы можем использовать библиотеку mtcnn для создания детектора лиц и извлечения лиц для использования с моделями детекторов лиц FaceNet в следующих разделах.
Первым шагом является загрузка изображения в виде массива NumPy, чего мы можем добиться с помощью библиотеки PIL и функции open () .Мы также преобразуем изображение в RGB, на всякий случай, если изображение имеет альфа-канал или черно-белое.
# загрузить изображение из файла image = Image.open (имя файла) # преобразовать в RGB, если нужно изображение = изображение.convert (‘RGB’) # преобразовать в массив пикселей = asarray (изображение)
# загрузить изображение из файла image = Image.open (filename) # преобразовать в RGB, если необходимо image = image.convert (‘RGB’) # преобразовать в массив пикселей = asarray (изображение) |
Затем мы можем создать класс детектора лиц MTCNN и использовать его для обнаружения всех лиц на загруженной фотографии.
# создать детектор, используя веса по умолчанию детектор = MTCNN () # обнаруживаем лица на изображении results = Detect.detect_faces (пикселей)
# создать детектор, используя веса по умолчанию детектор = MTCNN () # обнаружить лица на изображении результаты = детектор.detect_faces (пиксели) |
Результатом является список ограничивающих прямоугольников, где каждый ограничивающий прямоугольник определяет нижний левый угол ограничивающего прямоугольника, а также ширину и высоту.
Если мы предположим, что для наших экспериментов на фотографии есть только одно лицо, мы можем определить пиксельные координаты ограничивающего прямоугольника следующим образом. Иногда библиотека возвращает отрицательный индекс пикселей, и я думаю, что это ошибка. Мы можем исправить это, взяв абсолютное значение координат.
# извлекаем ограничивающую рамку из первой грани x1, y1, ширина, высота = результаты [0] [‘box’] # Исправлена ошибка x1, y1 = абс (x1), абс (y1) x2, y2 = x1 + ширина, y1 + высота
# извлекаем ограничивающий прямоугольник из первой грани x1, y1, width, height = results [0] [‘box’] # исправление ошибки x1, y1 = abs (x1), abs (y1) x2, y2 = x1 + ширина, y1 + высота |
Мы можем использовать эти координаты, чтобы выделить лицо.
# извлекаем лицо лицо = пиксели [y1: y2, x1: x2]
# извлечь лицо face = пикселей [y1: y2, x1: x2] |
Затем мы можем использовать библиотеку PIL, чтобы изменить размер этого небольшого изображения лица до необходимого размера; в частности, модель ожидает квадратные входные грани с формой 160 × 160.
# изменить размер пикселей под размер модели image = Изображение.fromarray (лицо) image = image.resize ((160, 160)) face_array = asarray (изображение)
# изменить размер пикселей до размера модели image = Image.fromarray (face) image = image.resize ((160, 160)) face_array = asarray (image) |
Связывая все это вместе, функция extract_face () загрузит фотографию из загруженного файла и вернет извлеченное лицо.Предполагается, что фотография содержит одно лицо, и будет возвращено первое обнаруженное лицо.
# функция распознавания лиц с mtcnn из PIL импорта изображения из numpy import asarray из mtcnn.mtcnn импортировать MTCNN # извлекаем одно лицо из данной фотографии def extract_face (имя_файла, required_size = (160, 160)): # загрузить изображение из файла image = Image.open (имя файла) # преобразовать в RGB, если нужно изображение = изображение.convert (‘RGB’) # преобразовать в массив пикселей = asarray (изображение) # создать детектор, используя веса по умолчанию детектор = MTCNN () # обнаруживаем лица на изображении результаты = детектор.detect_faces (пиксели) # извлекаем ограничивающую рамку из первой грани x1, y1, ширина, высота = результаты [0] [‘box’] # Исправлена ошибка x1, y1 = абс (x1), абс (y1) x2, y2 = x1 + ширина, y1 + высота # извлекаем лицо лицо = пиксели [y1: y2, x1: x2] # изменить размер пикселей под размер модели image = Image.fromarray (лицо) image = image.resize (required_size) face_array = asarray (изображение) вернуть face_array # загружаем фото и извлекаем лицо пикселей = extract_face (‘… ‘)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | # функция для обнаружения лиц с mtcnn из PIL import Image из numpy import asarray из mtcnn.mtcnn import MTCNN # извлечь одно лицо из данной фотографии def extract_face (filename, required_size = (160, 160)): # загрузить изображение из файла image = Image.open (filename) # преобразовать в RGB, если необходимо image = image.convert (‘RGB’) # преобразовать в массив пикселей = asarray (image) # создать детектор, используя веса по умолчанию детектор = MTCNN ( ) # обнаружение лиц на изображении results = детектор.detect_faces (пикселей) # извлечь ограничивающую рамку из первой грани x1, y1, width, height = results [0] [‘box’] # исправить ошибку x1, y1 = abs (x1), abs (y1) x2, y2 = x1 + width, y1 + height # извлечь лицо face = пикселей [y1: y2, x1: x2] # изменить размер пикселей до размера модели image = Image.fromarray (face) image = image.resize (required_size) face_array = asarray (image) return face_array # загрузка фотографии и извлечение лица пикселей = extract_face (‘… ‘) |
Мы можем использовать эту функцию для извлечения лиц по мере необходимости в следующем разделе, который может быть предоставлен в качестве входных данных для модели FaceNet.
Как разработать систему классификации лиц
В этом разделе мы разработаем систему распознавания лиц для предсказания личности данного лица.
Модель будет обучена и протестирована с использованием « 5 Celebrity Faces Dataset », который содержит множество фотографий пяти разных знаменитостей.
Мы будем использовать модель MTCNN для обнаружения лиц, модель FaceNet будет использоваться для создания встраивания лица для каждого обнаруженного лица, затем мы разработаем модель классификатора Linear Support Vector Machine (SVM) для прогнозирования личности данного лица.
Набор данных 5 лиц знаменитостей
Набор данных 5 лиц знаменитостей — это небольшой набор данных, содержащий фотографии знаменитостей.
Включает фотографии: Бена Аффлека, Элтона Джона, Джерри Сайнфелда, Мадонны и Минди Калинг.
Набор данных был подготовлен и предоставлен Дэном Беккером для бесплатного скачивания на Kaggle. Обратите внимание: для загрузки набора данных требуется учетная запись Kaggle.
Загрузите набор данных (для этого может потребоваться вход в систему Kaggle), data.zip (2,5 мегабайта) и распакуйте его в свой локальный каталог с именем папки « 5-celebrity-faces-dataset ».
Теперь у вас должен быть каталог со следующей структурой (обратите внимание, в некоторых именах каталогов есть орфографические ошибки, и в этом примере они оставлены как есть):
Набор данных 5 лиц знаменитостей ├── поезд │ ├── ben_afflek │ ├── elton_john │ ├── jerry_seinfeld │ ├── мадонна │ └── mindy_kaling └── val ├── ben_afflek ├── elton_john ├── jerry_seinfeld ├── мадонна └── mindy_kaling
5-celebrity-faces-dataset ├── train │ ├── ben_afflek │ ├── elton_john │ ├── jerry_seinfeld mad ├── madonna │ ─ mindy_k └── val ├── ben_afflek ├── elton_john ├── jerry_seinfeld ├── madonna └── mindy_kaling |
Мы видим, что есть набор данных для обучения и набор данных для проверки или тестирования.
Глядя на некоторые фотографии в каталогах, мы видим, что на фотографиях представлены лица с разными ориентациями, освещением и разными размерами. Важно отметить, что на каждой фотографии есть одно лицо человека.
Мы будем использовать этот набор данных в качестве основы для нашего классификатора, обученного только на наборе данных « train », и классифицируем лица в наборе данных « val ». Вы можете использовать эту же структуру для разработки классификатора с вашими собственными фотографиями.
Обнаружение лиц
Первым шагом является обнаружение лица на каждой фотографии и сокращение набора данных только до серии лиц.
Давайте протестируем нашу функцию детектора лиц, определенную в предыдущем разделе, а именно extract_face () .
Просматривая каталог « 5-celebrity-faces-dataset / train / ben_afflek / », мы видим, что в наборе данных для обучения есть 14 фотографий Бена Аффлека. Мы можем обнаружить лицо на каждой фотографии и создать график с 14 лицами, с двумя рядами по семь изображений в каждом.
Полный пример приведен ниже.
# продемонстрировать обнаружение лиц в наборе данных 5 Celebrity Faces из os import listdir из PIL импорта изображения из numpy import asarray из matplotlib import pyplot от mtcnn.mtcnn import MTCNN # извлекаем одно лицо из данной фотографии def extract_face (имя_файла, required_size = (160, 160)): # загрузить изображение из файла image = Image.open (имя файла) # преобразовать в RGB, если нужно изображение = изображение.convert (‘RGB’) # преобразовать в массив пикселей = asarray (изображение) # создать детектор, используя веса по умолчанию детектор = MTCNN () # обнаруживаем лица на изображении results = Detect.detect_faces (пиксели) # извлекаем ограничивающую рамку из первой грани x1, y1, ширина, высота = результаты [0] [‘box’] # Исправлена ошибка x1, y1 = абс (x1), абс (y1) x2, y2 = x1 + ширина, y1 + высота # извлекаем лицо лицо = пиксели [y1: y2, x1: x2] # изменить размер пикселей под размер модели image = Изображение.fromarray (лицо) image = image.resize (required_size) face_array = asarray (изображение) вернуть face_array # указать папку для печати folder = ‘набор данных-лиц-знаменитостей / поезд / ben_afflek /’ я = 1 # перечислить файлы для имени файла в listdir (папке): # путь путь = папка + имя файла # получить лицо face = extract_face (путь) печать (я, face.shape) # участок pyplot.subplot (2, 7, я) pyplot.axis (‘выключено’) pyplot.imshow (лицо) я + = 1 пиплот.показать ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | # продемонстрировать обнаружение лиц в наборе данных 5 Celebrity Faces из os import listdir из PIL import Image из numpy import asarray из matplotlib import pyplot from mtcnn.mtcnn import MTCNN # извлечь одно лицо из данной фотографии def extract_face (filename, required_size = (160, 160)): # загрузить изображение из файла image = Image.open (filename) # преобразовать в RGB, если необходимо image = image.convert (‘RGB’) # преобразовать в массив пикселей = asarray (image) # создать детектор, используя веса по умолчанию детектор = MTCNN ( ) # обнаружение лиц на изображении results = детектор.detect_faces (пикселей) # извлечь ограничивающую рамку из первой грани x1, y1, width, height = results [0] [‘box’] # исправить ошибку x1, y1 = abs (x1), abs (y1) x2, y2 = x1 + width, y1 + height # извлечь лицо face = пикселей [y1: y2, x1: x2] # изменить размер пикселей до размера модели image = Image.fromarray (face) image = image.resize (required_size) face_array = asarray (image) return face_array # указать папку для построения графика folder = ‘5-celebrity-faces-dataset / train / ben_afflek / ‘ i = 1 # перечислить файлы для имени файла в listdir (папка): # путь путь = папка + имя файла # получить лицо лицо = extract_face (путь) принт (я, лицевой.shape) # plot pyplot.subplot (2, 7, i) pyplot.axis (‘off’) pyplot.imshow (face) i + = 1 pyplot.show () |
Выполнение примера занимает немного времени и сообщает о прогрессе каждой загруженной фотографии по пути и форме массива NumPy, содержащего данные пикселей лица.
1 (160, 160, 3) 2 (160, 160, 3) 3 (160, 160, 3) 4 (160, 160, 3) 5 (160, 160, 3) 6 (160, 160, 3) 7 (160, 160, 3) 8 (160, 160, 3) 9 (160, 160, 3) 10 (160, 160, 3) 11 (160, 160, 3) 12 (160, 160, 3) 13 (160, 160, 3) 14 (160, 160, 3)
1 (160, 160, 3) 2 (160, 160, 3) 3 (160, 160, 3) 4 (160, 160, 3) 5 (160, 160, 3) 6 (160, 160, 3) 7 (160, 160, 3) 8 (160, 160, 3) 9 (160, 160, 3) 10 (160, 160, 3) 11 (160, 160, 3) 12 (160, 160, 3) 13 (160, 160, 3) 14 (160, 160, 3) |
Создается фигура, содержащая лица, обнаруженные в каталоге Бена Аффлека.
Мы видим, что каждое лицо было правильно обнаружено и что у нас есть диапазон освещения, оттенков кожи и ориентации обнаруженных лиц.
Участок из 14 лиц Бена Аффлека, обнаруженный из тренировочного набора данных 5 лиц знаменитостей
Пока все хорошо.
Затем мы можем расширить этот пример, чтобы пройти по каждому подкаталогу для данного набора данных (например, « поезд » или « val »), извлечь лица и подготовить набор данных с именем в качестве выходной метки для каждого обнаруженного лицо.
Функция load_faces () ниже загрузит все грани в список для данного каталога, например ‘ 5-celebrity-faces-dataset / train / ben_afflek / ‘.
# загружать изображения и извлекать лица для всех изображений в каталоге def load_faces (каталог): лица = список () # перечислить файлы для имени файла в listdir (каталог): # путь путь = каталог + имя файла # получить лицо face = extract_face (путь) # хранить лица.добавить (лицо) возвратные грани
# загружать изображения и извлекать лица для всех изображений в каталоге def load_faces (directory): faces = list () # перечислять файлы для имени файла в listdir (каталог): # путь путь = каталог + имя файла # получить лицо лицо = извлечь_лицо (путь) # сохранить faces.append (лицо) вернуть лица |
Мы можем вызвать функцию load_faces () для каждого подкаталога в папках « train » или « val ».Каждое лицо имеет один ярлык, имя знаменитости, которое мы можем взять из названия каталога.
Функция load_dataset () ниже принимает имя каталога, такое как « 5-celebrity-faces-dataset / train / », и обнаруживает лица для каждого подкаталога (знаменитости), присваивая ярлыки каждому обнаруженному лицу.
Он возвращает элементы набора данных X и y в виде массивов NumPy.
# загружаем набор данных, содержащий по одному подкаталогу для каждого класса, который, в свою очередь, содержит изображения def load_dataset (каталог): X, y = список (), список () # перечислить папки по каждому классу для подкаталога в listdir (каталог): # путь путь = каталог + подкаталог + ‘/’ # пропустить любые файлы, которые могут быть в каталоге если не isdir (путь): Продолжать # загружаем все грани в подкаталог Faces = load_faces (путь) # создать ярлыки метки = [подкаталог для _ в диапазоне (len (лица))] # подвести итоги print (‘> загружено% d примеров для класса:% s’% (len (faces), subdir)) # хранить ИКС.продлить (лица) y.extend (метки) вернуть asarray (X), asarray (y)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # загрузить набор данных, который содержит один подкаталог для каждого класса, который, в свою очередь, содержит изображения def load_dataset (directory): X, y = list (), list () # перечислить папки для каждого класса для подкаталога в listdir (каталог): # путь path = directory + subdir + ‘/’ # пропустить любые файлы, которые могут быть в каталоге , если не isdir (путь): продолжить # загрузить все грани в подкаталог faces = load_faces (path) # создать метки labels = [подкаталог для _ in range (len (faces))] # подвести итоги прогресса print (‘> loaded% d примеры для класса:% s ‘% (len (faces), subdir)) # store X.расширить (грани) y.extend (метки) вернуть asarray (X), asarray (y) |
Затем мы можем вызвать эту функцию для папок «train» и «val», чтобы загрузить все данные, а затем сохранить результаты в одном сжатом файле массива NumPy с помощью функции savez_compressed ().
# загрузить набор данных поезда trainX, trainy = load_dataset (‘набор данных-лиц-5-знаменитостей / поезд /’) печать (trainX.shape, trainy.shape) # набор данных нагрузочного теста testX, testy = load_dataset (‘набор данных-лиц-5-знаменитостей / значение /’) печать (testX.shape, testy.shape) # сохранять массивы в один файл в сжатом формате savez_compressed (‘5-знаменитостей-лиц-dataset.npz’, trainX, trainy, testX, testy)
# загрузить набор данных поезда trainX, trainy = load_dataset (‘5-celebrity-faces-dataset / train /’) print (trainX.shape, trainy.shape) # load test dataset testX, testy = load_dataset (‘набор данных-лиц-знаменитостей / val /’) print (testX.shape, testy.shape) # сохранять массивы в один файл в сжатом формате savez_compressed (‘5-celebrity-faces-dataset.npz’, trainX, trainy, testX, testy) |
Объединяя все это вместе, ниже приводится полный пример обнаружения всех лиц в наборе данных 5 лиц знаменитостей.
# обнаружение лиц для набора данных 5 знаменитостей из os import listdir из os.path import isdir из PIL импорта изображения из matplotlib import pyplot из numpy import savez_compressed из numpy import asarray от mtcnn.mtcnn import MTCNN # извлекаем одно лицо из данной фотографии def extract_face (имя_файла, required_size = (160, 160)): # загрузить изображение из файла image = Image.open (имя файла) # преобразовать в RGB, если нужно изображение = изображение.convert (‘RGB’) # преобразовать в массив пикселей = asarray (изображение) # создать детектор, используя веса по умолчанию детектор = MTCNN () # обнаруживаем лица на изображении results = Detect.detect_faces (пиксели) # извлекаем ограничивающую рамку из первой грани x1, y1, ширина, высота = результаты [0] [‘box’] # Исправлена ошибка x1, y1 = абс (x1), абс (y1) x2, y2 = x1 + ширина, y1 + высота # извлекаем лицо лицо = пиксели [y1: y2, x1: x2] # изменить размер пикселей под размер модели image = Изображение.fromarray (лицо) image = image.resize (required_size) face_array = asarray (изображение) вернуть face_array # загружать изображения и извлекать лица для всех изображений в каталоге def load_faces (каталог): лица = список () # перечислить файлы для имени файла в listdir (каталог): # путь путь = каталог + имя файла # получить лицо face = extract_face (путь) # хранить Faces.append (лицо) вернуть лица # загружаем набор данных, содержащий по одному подкаталогу для каждого класса, который, в свою очередь, содержит изображения def load_dataset (каталог): X, y = список (), список () # перечислить папки по каждому классу для подкаталога в listdir (каталог): # путь путь = каталог + подкаталог + ‘/’ # пропустить любые файлы, которые могут быть в каталоге если не isdir (путь): Продолжать # загружаем все грани в подкаталог Faces = load_faces (путь) # создать ярлыки метки = [подкаталог для _ в диапазоне (len (лица))] # подвести итоги print (‘> загружено% d примеров для класса:% s’% (len (faces), subdir)) # хранить ИКС.продлить (лица) y.extend (метки) вернуть asarray (X), asarray (y) # загрузить набор данных поезда trainX, trainy = load_dataset (‘набор данных-лиц-5-знаменитостей / поезд /’) печать (trainX.shape, trainy.shape) # набор данных нагрузочного теста testX, testy = load_dataset (‘набор данных-лиц-5-знаменитостей / значение /’) # сохранять массивы в один файл в сжатом формате savez_compressed (‘5-знаменитостей-лиц-dataset.npz’, trainX, trainy, testX, testy)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0014 6465 66 67 68 69 70 71 72 73 74 75 | # обнаружение лиц для набора данных 5 лиц знаменитостей из ОС import listdir из ОС.path import isdir from PIL import Image from matplotlib import pyplot from numpy import savez_compressed from numpy import asarray from mtcnn.mtcnn import MTCNN # извлечь одно лицо из данной фотографии def extract_face (filename, required_size = (160, 160)): # загрузить изображение из файла image = Image.open (filename) # преобразовать в RGB, если необходимо image = image.convert (‘RGB’) # преобразование в массив пикселей = asarray (изображение) # создание детектора с использованием весов по умолчанию детектор = MTCNN () # обнаружение лиц на изображении результаты = детектор .detect_faces (пикселей) # извлечь ограничивающую рамку из первой грани x1, y1, width, height = results [0] [‘box’] # исправить ошибку x1, y1 = abs (x1) , abs (y1) x2, y2 = x1 + width, y1 + height # извлечь лицо face = пикселей [y1: y2, x1: x2] # изменить размер пикселей до размера модели image = Изображение.fromarray (face) image = image.resize (required_size) face_array = asarray (image) return face_array # загружать изображения и извлекать лица для всех изображений в каталоге def load_faces (directory): faces = list () # перечислить файлы для имени файла в listdir (каталог): # путь path = directory + filename # получить лицо face = extract_face (path) # store лиц.append (face) return faces # загружаем набор данных, содержащий по одному подкаталогу для каждого класса, который, в свою очередь, содержит изображения def load_dataset (directory): X, y = list (), list () # перечислить папки для каждого класса для подкаталога в listdir (каталог): # path path = directory + subdir + ‘/’ # пропустить любые файлы, которые могут быть в каталоге , если не isdir (путь): продолжить # загрузить все грани в подкаталог faces = load_faces (path) # создать метки label = [подкаталог для _ in range (len (faces))] # подвести итог progress print (‘> загружено% d примеров для класса:% s’% (len (faces), subdir)) # store X.extend (faces) y.extend (labels) return asarray (X), asarray (y) # load train dataset trainX, trainy = load_dataset (‘5-celebrity-faces-dataset / train / ‘) print (trainX.shape, trainy.shape) # загрузить тестовый набор данных testX, testy = load_dataset (‘ 5-celebrity-faces-dataset / val / ‘) # сохранить массивы в один файл в сжатом формате savez_compressed (‘5-celebrity-faces-dataset.npz’, trainX, trainy, testX, testy) |
Выполнение примера может занять некоторое время.
Сначала загружаются все фотографии в наборе данных « train », затем извлекаются лица, в результате получается 93 образца с вводом квадратного лица и строкой метки класса в качестве вывода. Затем загружается набор данных « val », содержащий 25 выборок, которые можно использовать в качестве тестового набора данных.
Оба набора данных затем сохраняются в сжатый файл массива NumPy с именем « 5-celebrity-faces-dataset.npz », который имеет размер около трех мегабайт и сохраняется в текущем рабочем каталоге.
> загружено 14 примеров для класса: ben_afflek > загружено 19 примеров для класса: мадонна > загружено 17 примеров для класса: elton_john > загружено 22 примера для класса: mindy_kaling > загружен 21 пример для класса: jerry_seinfeld (93, 160, 160, 3) (93,) > загружено 5 примеров для класса: ben_afflek > Загрузил 5 примеров для класса: мадонна > загружено 5 примеров для класса: elton_john > загружено 5 примеров для класса: mindy_kaling > загружено 5 примеров для класса: jerry_seinfeld (25, 160, 160, 3) (25,)
> загружено 14 примеров для класса: ben_afflek > загружено 19 примеров для класса: madonna > загружено 17 примеров для класса: elton_john > загружено 22 примера для класса: mindy_kaling > загружено 21 пример для класса: jerry_seinfeld (93, 160, 160, 3) (93,) > загружено 5 примеров для класса: ben_afflek > загружено 5 примеров для класса: madonna > загружено 5 примеров для класса: elton_john > загружено 5 примеры для класса: mindy_kaling > загружено 5 примеров для класса: jerry_seinfeld (25, 160, 160, 3) (25,) |
Этот набор данных готов к использованию в модели обнаружения лиц.
Создание вложения лиц
Следующий шаг — создание вложения лица.
Вложение лица — это вектор, который представляет черты, извлеченные из лица. Затем это можно сравнить с векторами, созданными для других лиц. Например, другой вектор, который находится близко (по какой-то мере), может быть тем же человеком, тогда как другой вектор, который находится далеко (по какой-то мере), может быть другим человеком.
Модель классификатора, которую мы хотим разработать, будет принимать вложение лица в качестве входных данных и предсказывать идентичность лица.Модель FaceNet сгенерирует это вложение для данного изображения лица.
Модель FaceNet может использоваться как часть самого классификатора, или мы можем использовать модель FaceNet для предварительной обработки лица для создания вложения лица, которое можно сохранить и использовать в качестве входных данных для нашей модели классификатора. Этот последний подход является предпочтительным, поскольку модель FaceNet является большой и медленной для создания вложения лица.
Таким образом, мы можем предварительно вычислить вложения лиц для всех лиц в наборе и протестировать (формально « val ») наборы в нашем наборе данных 5 Celebrity Faces.
Во-первых, мы можем загрузить наш набор данных обнаруженных лиц, используя функцию load () NumPy.
# загружаем набор данных лица data = load (‘5-знаменитостей-лиц-dataset.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] print (‘Загружено:’, trainX.shape, trainy.shape, testX.shape, testy.shape)
# загрузить набор данных лиц data = load (‘5-celebrity-faces-dataset.npz ‘) trainX, trainy, testX, testy = data [‘ arr_0 ‘], data [‘ arr_1 ‘], data [‘ arr_2 ‘], data [‘ arr_3 ‘] print (‘ Loaded: ‘, trainX .shape, trainy.shape, testX.shape, testy.shape) |
Затем мы можем загрузить нашу модель FaceNet, готовую для преобразования лиц во вложения лиц.
# загружаем модель facenet модель = load_model (‘facenet_keras.h5’) print (‘Загруженная модель’)
# загрузить модель facenet model = load_model (‘facenet_keras.h5 ‘) print (‘ Загруженная модель ‘) |
Затем мы можем перечислить каждое лицо в поезде и протестировать наборы данных, чтобы предсказать вложение.
Чтобы спрогнозировать встраивание, сначала необходимо соответствующим образом подготовить значения пикселей изображения, чтобы они соответствовали ожиданиям модели FaceNet. Эта конкретная реализация модели FaceNet предполагает стандартизацию значений пикселей.
# масштабировать значения пикселей face_pixels = face_pixels.astype (‘float32’) # стандартизировать значения пикселей по каналам (глобально) среднее, std = face_pixels.mean (), face_pixels.std () face_pixels = (face_pixels — среднее) / std
# масштабировать значения пикселей face_pixels = face_pixels.astype (‘float32’) # стандартизировать значения пикселей по каналам (глобально) mean, std = face_pixels.mean (), face_pixels.std () face_pixels = (face_pixels — среднее) / std |
Чтобы сделать прогноз для одного примера в Keras, мы должны расширить размеры так, чтобы массив лиц был одним образцом.
# преобразовать лицо в один образец образцы = expand_dims (face_pixels, axis = 0)
# преобразовать лицо в один образец samples = expand_dims (face_pixels, axis = 0) |
Затем мы можем использовать модель, чтобы сделать прогноз и извлечь вектор внедрения.
# сделать прогноз для встраивания yhat = model.predict (образцы) # получить встраивание вложение = yhat [0]
# сделать прогноз, чтобы получить вложение yhat = model.предсказать (образцы) # получить вложение вложение = yhat [0] |
Функция get_embedding () , определенная ниже, реализует это поведение и возвращает встраивание лица для одного изображения лица и загруженной модели FaceNet.
# получить вложение лица для одного лица def get_embedding (модель, face_pixels): # масштабировать значения пикселей face_pixels = face_pixels.astype (‘float32’) # стандартизировать значения пикселей по каналам (глобально) означает, std = face_pixels.среднее (), face_pixels.std () face_pixels = (face_pixels — среднее) / стандартное # преобразовать лицо в один образец образцы = expand_dims (face_pixels, axis = 0) # сделать прогноз для встраивания yhat = model.predict (образцы) вернуть yhat [0]
# получить вложение лица для одного лица def get_embedding (model, face_pixels): # масштабировать значения пикселей face_pixels = face_pixels.astype (‘float32’) # стандартизировать значения пикселей по каналам (глобально) означает, std = face_pixels.mean (), face_pixels.std () face_pixels = (face_pixels — mean) / std # преобразовать лицо в один образец samples = expand_dims (face_pixels, axis = 0) # сделать прогноз, чтобы получить вложение yhat = model.predict (образцы) вернуть yhat [0] |
Объединяя все это вместе, полный пример преобразования каждого лица в вложение лица в наборы данных поезда и тестирования приведен ниже.
# вычислить вложение лица для каждого лица в наборе данных с помощью facenet из numpy import load из numpy import expand_dims из numpy import asarray из numpy import savez_compressed из кераса.модели импортировать load_model # получить вложение лица для одного лица def get_embedding (модель, face_pixels): # масштабировать значения пикселей face_pixels = face_pixels.astype (‘float32’) # стандартизировать значения пикселей по каналам (глобально) среднее, std = face_pixels.mean (), face_pixels.std () face_pixels = (face_pixels — среднее) / стандартное # преобразовать лицо в один образец образцы = expand_dims (face_pixels, axis = 0) # сделать прогноз для встраивания yhat = модель.прогнозировать (образцы) вернуть yhat [0] # загружаем набор данных лица data = load (‘5-знаменитостей-лиц-dataset.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] print (‘Загружено:’, trainX.shape, trainy.shape, testX.shape, testy.shape) # загружаем модель facenet модель = load_model (‘facenet_keras.h5’) print (‘Загруженная модель’) # преобразовываем каждое лицо в наборе поезда в вложение newTrainX = список () для face_pixels в trainX: встраивание = get_embedding (модель, лицо_пиксели) newTrainX.добавить (встраивание) newTrainX = asarray (newTrainX) печать (newTrainX.shape) # преобразовываем каждое лицо в тестовом наборе во вложение newTestX = список () для face_pixels в testX: встраивание = get_embedding (модель, лицо_пиксели) newTestX.append (встраивание) newTestX = asarray (newTestX) печать (newTestX.shape) # сохранять массивы в один файл в сжатом формате savez_compressed (‘5-знаменитостей-лиц-embeddings.npz’, newTrainX, trainy, newTestX, testy)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | # вычислить вложение лица для каждого лица в наборе данных с помощью facenet из numpy import load из numpy import expand_dims из numpy import asarray из numpy import savez_compressed from keras.models import load_model # получить вложение лица для одного лица def get_embedding (model, face_pixels): # масштабировать значения пикселей face_pixels = face_pixels.astype (‘float32’) # стандартизировать значения пикселей по каналы (глобальные) mean, std = face_pixels.mean (), face_pixels.std () face_pixels = (face_pixels — mean) / std # преобразовать лицо в один образец samples = expand_dims (face_pixels, axis = 0) # сделать прогноз, чтобы получить вложение yhat = model.предсказать (образцы) return yhat [0] # загрузить набор данных лица data = load (‘5-celebrity-faces-dataset.npz’) trainX, trainy, testX, testy = data [ ‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] print (‘Loaded:’, trainX.shape, trainy.shape, testX.shape, testy.shape) # загрузить модель facenet model = load_model (‘facenet_keras.h5’) print (‘Загруженная модель’) # преобразовать каждое лицо в наборе поездов во вложение newTrainX = list () для face_pixels в trainX: embedding = get_embedding (model, face_pixels) newTrainX.append (embedding) newTrainX = asarray (newTrainX) print (newTrainX.shape) # преобразовать каждое лицо в тестовом наборе во вложение newTestX = list () для face_pixels в testX: embedding = get_embedding (model, face_pixels) newTestX.append (embedding) newTestX = asarray (newTestX) print (newTestX.shape) # сохранять массивы в один файл в сжатом формате savez_compressed (‘5-celebrity -лицы-вложения.npz ‘, newTrainX, trainy, newTestX, testy) |
Выполнение примера сообщает о ходе выполнения.
Мы видим, что набор данных лиц был загружен правильно, как и модель. Затем набор данных поезда был преобразован в 93 вложения лица, каждое из которых состоит из 128-элементного вектора. 25 примеров в наборе тестовых данных также были соответствующим образом преобразованы во вложения лиц.
Затем полученные наборы данных были сохранены в сжатом массиве NumPy размером около 50 килобайт с именем « встраиваний 5-лиц-знаменитостей».npz ‘в текущем рабочем каталоге.
Загружено: (93, 160, 160, 3) (93,) (25, 160, 160, 3) (25,) Загруженная модель (93, 128) (25, 128)
Загружен: (93, 160, 160, 3) (93,) (25, 160, 160, 3) (25,) Загружен Модель (93, 128) (25, 128) |
Теперь мы готовы разработать нашу систему классификатора лиц.
Выполнить классификацию лиц
В этом разделе мы разработаем модель для классификации вложения лиц в качестве одной из известных знаменитостей в наборе данных «5 лиц знаменитостей».
Во-первых, мы должны загрузить набор данных для вложения граней.
# загрузить набор данных data = load (‘5-знаменитостей-лиц-эмбеддингов.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] print (‘Набор данных: train =% d, test =% d’% (trainX.shape [0], testX.shape [0]))
# загрузить набор данных data = load (‘5-celebrity-faces-embeddings.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘ arr_2 ‘], data [‘ arr_3 ‘] print (‘ Набор данных: train =% d, test =% d ‘% (trainX.shape [0], testX.shape [0])) |
Затем данные требуют небольшой подготовки перед моделированием.
Во-первых, рекомендуется нормализовать векторы вложения лиц. Это хорошая практика, потому что векторы часто сравнивают друг с другом с использованием метрики расстояния.
В этом контексте нормализация векторов означает масштабирование значений до тех пор, пока длина или величина векторов не станет равной единице или единице длины. Этого можно достичь с помощью класса Normalizer в scikit-learn.Возможно, будет даже удобнее выполнить этот шаг, если на предыдущем шаге были созданы вложения лиц.
# нормализовать входные векторы in_encoder = Нормализатор (норма = ‘l2’) trainX = in_encoder.transform (trainX) testX = in_encoder.transform (testX)
# нормализовать входные векторы in_encoder = Нормализатор (norm = ‘l2’) trainX = in_encoder.transform (trainX) testX = in_encoder.преобразовать (testX) |
Затем необходимо преобразовать строковые целевые переменные для каждого имени знаменитости в целые числа.
Этого можно достичь с помощью класса LabelEncoder в scikit-learn.
# метка кодирует цели out_encoder = LabelEncoder () out_encoder.fit (тренироваться) trainy = out_encoder.transform (тренировочный) testy = out_encoder.transform (проворный)
# цели кодирования метки out_encoder = LabelEncoder () out_encoder.fit (тренировочный) trainy = out_encoder.transform (тренировочный) testy = out_encoder.transform (проворный) |
Теперь мы можем подогнать модель.
Обычно используется машина линейных опорных векторов (SVM) при работе с нормализованными входными данными внедрения граней. Это связано с тем, что метод очень эффективен при разделении векторов вложения граней. Мы можем подогнать линейную SVM к обучающим данным, используя класс SVC в scikit-learn и установив для атрибута « kernel » значение « linear ».Нам также могут потребоваться вероятности позже при прогнозировании, которые можно настроить, установив « вероятность » на « Истинно, ».
# подходящая модель модель = SVC (ядро = ‘линейный’) model.fit (trainX, trainy)
# fit model model = SVC (kernel = ‘linear’) model.fit (trainX, trainy) |
Далее мы можем оценить модель.
Этого можно достичь, используя модель соответствия, чтобы сделать прогноз для каждого примера в наборах данных поезда и тестирования, а затем вычислить точность классификации.
# предсказывать yhat_train = model.predict (trainX) yhat_test = model.predict (testX) # счет score_train = precision_score (тренировка, yhat_train) score_test = точность_score (testy, yhat_test) # подведем итог print (‘Точность: train =%. 3f, test =%. 3f’% (score_train * 100, score_test * 100))
# прогноз yhat_train = model.predict (trainX) yhat_test = model.predict (testX) # score score_train = precision_score (trainy, yhat_train) score_test = precision_score (testy, yhat_test) # summarize print (‘Accuracy: train =%. 3f, test =%. 3f ‘% (score_train * 100, score_test * 100)) |
Объединив все это вместе, ниже приведен полный пример подгонки линейной SVM к вложениям лиц для набора данных 5 лиц знаменитостей.
# разработать классификатор для набора данных 5 лиц знаменитостей из numpy import load из sklearn.metrics импортировать precision_score из sklearn.preprocessing import LabelEncoder из sklearn.preprocessing import Normalizer из sklearn.svm импортировать SVC # загрузить набор данных data = load (‘5-знаменитостей-лиц-эмбеддингов.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] print (‘Набор данных: поезд =% d, тест =% d’% (trainX.shape [0], testX.shape [0])) # нормализовать входные векторы in_encoder = Нормализатор (норма = ‘l2’) trainX = in_encoder.transform (trainX) testX = in_encoder.transform (testX) # метка кодирует цели out_encoder = LabelEncoder () out_encoder.fit (тренироваться) trainy = out_encoder.transform (тренировочный) testy = out_encoder.transform (проворно) # подходящая модель модель = SVC (ядро = ‘линейный’, вероятность = Истина) model.fit (trainX, trainy) # предсказывать yhat_train = model.predict (trainX) yhat_test = модель.предсказать (testX) # счет score_train = precision_score (тренировка, yhat_train) score_test = точность_score (testy, yhat_test) # подведем итог print (‘Точность: train =%. 3f, test =%. 3f’% (score_train * 100, score_test * 100))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # разработать классификатор для набора данных 5 Celebrity Faces из numpy import load из sklearn.metrics import precision_score из sklearn.preprocessing import LabelEncoder из sklearn.preprocessing import Normalizer из sklearn.svm import SVC # load dataset data = load (‘5-celebrity-faces-embeddings.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] print (‘Dataset: train =% d, test =% d ‘% (trainX.shape [0], testX.shape [0])) # нормализовать входные векторы in_encoder = Нормализатор (norm =’ l2 ‘) trainX = in_encoder.transform (trainX) testX = in_encoder.transform (testX) # label encoder target out_encoder = LabelEncoder () out_encoder.fit (trainy) trainy = out_encoder.transform (trainy) testy = out .transform (testy) # fit model model = SVC (kernel = ‘linear’, вероятно = True) model.fit (trainX, trainy) # pred yhat_train = model.predict (trainX) yhat_test = модель.предсказать (testX) # score score_train = precision_score (trainy, yhat_train) score_test = precision_score (testy, yhat_test) # summarize print (‘Accuracy: train =%. 3f, test =%. 3f ‘% (score_train * 100, score_test * 100)) |
Первый запуск примера подтверждает, что количество выборок в наборе данных поезда и теста соответствует ожидаемому.
Затем модель оценивается на поезде и тестовом наборе данных, демонстрируя безупречную точность классификации.Это неудивительно, учитывая размер набора данных и мощность используемых моделей обнаружения и распознавания лиц.
Набор данных: поезд = 93, тест = 25 Точность: поезд = 100.000, тест = 100.000
Набор данных: поезд = 93, тест = 25 Точность: поезд = 100,000, тест = 100,000 |
Мы можем сделать его более интересным, нарисовав исходное лицо и предсказание.
Во-первых, нам нужно загрузить набор данных лиц, в частности лица из тестового набора данных. Мы также можем загрузить оригинальные фотографии, чтобы было еще интереснее.
# загрузочные грани data = load (‘5-знаменитостей-лиц-dataset.npz’) testX_faces = данные [‘arr_2’]
# загрузить грани data = load (‘5-celebrity-faces-dataset.npz’) testX_faces = data [‘arr_2’] |
Остальная часть примера остается неизменной, пока мы не подгоним модель.
Сначала нам нужно выбрать случайный пример из набора тестов, затем получить вложение, пиксели лица, ожидаемый прогноз класса и соответствующее имя для класса.
# тестовая модель на случайном примере из тестового набора данных selection = choice ([i для i в диапазоне (testX.shape [0])]) random_face_pixels = testX_faces [выбор] random_face_emb = testX [выбор] random_face_class = testy [выбор] random_face_name = out_encoder.inverse_transform ([random_face_class])
# тестовая модель на случайном примере из набора тестовых данных selection = choice ([i for i in range (testX.shape [0])]) random_face_pixels = testX_faces [выбор] random_face_emb = testX [выбор] random_face_class = testy [выбор] random_face_name = out_encoder.inverse_transform ([random_face_class]) |
Затем мы можем использовать вложение лица в качестве входных данных, чтобы сделать единичный прогноз с подходящей моделью.
Мы можем предсказать как целое число класса, так и вероятность предсказания.
# предсказание для лица образцы = expand_dims (random_face_emb, axis = 0) yhat_class = модель.прогнозировать (образцы) yhat_prob = model.predict_proba (образцы)
# прогноз для лица samples = expand_dims (random_face_emb, axis = 0) yhat_class = model.predict (samples) yhat_prob = model.predict_proba (samples) |
Затем мы можем получить имя предсказанного целого числа класса и вероятность этого предсказания.
# получить имя class_index = yhat_class [0] class_probability = yhat_prob [0, class_index] * 100 pred_names = out_encoder.обратный_переход (yhat_class)
# получить имя class_index = yhat_class [0] class_probability = yhat_prob [0, class_index] * 100 pred_names = out_encoder.inverse_transform (yhat_class) |
Затем мы можем распечатать эту информацию.
print (‘Прогноз:% s (% .3f)’% (имя_предсказания [0], вероятность_класса)) print (‘Ожидается:% s’% random_face_name [0])
print (‘Прогноз:% s (%.3f) ‘% (pred_names [0], class_probability)) print (‘ Expected:% s ‘% random_face_name [0]) |
Мы также можем построить пиксели лица вместе с предсказанным именем и вероятностью.
# сюжет для развлечения pyplot.imshow (random_face_pixels) title = ‘% s (% .3f)’% (pred_names [0], class_probability) pyplot.title (заголовок) pyplot.show ()
# сюжет для прикола pyplot.imshow (random_face_pixels) title = ‘% s (% .3f)’% (pred_names [0], class_probability) pyplot.title (title) pyplot.show () |
Объединяя все это воедино, ниже приводится полный пример прогнозирования личности для данной невидимой фотографии в тестовом наборе данных.
# разработать классификатор для набора данных 5 лиц знаменитостей из случайного выбора импорта из numpy import load из numpy import expand_dims из склеарна.предварительная обработка импорта LabelEncoder из sklearn.preprocessing import Normalizer из sklearn.svm импортировать SVC из matplotlib import pyplot # загрузочные грани data = load (‘5-знаменитостей-лиц-dataset.npz’) testX_faces = данные [‘arr_2’] # загрузить вложения граней data = load (‘5-знаменитостей-лиц-эмбеддингов.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] # нормализовать входные векторы in_encoder = Нормализатор (норма = ‘l2’) trainX = in_encoder.преобразовать (trainX) testX = in_encoder.transform (testX) # метка кодирует цели out_encoder = LabelEncoder () out_encoder.fit (тренироваться) trainy = out_encoder.transform (тренировочный) testy = out_encoder.transform (проворно) # подходящая модель модель = SVC (ядро = ‘линейный’, вероятность = Истина) model.fit (trainX, trainy) # тестовая модель на случайном примере из тестового набора данных selection = choice ([i для i в диапазоне (testX.shape [0])]) random_face_pixels = testX_faces [выбор] random_face_emb = testX [выбор] random_face_class = testy [выбор] random_face_name = out_encoder.обратная_трансформация ([random_face_class]) # предсказание для лица образцы = expand_dims (random_face_emb, axis = 0) yhat_class = model.predict (образцы) yhat_prob = model.predict_proba (образцы) # получить имя class_index = yhat_class [0] class_probability = yhat_prob [0, class_index] * 100 pred_names = out_encoder.inverse_transform (yhat_class) print (‘Прогноз:% s (% .3f)’% (имя_предсказания [0], вероятность_класса)) print (‘Ожидается:% s’% random_face_name [0]) # сюжет для развлечения пиплот.imshow (random_face_pixels) title = ‘% s (% .3f)’% (pred_names [0], class_probability) pyplot.title (заголовок) pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | # разработать классификатор для набора данных 5 Celebrity Faces из случайного выбора импорта из numpy import load из numpy import expand_dims из sklearn.preprocessing import LabelEncoder из sklearn.preprocessing import Normalizer из sklearn.svm import SVC из matplotlib import pyplot # load faces data = load (‘5-celebrity-faces-dataset.npz’) testX_faces = data [‘arr_2’] # load face embeddings data = load (‘5-celebrity-faces-embeddings.npz’) trainX, trainy, testX, testy = data [‘arr_0’], data [‘arr_1’], data [‘arr_2’], data [‘arr_3’] # нормализовать входные векторы in_encoder = Нормализатор (norm = ‘l2’) trainX = in_encoder.transform (trainX) testX = in_encoder.transform (testX) # label encoder target out_encoder = LabelEncoder () out_encoder.fit (trainy) trainy = out_encoder.transform (trainy) testy = out .transform (testy) # fit model model = SVC (kernel = ‘linear’, sizes = True) model.fit (trainX, trainy) # тестовая модель на случайном примере из тестового набора данных selection = choice ([i for i in range (testX.shape [0])]) random_face_pixels = testX_faces [выбор] random_face_emb = testX [выбор] random_face_class = testy [выбор] random_face_name = out_encoder.inverse_transform ([random_face_class]) лицо samples = expand_dims (random_face_emb, axis = 0) yhat_class = model.predict (samples) yhat_prob = model.predict_proba (samples) # получить имя class_index = yhat_class [0] class_probability [0, class_index] * 100 pred_names = out_encoder.inverse_transform (yhat_class) print (‘Прогноз:% s (% .3f)’% (pred_names [0], class_probability)) print (‘Expected:% s’% random_face_name [0]) # график для fun pyplot.imshow (random_face_pixels) title = ‘% s (% .3f)’% (pred_names [0], class_probability) pyplot.title (title) pyplot.show () |
При каждом запуске кода будет выбираться другой случайный пример из тестового набора данных.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
В данном случае выбрана и правильно спрогнозирована фотография Джерри Сайнфельда.
Прогноз: jerry_seinfeld (88.476) Ожидается: jerry_seinfeld
Прогноз: jerry_seinfeld (88.476) Ожидается: jerry_seinfeld |
Также создается график выбранного лица, показывающий предсказанное имя и вероятность в заголовке изображения.
Обнаруженное лицо Джерри Сайнфельда, правильно идентифицированное классификатором SVM
Дополнительная литература
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться.