
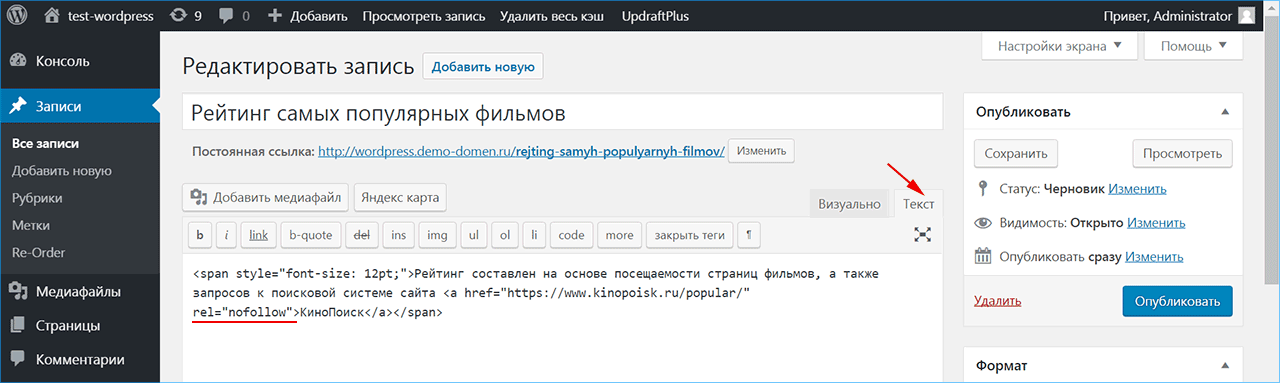
Nofollow noindex пример: Полное руководство по Robots.txt и метатегу Noindex
Полное руководство по Robots.txt и метатегу Noindex
Файл Robots.txt и мета-тег Noindex важны для SEO-продвижения. Они информируют Google, какие именно страницы необходимо сканировать, а какие – индексировать (отображать в результатах поиска).
С помощью этих средств можно ограничить содержимое сайта, доступное для индексации.
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Noindex – это метатег, который запрещает поисковым системам индексировать страницу.
Существует три способа добавления Noindex на страницы:
Разместите приведенный ниже код в раздел <head> страницы:
<meta name=”robots” content=”noindex”>
Он сообщает всем типам поисковых роботов об условиях индексации страницы. Если нужно запретить индексацию страницы только для определенного робота, поместите его название в значение атрибута name.
Чтобы запретить индексацию страницы для Googlebot:
<meta name=”googlebot” content=”noindex”>
Чтобы запретить индексацию страницы для Bingbot:
<meta name=”bingbot” content=”noindex”>
Также можно разрешить или запретить роботам переход по ссылкам, размещенным на странице.
Чтобы разрешить переход по ссылкам на странице:
<meta name=”robots” content=”noindex,follow”>
Чтобы запретить поисковым роботам сканировать ссылки на странице:
<meta name=”robots” content=”noindex,nofollow”>
x-robots-tag позволяет управлять индексацией страницы через HTTP-заголовок. Этот тег также указывает поисковым системам не отображать определенные типы файлов в результатах поиска. Например, изображения и другие медиа-файлы.
Для этого у вас должен быть доступ к файлу .htaccess. Директивы в метатеге «robots» также применимы к x-robots-tag.
Плагин YoastSEO в WordPress автоматически генерирует приведенный выше код. Для этого на странице записи перейдите в интерфейсе YoastSEO в настройки публикации, щелкнув по значку шестеренки. Затем в опции «Разрешить поисковым системам показывать эту публикацию в результатах поиска?» выберите «Нет».
Также можно задать тег noindex для страниц категорий. Для этого зайдите в плагин Yoast, в «Вид поиска». Если в разделе «Показать категории в результатах поиска» выбрать «Нет», тег noindex будет размещен на всех страницах категорий.
Если в разделе «Показать категории в результатах поиска» выбрать «Нет», тег noindex будет размещен на всех страницах категорий.
- Чтобы проиндексированная страница была удалена из результатов поиска, убедитесь, что она не заблокирована в файле robots.txt. И только потом добавляйте тег noindex. Иначе Googlebot не сможет увидеть тег на странице. Если заблокировать страницу без тега noindex, она все равно будет отображаться в результатах поиска:
- Добавление директивы sitemap в файл robots.txt технически не требуется, но считается хорошей практикой.
- После обновления файла robots.txt рекомендуется проверить, не заблокированы ли важные страницы. Это можно сделать с помощью txt Tester в Google Search Console.
- Используйте инструмент проверки URL-адреса в Google Search Console, чтобы увидеть статус индексации страницы.
- Также можно проверить, проиндексировал ли Google ненужные страницы. Это можно сделать с помощью отчета в Google Search Console. Еще одной альтернативой может быть использование оператора «site».

В последнее время в SEO-сообществе было много недоразумений по поводу использования noindex в robots.txt. Но представители Google много раз говорили, что поисковая система не поддерживают данный метатег. И все же многие люди настаивают на том, что он все еще работает. Но лучше избегать его использования.
Заблокированные через robots.txt страницы, не могут быть проиндексированы, даже если кто-то на них ссылается.
Чтобы быть уверенным, что страница без контента случайно не появится в результатах поиска, Джон Мюллер рекомендует размещать на этих веб-страницах noindex даже после того, как вы заблокировали их в robots.txt.
Использование файла robots.txt улучшает не только SEO, но и пользовательский опыт. Для этого реализуйте приведенные выше практики.
Пожалуйста, оставьте ваши комментарии по текущей теме статьи. Мы очень благодарим вас за ваши комментарии, отклики, лайки, подписки, дизлайки!
Пожалуйста, опубликуйте свои мнения по текущей теме материала. За комментарии, лайки, дизлайки, отклики, подписки огромное вам спасибо!
За комментарии, лайки, дизлайки, отклики, подписки огромное вам спасибо!
Ангелина Писанюкавтор-переводчик статьи «The Complete Guide to Robots.txt and Noindex Meta Tag»
Noindex Nofollow и Disallow: директивы поискового робота
Опубликовано: 2019-11-14
Есть три директивы (команды), которые вы можете использовать, чтобы определять, как поисковые системы обнаруживают, хранят и обслуживают информацию с вашего сайта в качестве результатов поиска:
- NoIndex: не добавлять мою страницу в результаты поиска.
- NoFollow: не смотрите ссылки на этой странице.
- Запрещение: вообще не смотрите на эту страницу.
Эти директивы позволяют вам контролировать, какие страницы вашего сайта могут сканироваться поисковыми системами и отображаться в поиске.
Что означает отсутствие индекса?
Директива noindex предписывает поисковым роботам, таким как googlebot, не включать веб-страницу в результаты поиска.
Как пометить страницу как NoIndex?
Есть два способа ввести директиву noindex :
- Добавьте метатег noindex в HTML-код страницы
- Вернуть заголовок noindex в HTTP-запросе
Используя метатег «без индекса» для страницы или в качестве заголовка HTTP-ответа, вы, по сути, скрываете страницу от поиска.
Директива noindex также может использоваться для блокировки только определенных поисковых систем. Например, вы можете заблокировать Google от индексации страницы, но по-прежнему разрешить Bing:
Пример: блокирование большинства поисковых систем *
<meta name = ”robots” content = ”noindex”>
Пример: блокировка только Google
<meta name = «googlebot» content = «noindex»>
Обратите внимание: с сентября 2019 года Google больше не соблюдает директивы noindex в файле robots. txt . Noindex теперь ДОЛЖЕН выдаваться через метатег HTML или заголовок ответа HTTP. Для более опытных пользователей запрет по- прежнему работает, хотя и не для всех случаев использования.
txt . Noindex теперь ДОЛЖЕН выдаваться через метатег HTML или заголовок ответа HTTP. Для более опытных пользователей запрет по- прежнему работает, хотя и не для всех случаев использования.
В чем разница между noindex и nofollow?
В этом разница между хранением контента и его обнаружением:
noindex применяется на уровне страницы и сообщает сканеру поисковой системы не индексировать и не показывать страницу в результатах поиска.
nofollow применяется на уровне страницы или ссылки и сообщает сканеру поисковой системы не переходить (обнаруживать) ссылки.
По сути, тег noindex удаляет страницу из поискового индекса, а атрибут nofollow удаляет ссылку из графа ссылок поисковой системы.
NoFollow как атрибут страницы
Использование nofollow на уровне страницы означает, что поисковые роботы не будут переходить ни по одной из ссылок на этой странице для обнаружения дополнительного контента, а поисковые роботы не будут использовать ссылки в качестве сигналов ранжирования для целевых сайтов.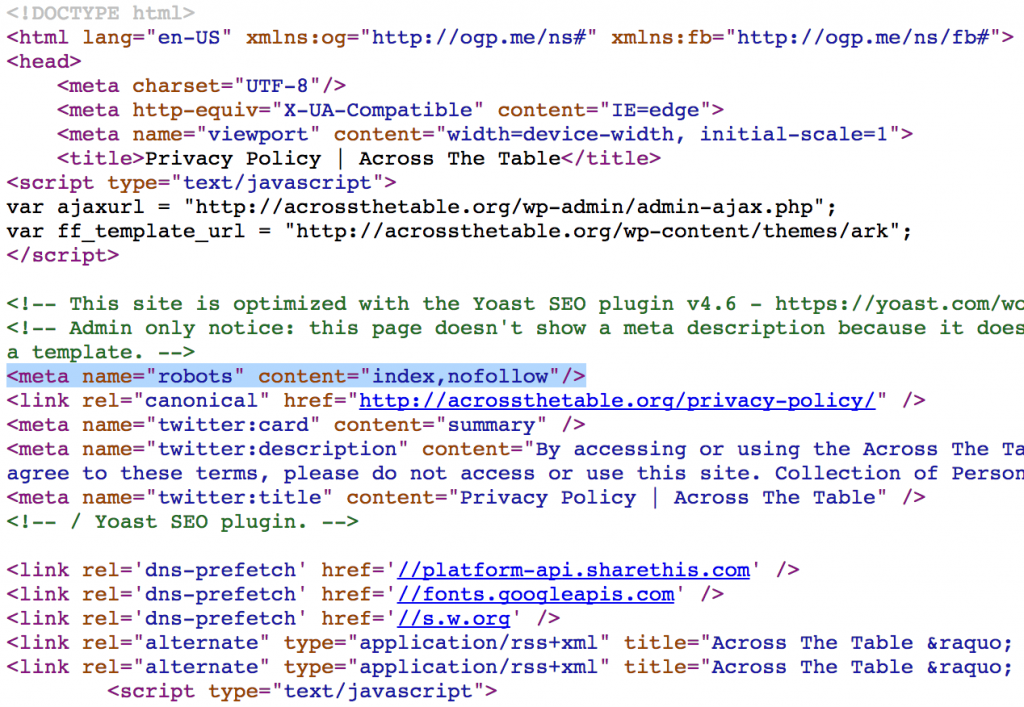
<meta name = ”robots” content = ”nofollow”>
NoFollow как атрибут ссылки
Использование nofollow на уровне ссылки не позволяет сканерам исследовать ссылку, связанную с рекламой, и предотвращает использование этой ссылки в качестве сигнала ранжирования.
Директива nofollow применяется на уровне ссылки с использованием атрибута rel в теге href:
<a href=»https://domain.com» rel=»nofollow»>
В частности, для Google использование атрибута ссылки nofollow не позволит вашему сайту передавать PageRank целевым URL.
Однако недавно Google объявил, что с 1 марта 2020 года поисковая система начнет обрабатывать ссылки NoFollow как «подсказки», которые способствуют общему поисковому авторитету сайта.
Почему вы должны помечать страницу как NoFollow?
Для большинства случаев применения, не следует отметить целую страницу как NoFollow — маркировка отдельных ссылок , как NoFollow будет достаточно.
Вы бы пометили всю страницу как nofollow, если не хотите, чтобы Google просматривал ссылки на странице, или если вы думаете, что ссылки на странице могут повредить вашему сайту.
В большинстве случаев общие директивы nofollow на уровне страницы используются, когда вы не контролируете контент, публикуемый на странице Некоторые высококлассные издатели также неуклонно применяют директиву nofollow к своим страницам, чтобы отговорить авторов размещать спонсируемые ссылки в своем контенте.
Как использовать страницы NoIndex?
Пометьте страницы как noindex, которые вряд ли принесут пользу пользователям и не должны отображаться в результатах поиска. Например, страницы, которые существуют для разбивки на страницы, вряд ли будут отображать одно и то же содержимое с течением времени.
Domain.com/category/resultspage=2 вряд ли покажет пользователю лучшие результаты, чем domain.com/category/resultspage=1, и эти две страницы будут только конкурировать друг с другом в поиске. Лучше всего не индексировать страницы, единственная цель которых — разбиение на страницы.
Вот типы страниц, которые вы не должны индексировать:
- Страницы, используемые для нумерации страниц
- Страницы внутреннего поиска
- Целевые страницы, оптимизированные для рекламы
- Пример: отображает только презентацию и форму регистрации, без основной навигации.
- Пример: повторяющиеся варианты одного и того же содержания, используемые только для рекламы.
- Пример: отображает только презентацию и форму регистрации, без основной навигации.
- Архивные страницы авторов
- Страницы в потоках оформления заказа
- Страницы подтверждения
- Пример: страницы с благодарностями
- Пример: заказ полных страниц
- Пример: Успех! Страницы
- Некоторые страницы, созданные плагином, не имеющие отношения к вашему сайту (например, если вы используете коммерческий плагин, но не используете их обычные страницы продуктов)
- Страницы администратора и страницы входа администратора

Пометка страницы как Noindex и Nofollow
Страница, отмеченная как noindex, так и nofollow, заблокирует индексирование этой страницы поисковым роботом, а также запретит поисковому роботу просматривать ссылки на странице.
По сути, изображение ниже демонстрирует, что поисковая система увидит на веб-странице в зависимости от того, как вы использовали директивы noindex и nofollow:
Пометка уже проиндексированной страницы как NoIndex
Если поисковая система уже проиндексировала страницу, и вы отметили ее как noindex , то при следующем сканировании страница будет удалена из результатов поиска Чтобы этот метод удаления страницы из индекса работал, вы не должны блокировать (запрещать) поисковый робот с вашим файлом robots. txt.
txt.
Если вы говорите поисковому роботу не читать страницу, он никогда не увидит маркер noindex , и страница останется индексированной, хотя ее содержимое не будет обновлено.
Как мне запретить поисковым системам индексировать мой сайт?
Если вы хотите удалить страницу из поискового индекса после того, как она уже проиндексирована, вы можете выполнить следующие действия:
- Примените директиву noindex. Добавьте атрибут noindex к метатегу или заголовку ответа HTTP.
- Запросите поисковую систему проиндексировать страницу. Для Google вы можете сделать это в поисковой консоли, запросить у Google повторную индексацию страницы. Это приведет к тому, что робот Googlebot просканирует страницу, где робот обнаружит директиву noindex. Вам нужно будет сделать это для каждой поисковой системы, которую вы хотите удалить.
- Подтвердите, что страница была удалена из поиска. После того, как вы попросили сканер повторно посетить вашу веб-страницу, подождите некоторое время, а затем подтвердите, что ваша страница была удалена из результатов поиска. Вы можете сделать это, перейдя в любую поисковую систему и введя целевой URL-адрес сайта в двоеточии, как на изображении ниже.
Если ваш поиск не дал результатов, значит ваша страница была удалена из этого поискового индекса. - Если страница не была удалена. Убедитесь, что в вашем файле robots.txt нет директивы «запретить». Google и другие поисковые системы не могут прочитать директиву noindex, если им не разрешено сканировать страницу. Если вы это сделаете, удалите директиву disallow для целевой страницы, а затем снова запросите сканирование.
- Установите директиву disallow для целевой страницы в файле robots.txt Disallow: / page $
Вам нужно будет поставить знак доллара в конце URL-адреса в вашем файле robots.txt, иначе вы можете случайно запретить любые страницы под этой страницей, а также любые страницы, начинающиеся с той же строки. Пример: Disallow: / sweater также запретит / sweater-weather и / sweater / green, но Disallow: / sweater $ запретит только конкретную страницу / sweater.
 Вы можете сделать это, перейдя в любую поисковую систему и введя целевой URL-адрес сайта в двоеточии, как на изображении ниже.
Вы можете сделать это, перейдя в любую поисковую систему и введя целевой URL-адрес сайта в двоеточии, как на изображении ниже.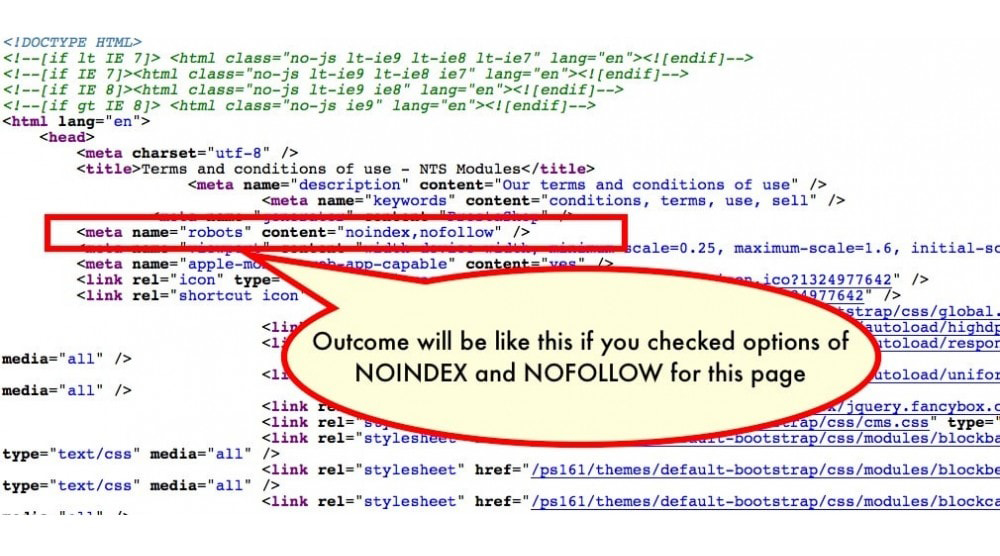
Как удалить страницу из поиска Google
Если страница, которую вы хотите удалить из поиска, находится на сайте, которым вы владеете или управляете, большинство сайтов могут использовать Инструмент удаления URL-адресов для веб-мастеров.
Инструмент удаления URL-адресов веб-мастеров удаляет контент из поиска только примерно на 90 дней. Если вам нужно более постоянное решение, вам нужно будет использовать директиву noindex, запретить сканирование из вашего robots.txt или удалить страницу с вашего сайта. Здесь Google предоставляет дополнительные инструкции по удалению безвозвратного URL.
Если вы пытаетесь удалить страницу из поиска сайта, которым вы не владеете, вы можете запросить Google удалить страницу из поиска, если она соответствует следующим критериям:
- Отображает личную информацию, такую как ваша кредитная карта или номер социального страхования
- Страница является частью вредоносной программы или схемы фишинга.
- Страница нарушает закон
- Страница нарушает авторские права
Если страница не соответствует ни одному из вышеперечисленных критериев, вы можете обратиться в SEO-компанию или PR-компанию за помощью в управлении репутацией в Интернете.
Стоит ли вам индексировать страницы категорий?
Обычно не рекомендуется индексировать страницы категорий, если только вы не являетесь организацией уровня предприятия, которая программно раскручивает страницы категорий на основе пользовательских поисковых запросов или тегов, а дублированный контент становится громоздким.
По большей части, если вы разумно помечаете свой контент, чтобы пользователи могли лучше ориентироваться на вашем сайте и находить то, что им нужно, тогда все будет в порядке.
Фактически, страницы категорий могут быть золотой жилой для SEO, поскольку они обычно показывают глубину содержания по темам категорий.
Взгляните на этот анализ, который мы провели в декабре 2018 года, чтобы количественно оценить ценность страниц категорий для нескольких онлайн-публикаций.
* Анализ выполнен с использованием данных AHREFS. Мы обнаружили, что целевые страницы категории ранжируются по сотням ключевых слов страницы 1 и привлекают тысячи обычных посетителей каждый месяц.
Страницы с наиболее ценными категориями для каждого сайта часто привлекали тысячи органических посетителей.
Взгляните на EW.com ниже, мы измерили трафик для каждой страницы (представленный размером круга) и ценность трафика для каждой страницы (представленный цветом круга).
Ежемесячный органический трафик на страницу = размерЕжемесячная органическая ценность страницы = глубина цвета
А теперь представьте те же диаграммы, но для сайтов, посвященных товарам, на которых посетители, скорее всего, совершат активные покупки.
При этом, если ваши категории достаточно похожи, чтобы вызвать замешательство пользователей или конкурировать друг с другом в поиске, вам может потребоваться внести изменения:
- Если вы устанавливаете категории самостоятельно, мы рекомендуем перенести контент из одной категории в другую и уменьшить общее количество имеющихся категорий.
- Если вы разрешаете пользователям наращивать категории, вы можете не индексировать страницы категорий, созданные пользователем, по крайней мере, до тех пор, пока новые категории не пройдут процесс проверки.

Как запретить Google индексировать поддомены?
Есть несколько способов запретить Google индексировать субдомены:
- Вы можете добавить пароль, используя файл .htpasswd
- Вы можете запретить поисковые роботы с помощью файла robots.txt.
- Вы можете добавить директиву noindex на каждую страницу в субдомене.
- Вы можете 404 все страницы поддоменов
Если ваши поддомены предназначены для разработки, то добавление файла .htpasswd в корневой каталог вашего поддомена — идеальный вариант. Стена входа в систему не позволит сканерам индексировать контент на поддомене, а также предотвратит несанкционированный доступ пользователей.
Примеры использования:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
Использование robots.txt для блокировки индексирования
Если ваши субдомены служат другим целям, вы можете добавить файл robots. txt в корневой каталог вашего субдомена. Затем он должен быть доступен следующим образом:
txt в корневой каталог вашего субдомена. Затем он должен быть доступен следующим образом:
https://subdomain.domain.com/robots.txt
Вам нужно будет добавить файл robots.txt в каждый субдомен, который вы пытаетесь заблокировать для поиска. Пример:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
В каждом случае файл robots.txt должен запрещать поисковые роботы. Чтобы заблокировать большинство поисковых роботов с помощью одной команды, используйте следующий код:
Пользовательский агент: *
Запретить: /
Звездочка * после user-agent: называется подстановочным знаком, она соответствует любой последовательности символов. Использование подстановочного знака отправит следующую директиву запрета всем пользовательским агентам, независимо от их имени, от googlebot до яндекс.
Обратная косая черта сообщает поисковому роботу, что все страницы за пределами поддомена включены в директиву disallow.
Как выборочно заблокировать индексацию страниц поддоменов
Если вы хотите, чтобы некоторые страницы из поддомена отображались в поиске, а другие не отображались, у вас есть два варианта:
- Используйте директивы noindex на уровне страницы
- Используйте директивы запрета на уровне папки или каталога
Директивы noindex на уровне страницы будут более громоздкими для реализации, так как директиву необходимо добавить в HTML или заголовок каждой страницы. Однако директивы noindex не позволят Google индексировать субдомен независимо от того, был ли субдомен уже проиндексирован или нет.
Директивы запрета на уровне каталога проще реализовать, но они будут работать только в том случае, если страницы поддоменов еще не включены в поисковый индекс. Просто обновите файл robots.txt субдомена, чтобы запретить сканирование соответствующих каталогов или подпапок.
Как узнать, не индексированы ли мои страницы?
Случайное добавление страниц с директивой об отсутствии индекса на ваш сайт может иметь серьезные последствия для вашего рейтинга в поиске и видимости в результатах поиска.
Если вы обнаружите, что на странице не отображается органический трафик, несмотря на хорошее содержание и обратные ссылки, сначала проверьте, не заблокировали ли вы случайно поисковые роботы из своего файла robots.txt. Если это не решит вашу проблему, вам нужно будет проверить отдельные страницы на наличие директив noindex.
Проверка наличия NoIndex на страницах WordPress
WordPress упрощает добавление или удаление этого тега на ваших страницах. Первым шагом в проверке наличия nofollow на ваших страницах является простое переключение настройки видимости для поисковых систем на вкладке «Чтение» в меню «Настройки».
Это, скорее всего, решит проблему, однако этот параметр работает как «предложение», а не правило, и часть вашего контента все равно может быть проиндексирована.
Чтобы обеспечить абсолютную конфиденциальность ваших файлов и контента, вам нужно будет сделать последний шаг — либо защитить свой сайт паролем с помощью инструментов управления cPanel, если они доступны, либо с помощью простого плагина.
Аналогичным образом, удалить этот тег из вашего контента можно, сняв защиту паролем и сняв флажок с параметра видимости.
Проверка наличия NoIndex в Squarespace
Страницы Squarespace также легко индексируются с помощью функции внедрения кода платформы. Как и WordPress, Squarespace можно легко заблокировать от обычного поиска с помощью защиты паролем, однако платформа также не рекомендует предпринимать этот шаг для защиты целостности вашего контента.
Добавляя строку кода NoIndex на каждую страницу, которую вы хотите скрыть от поисковых систем в Интернете, и на каждую подстраницу под ней, вы можете обеспечить безопасность защищенного контента, доступ к которому должен быть запрещен. Как и на других платформах, удалить этот тег также довольно просто: просто использовать функцию внедрения кода для возврата кода — это все, что вам нужно сделать.
Squarespace уникален тем, что его конкуренты предлагают эту опцию в первую очередь как часть набора настроек в инструментах управления страницами. Squarespace уходит отсюда, позволяя персонально манипулировать кодом. Это интересно, потому что вы можете видеть изменения, которые вы вносите в контент своей страницы, в отличие от других в этом пространстве.
Squarespace уходит отсюда, позволяя персонально манипулировать кодом. Это интересно, потому что вы можете видеть изменения, которые вы вносите в контент своей страницы, в отличие от других в этом пространстве.
Проверка наличия NoIndex на Wix
Wix также позволяет быстро и просто исправить проблемы с NoIndexing. В настройках «Меню и страницы» вы можете просто отключить опцию «Показывать эту страницу в результатах поиска», если вы хотите, чтобы NoIndex не индексировал одну страницу вашего сайта.
Как и его конкуренты, Wix также предлагает паролем защиту ваших страниц или всего сайта для дополнительной конфиденциальности. Однако Wix отличается от других тем, что служба поддержки не предписывает параллельные действия на обоих фронтах для защиты контента от сканера. Wix особо отмечает разницу между скрытием страницы из вашего меню и скрытием ее из критериев поиска.
Это особенно полезный совет для менее опытных разработчиков веб-сайтов, которые могут изначально не понимать разницы, учитывая, что удаление из меню вашего сайта делает страницу недоступной с сайта, но не по разумному поисковому запросу Google.
Как закрыть ссылки от индексации. Тег nofollow и тег niondex
Всем привет! Сегодня на SEO-mayak.com я расскажу как закрыть ссылки от индексации.
Готовясь к нависанию статьи, я перечитал много разных блогов и понял, что сколько людей, столько и мнений.
Я просто не завидую новичкам, которые ищут ответ на вопрос, как правильно закрывать ссылки.
Непонятно, то ли использовать только один тег nofollow, то ли оба тега вместе, а некоторые веб-мастера считают, что уже нет смысла в закрывании ссылок, так как поисковики все равно игнорируют запреты.
В общем дискуссии идут жаркие, которые создают столько «мутной воды» и кажется, что все с ума посходили, пытаясь докопаться до истины. Я тоже поначалу запутался и решил обратиться к справочникам самих поисковых систем.
Значение и применение nofollow
Почему nofollow относят к тегам? На самом деле это никакой не тег, изначально он был атрибутом для мета тега robots, и распространял запрет индексации ссылок на уровне всей страницы, например:
<meta name="robots" content="nofollow" />
С тех пор много воды утекло и nofollow уже не так часто используют на уровне всей страницы, зато значение nofollow для атрибута rel применяют теперь повсеместно. Но как в России бывает, «кличка»
Но как в России бывает, «кличка»
Для новичков показываю, как правильно закрыть ссылку атрибутом rel=“nofollow“:
<a href="site.com" rel="nofollow"> Текст ссылки</a>
И все же, закрывает ли атрибут rel=“nofollow“ ссылки от индексации? Можете прочитать об этом в справке Google. От себя могу сказать следующее:
Атрибут rel=“nofollow“ запрещает роботу следовать по ссылке, т.е. разрывает связку донор-акцептор. Если связки нет, то PageRank акцептору не передается. НО! Ссылка, на странице донора, прекрасно индексируется поисковыми системами.
Если вспомнить формулу расчета PageRank, то из нее следует, что вес, передаваемый по ссылке, равен весу страницы донора, деленному на все ссылки со страницы. Т.е. вес, который предается по ссылкам с донора, передается и по ссылке с атрибутом nofollow. Только в данном случае перетекает в никуда, вместо того, что бы найти себе полезное применение на сайте.
Но как же Яндекс относится к «буржуйскому» атрибуту? Передается ли по ссылке, помеченной nofollow, показатель Яндекса ВИЦ (взвешенный индекс цитирования) мне неизвестно, так как формула расчета ВИЦ является тайной Яндекса, которая храниться за семью печатями. Но если Яша рекомендует закрывать ненадежные ссылки (спам ссылки) rel=“nofollow“, то из этого можно сделать вывод, что робот Яндекса учтет данные ему «рекомендации» и перехода по ссылке не будет.
Неужели никак нельзя закрыть ссылку от индексации, чтобы вес страницы никуда не утекал? Можно, но делается это с помощью jQuery AJAX.
Особенно важно закрывать все внешние ссылки для сайтов, которые находятся еще в песочнице, чтобы не отдавать свой «детский» вес, а наоборот стараться накапливать его. Всегда проверяйте шаблон на скрытые внешние ссылки и используйте плагин ТАС для обнаружения закодированных ссылок, вида base64 decode.
У многих новичков наверное возник вопрос. Что такое вес страницы? Я обязательно на него отвечу, но уже в другой раз, так что советую подписаться на обновления блога.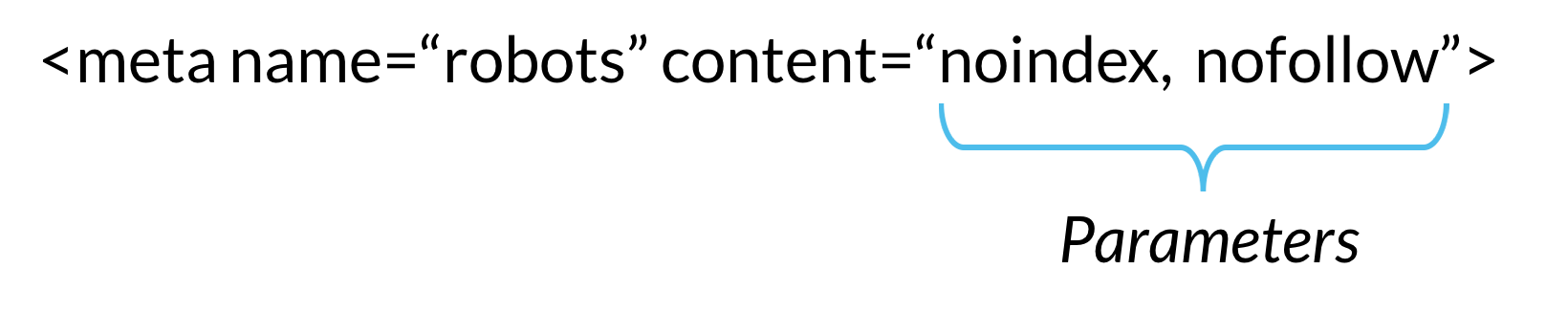
Подошла очередь рассказать о теге noindex, ведь это детище нашего родного Яндекса, которого мы все так любим 🙂
Применение тега noindex
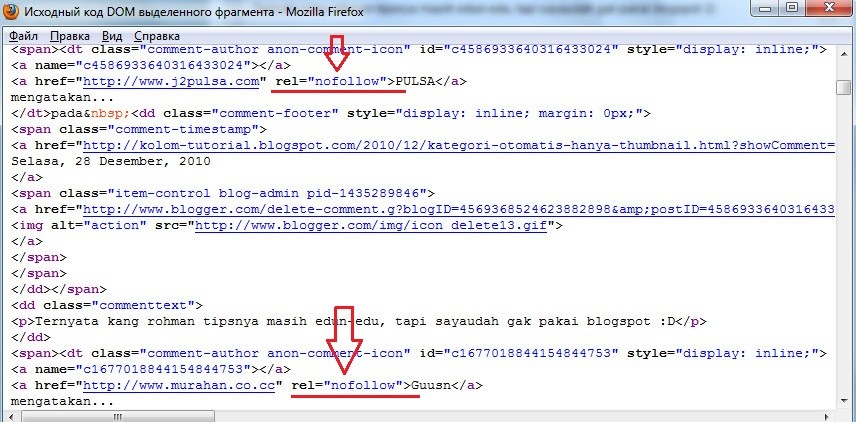
В начале статьи я уже писал о всеобщем «умопомешательстве» при обсуждении nofollow и noindex и в подтверждение своих слов могу привести ситуацию с закрытием тегом noindex имен (анкоров) комментаторов на блогах.
Ведь и я недавно полагал, что заключая ссылку на сайт комментатора в тег noindex, я тем самым запрещаю роботу Яндекса индексировать эту ссылку и переходить по ней, передовая вес страницы.
Но как я уже писал выше, Яша прекрасно распознает атрибут rel=“nofollow“ и использования noindex закрывает только текст (анкор). Следовательно заключать ссылки в тег niondex, совершенно ненужное и бесполезное занятие.
С помощью тега noindex можно закрывать от индексирования участки текста в контенте, которые являются не уникальными, анкоры ссылок, но никак не сами ссылки.
Теперь немного затрону понятие валидности тега noindex. Вообще это довольно обширная тема и я в будущем посвящу ей отдельную статью.
Вообще это довольно обширная тема и я в будущем посвящу ей отдельную статью.
Дело в том, что распространенное написания тега noindex не проходит валидность. Приведу такой пример:
<noindex>текст, который надо закрыть от индексации</noindex>
Так вот, такое написание тега не пройдет валидацию, а Google вообще об этом теге ничего неизвестно.
После шумихи на разных форумах специалисты Яндекс нашли выход из сложившийся ситуации и предложили изменяемое написание тега, которое выполняя те же функции, является валидным.
Валидное написание тега noindex выглядит так:
<!--noindex-->текст, который надо закрыть от индексации<!--/noindex-->
Для новичков скажу, что тег noindex является парным и использовать его надо только так, как показано на примере.
До встречи!
С уважением, Виталий Кириллов
Как закрыть ссылку от индексации? Тег noindex и nofollow
Здравствуйте, гости и читатели блога nazyrov. ru. С вами снова Андрей Назыров. И в этой статье я расскажу, как правильно закрыть ссылку от индексации поисковых систем.
ru. С вами снова Андрей Назыров. И в этой статье я расскажу, как правильно закрыть ссылку от индексации поисковых систем.
Зачем закрывать внешние ссылки от индексации думаю объяснять не нужно. Несмотря на то, что Яндекс отменил АГС, он все же ранжирует ниже блоги, с которых идет большое количество внешних ссылок.
Честно говоря, я очень удивлен. Оказывается, многие не знают, как закрыть ссылку. А если и слышали о теге <noindex> и атрибуте rel= «nofollow», то не знают их точное предназначение. Давайте все-таки определимся, что это за теги и с чем их едят. Для этого обратимся к самим поисковикам и к знаменитой Википедии.
Тег <noindex>
Тег <noindex> это создание Яндекса. Он создан как альтернатива атрибуту rel= «nofollow». Тег указывает поисковой системе Яндекс, что определенный участок веб-страницы, который помещен между этими тегами, не следует индексировать.
Обратите внимание, я написал определенный участок веб-страницы, а не ссылку. При использовании тега noindex, Яша не индексирует только анкор (текст), а саму ссылку он будет индексировать как и прежде.
В этом можно убедиться, увидев ссылку в Яндекс-Вебмастере. Я таких экспериментов не проводил, но об этом говорят люди, которым можно доверять на все 100%.
Яндекс-Вебмастер в разделе «Входящие ссылки» тоже никак не упоминает про noindex
Очень важный момент – noindex определяет только Яндекс. Google же на него никак не реагирует, и продолжает индексировать все, что помещено в эти теги.
Вот пример ссылки расположенной в теги noindex:
<noindex><a href="http://nazyrov.ru/">Блог Андрея Назырова</a></noindex>
У noindex есть еще один минус. В связи с тем, что он не входит в официальную спецификацию HTML, большинство валидаторов его считают ошибкой. Этого можно избежать, если использовать тег в другой конструкции — <!—noindex—>
Вот пример ссылки с использованием такой конструкции:
<!--noindex--><a href="http://nazyrov.
 ru/">Блог Андрея Назырова<!--/noindex-->
ru/">Блог Андрея Назырова<!--/noindex-->Исходя из этого, можно сделать вывод:
Тег noindex следует использовать только для скрытия неуникального текста, чтобы Яндекс его не считал за копипаст. В закрытии же ссылок от индексации он бесполезен.
Атрибут rel= «nofollow»
rel=”nofollow” создан для того, чтобы запретить роботам переходить по ссылкам. Следовательно ссылки с атрибутом rel=”nofollow” не передают вес страницы.
Этот атрибут видит и Google и Яндекс. Яша в отличие от Google стал различать этот атрибут не так давно. Впервые он перестал учитывать вес ссылки, имеющей этот атрибут в мае 2010 года.
Но идеального ничего не бывает. На многих SEO форумах не перестают утихать дебаты о индексировании ссылок с атрибутом nofollow. Связано это вот с чем:
- В связи с тем, что процесс индексации и расчёта веса страницы идет отдельно, некоторые ссылки содержащие атрибут nofollow, могут отображаться в панели вебмастера Яндекс и Google.
- Быстроробот Яндекса обычно тоже индексирует все ссылки, несмотря ни на какие теги. Но при последующем обновлении, они исчезнут.

Вот пример ссылки с использованием атрибута rel= «nofollow»:
<a href="http://nazyrov.ru/" rel="nofollow">Блог Андрея Назырова</a>
Для себя я сделал следующий вывод:
- Ссылки определенно закрывать надо. Это напрямую влияет на авторитетность веб-ресурсов и частично на поисковую выдачу.
- Закрывать ссылки нужно при помощи атрибута rel=”nofollow”.
- Нужно регулярно проверять блог на наличие исходящих и битых ссылок.
Ждите новых статей!
Страницы с тегом noindex (запрещенные к индексированию в Яндекс)
Для чего нужен элемент noindex
Тег <noindex> используется для запрета индексации служебных участков текста. Данный тег может находиться в любом участке HTML-кода страницы, учитывается он только Яндексом. Google и другие поисковые системы будут его игнорировать.
Работает этот элемент аналогично МЕТА-тегу noindex, но распространяется исключительно на текстовый контент, который размещен на странице, то есть, закрыть от индексации ссылки с его помощью не получится.
Приведем пример использования:
<noindex>служебный текст, который не нужно индексировать</noindex>
И еще один верный вариант:
<!--noindex-->служебный текст, который не нужно индексировать<!--/noindex-->
В каких случаях можно употреблять
При ответе на этот вопрос важно уточнить, что же такое индексация. Это процесс анализа информации на web-ресурсе и последующее добавление ее в индекс (базу данных поисковых систем) для формирования поисковой выдачи по релевантным запросам. Соответственно, тегом noindex мы советуем закрывать ту информацию, которая не должна участвовать в процессе ранжирования и отображаться в поисковой выдаче, но при этом не содержит ничего, за что можно получить санкции от Яндекса. Например, это может быть мобильный номер телефона, который не должен отображаться в выдаче, но нужен пользователям на страницах сайта.
Например, это может быть мобильный номер телефона, который не должен отображаться в выдаче, но нужен пользователям на страницах сайта.
Нужно учитывать еще один важный фактор — тег noindex запрещает Яндексу индексировать участок текста, но не устанавливает запрет на его чтение. То есть, применять данный элемент для сокрытия скопированных с других ресурсов текстов не получится, так как плагиат все равно будет обнаружен, и сайт подвергнется пессимизации.
Как обнаружить страницы с этим тегом на сайте
При продвижении очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку часть важной информации могла быть закрыта от индексации или другие оптимизаторы использовали этот тег не по назначению.
Сервис Labrika предлагает удобный отчет по страницам с тегом <noindex>. Найти его можно в подразделе «Страницы с тегом noindex» раздела «SEO-аудит» в левом боковом меню:
В этом отчете содержится информация обо всех страницах вашего сайта, на которых находится тег <noindex>. Выглядит он следующим образом:
Выглядит он следующим образом:
Для того, чтобы воспользоваться отчетом и получить актуальную на данный момент информацию, необходимо обновить SEO-аудит. Сделать это можно с помощью соответствующей кнопки прямо на странице отчета:
Способы влияния на индексацию страниц в Яндекс и Google
Иногда веб-мастеру необходимо запретить индексацию страницы целиком или ее части. Например, Вы не хотите чтобы на вашем сайте индексировалась реклама, блок ссылок или страницы с результатами поиска. В данной статье я постарался собрать все методы влияющие на индексацию в поисковых системах Яндекс и Google.
Контроль индексации в Яндекс
Файл robots.txt
С помощью данного файла администратор может ограничить доступ роботов поисковых систем как к части сайта так и к отдельным страницам.
Пример 1:
User-agent: *
Disallow: /basket.php В этом примере мы запретили, роботам обращение к скрипту корзины Интернет-магазина. * — обозначает что данное правило применимо ко всем роботам.
* — обозначает что данное правило применимо ко всем роботам.Яндекс поддерживает диррективу Host в файлах robots.txt, это позволяет указать поисковику главное зеркало сайта, которое и будет отображаться в результатах поиска.
Пример 2:
User-agent: Yandex
Disallow: /basket.php
Host: www.site.ru либо
User-agent: Yandex
Disallow: /basket.php
Host: site.ruВ первом случае мы указали главным домен www.site.ru, во втором site.ru.
Пример 3:
User-Agent: *
Disallow: /В этом примере роботу полностью запрещен обход сайта.
<a rel=»nofollow»>
Используя атрибут rel=»nofollow», мы запрещаем поисковику переход по ссылке и утекание «веса» страницы.
PS: Данный атрибут также поддерживают роботы Google, Bing и Yahoo.
Тег <—noindex—>
Ранее веб-мастерам приходилось использовать невалидный тег <noindex> для запрета индексации части страницы для роботов Яндекса, но по многочисленным просьбам Яндекс сделал валидную версию данного тега — <—noindex—>. Для запрета индексации куска текста или html кода заключите его между открывающим и закрывающим тегами noindex.
Для запрета индексации куска текста или html кода заключите его между открывающим и закрывающим тегами noindex.
Пример:
<--noindex-->Этот текст не индексирует Яндекс!</--noindex-->Контроль индексации в Google
Google, как и Яндекс поддерживает атрибут rel=»nofollow» у ссылок и файлы robots.txt, за исключением диррективы Host. Указать главное зеркало можно через Инструменты Google для веб-мастеров
Теги googleoff/googleon для контроля индексирования частей страниц
С помощью тегов googleoff/googleon мы можем запретить роботу индексировать часть страницы или блок ссылок. Существует 4 вида тегов. Я рассмотрю их на конкретных примерах, чтобы Вам было ясно о чем идет речь.
Пример 1:
аквариумные <!--googleoff: index-->рыбки<!--googleon: index--> неплохо размножаютсяВ результате слова «аквариумные» и «нелохо размножаются» проиндексируются, а вот слово «рыбки» нет.
Пример 2:
<!--googleoff: anchor--><a href="razdaem-slonov. html">раздаем слонов</a><!--googleon: anchor--> html">раздаем слонов</a><!--googleon: anchor-->
html">раздаем слонов</a><!--googleon: anchor-->В этом примере у нас не проиндексируется текст ссылки, следовательно, при поиске по словосочетанию «раздаем слонов» документ razdaem-slonov.html не появится в результатах поисковой выдачи.
Пример 3:
<!--googleoff: snippet-->Меня не видно!<!--googleon: snippet-->Текст расположенный между открывающим и закрывающим тегами с атрибутом snippet не будет отображаться в результатах выдачи, но будет проиндексирован.
Пример 4:
<!--googleoff: all-->Меня не видно!<!--googleon: all-->Последний пример — это комбинация трех предыдущих.
UPD: Как выяснилось теги googleoff/googleon работают только для Google Search Appliance и Google Mini, но не для обычного поиска Google.
Теги <!— google_ad_section_start—>, <!— google_ad_section_end—>
Данные теги пригодятся для веб-мастеров размещающих на своих сайтах рекламу Google Adsense. Они сообщат боту Adsense какой контент является более релевантным на странице.
Они сообщат боту Adsense какой контент является более релевантным на странице.
Возможно я что-то пропустил в своем обзоре. Если у Вас есть дополнения или замечания, пишите комментарии и я дополню данную статью.
Метатег robots и HTTP-заголовок X-Robots-Tag
Вы можете указать роботам правила загрузки и индексирования определенных страниц сайта одним из способов:прописать метатег robots в HTML-коде страницы в элементе head;
настроить HTTP-заголовок X-Robots-Tag для определенного URL на сервере вашего сайта.
По умолчанию метатег и заголовок учитываются поисковыми роботами. Можно указать директивы для определенных роботов.
- Поддерживаемые Яндексом директивы
- Указание нескольких директив
- Указания для определенных роботов
Разрешающие директивы используются роботом по умолчанию, поэтому их можно не указывать, если нет других директив. В сочетании с запрещающими директивами разрешающие имеют приоритет. Пример.
В сочетании с запрещающими директивами разрешающие имеют приоритет. Пример.
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Пример:
Запись, которая запрещает индексирование страницы.
<html>
<head>
<meta name="robots" content="noindex" />
</head>
<body>...</body>
</html>HTTP-ответ, где заголовок запрещает индексирование страницы.
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
X-Robots-Tag: noindexВы можете указать директивы через запятую.
<meta name="yandex" content="noindex, nofollow" />Вы можете передать несколько заголовков в одном ответе, а также перечислить директивы через запятую.
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
X-Robots-Tag: noindex, nofollow
X-Robots-Tag: noarchiveЕсли для робота Яндекса указаны противоречивые директивы, то он учтет положительное значение. Пример с директивами метатега:
<meta name="robots" content="all"/>
<meta name="robots" content="noindex, follow"/>
<!--Робот выберет значение all, текст и ссылки будут проиндексированы.-->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->Указать директиву только для роботов Яндекса можно с помощью метатега robots. Пример:
<meta name="yandex" content="noindex" />Если вы перечислите общие директивы и директивы для роботов Яндекса, то поисковая система учтет все указания.
<meta name="robots" content="noindex" />
<meta name="yandex" content="nofollow" />Такие директивы робот Яндекса воспримет как noindex, nofollow.
Руководство по индексированию и сканированию с помощью Spotibo
Может ли поисковая система сканировать ваш сайт? Все ли страницы разрешены для сканирования? Если нет, то к каким URL поисковые системы не обращаются и почему это происходит?
На это может повлиять редактирование директив индексации на вашем сайте. Во-первых, в файле robots.txt, а во-вторых, в метатегах robots в HTML-теге
или в HTTP-заголовке каждой страницы. Прежде чем анализировать и устранять проблемы, позвольте мне рассказать вам об основах сканирования и индексирования. Сканирование
Прежде чем поисковая система попадет на ваш сайт, она проверяет файл robots. txt. Прежде всего, он проверяет, разрешено ли сканирование всех страниц вашего сайта. По сути, вы можете добавить любые страницы или части сайта, которые вы не хотите сканировать. Это означает, что если вы запретите страницы с URL-путем /user/, движок пропустит их.
txt. Прежде всего, он проверяет, разрешено ли сканирование всех страниц вашего сайта. По сути, вы можете добавить любые страницы или части сайта, которые вы не хотите сканировать. Это означает, что если вы запретите страницы с URL-путем /user/, движок пропустит их.
Разработчики и SEO-специалисты обычно используют файл robots.txt для оптимизации краулингового бюджета. Обезопасить бюджет действительно важно только для крупных сайтов с миллиардами URL-адресов.Небольшие и средние веб-сайты с сотнями или тысячами URL-адресов не должны иметь проблем со сканированием, поэтому вам может вообще не понадобиться использовать файл robots.txt для вашего сайта.
Индексирование
После того, как поисковая система посещает страницу, она проверяет мета-директивы роботов. Эти директивы, естественно, позволяют индексировать и следить за страницей. Но если возникнет необходимость, вы можете изменить его и указать поисковой системе поступать иначе, используя директивы мета-роботов noindex и nofollow. В этом случае поисковая система будет соблюдать эти директивы, и ваша страница не будет индексироваться или отслеживаться.
В этом случае поисковая система будет соблюдать эти директивы, и ваша страница не будет индексироваться или отслеживаться.
С помощью Spotibo вы можете автоматически получать результаты для следующих проблем со сканированием и индексированием:
Страницы заблокированы robots.txt
Почему возникает ошибка?
В файле robots.txt есть запрещенные страницы, что указывает поисковым роботам на то, что эти URL-адреса не могут быть просканированы.
Как это влияет на SEO?
Высокая важность: ★★★
Если сканерам не разрешено сканировать URL-адрес и запрашивать его содержимое, содержимое и ссылки в URL-адресе не будут анализироваться.Следовательно, страница не сможет ранжироваться, и любые сигналы авторитета будут потеряны.
Органический трафик, приходящий на страницы, запрещенные в robots.txt, может уменьшиться до нуля. Неосторожное использование файла robots.txt может привести к тому, что весь веб-сайт пропадет в поисковой выдаче.
Как исправить
- В Dashboard откройте вопрос Страницы заблокированы robots.txt .
- После нажатия вы попадете в раздел Explorer , где вы можете отфильтровать и сгруппировать данные по мере необходимости.
- После открытия таблицы с запрещенными URL-адресами проверьте, есть ли какие-либо страницы, которые вы хотите сделать доступными для пользователей. Если да, разрешите их в файле robots.txt.
Пример использования robots.txt:
Файл Robots.txt находится по адресу http://yourdomain.com/robots.txt. Содержит информацию в таком виде:
Имя поискового бота, к которому применяются директивы. «*» означает для всех двигателей. | Агент пользователя: * |
URL-адреса, которые вы хотите заблокировать для сканеров, например, все, страницы администратора на www.domain. | Запретить: /admin/ |
Другие URL для запрета. Например, все страницы с параметрами «поиск», относящиеся к сайту. | Запретить: *?поиск |
 com/admin/
com/admin/Узнайте больше о том, как работать с директивами и синтаксисом, таким как «*» и «$», и избегать критических ошибок в robots.текстовый файл.
Расширенный совет:
Если Spotibo обнаружил страницы на вашем сайте как запрещенные в файле robots.txt, проверьте еще раз, есть ли для этого причина.
Вы можете использовать директивы disallow в файле robots.txt, если вам нужно уменьшить бюджет сканирования или если вы хотите скрыть некоторые страницы, например личные, временные, страницы с кодом и скриптом.
Примеры, когда что-то может пойти не так:
- Если добавить в robots.txt Disallow: /, (ваша домашняя страница не может быть просканирована)
- Если вы запрещаете старый домен при переходе на новый домен
- Если вы запретите перенаправление страниц
Использование роботов. txt не так прост. Это работа для SEO-специалиста или разработчика. Во многих случаях лучшим решением может быть использование noindex, canonical или перенаправления. Поэтому проконсультируйтесь с ним, прежде чем вносить какие-либо изменения.
Примечание : Вы не должны использовать robots.txt, чтобы скрыть свои веб-страницы от результатов поиска, потому что ваша страница все равно может попасть в результаты поиска. Если вы хотите заблокировать страницу из результатов поиска, используйте мета-директивы noindex для роботов.
Страницы с тегом noindex
Почему возникает ошибка?
Обнаружены страницы, содержащие noindex в метатеге robots или в HTTP-заголовке X-Robots-Tag.Эти теги указывают сканерам поисковых систем, что эти URL-адреса не должны индексироваться, поэтому они не будут отображаться в поисковой выдаче.
По умолчанию для веб-страницы задан индекс. Атрибуты «Noindex» на найденных страницах, вероятно, были добавлены вручную, поэтому, возможно, у вас есть причина использовать их в отношении SEO.
Как это влияет на SEO?
Высокая важность: ★★★
Все страницы с атрибутом noindex исключены из индекса поисковых систем. Поскольку эти страниц вообще не отображаются в результатах поиска , это может привести к падению органического трафика.
Как исправить
- На панели управления откройте страницы задач с тегом noindex.
- После нажатия вы попадете в раздел проводника, где вы можете отфильтровать и сгруппировать URL-адреса по своему усмотрению.
- После открытия таблицы с URL-адресами, содержащими noindex, проверьте все эти страницы на предмет внутренней структуры вашего веб-сайта. Посмотрите, есть ли страницы, которые вы хотите сделать доступными для пользователей. Если есть какие-либо страницы или части вашего сайта, которые должны быть доступны посетителям из поисковых систем, вам необходимо разрешить индексацию, отредактировав тег в мета-роботах или в заголовке HTTP.
Чтобы поисковые системы индексировали вашу страницу, просто добавьте следующее в раздел HTML-кода конкретной страницы:
 текстовый файл. Если страница заблокирована через файл robots.txt, поисковая система не может просканировать и увидеть атрибут noindex, поэтому она не знает, что они не должны оставлять страницу вне индекса.
текстовый файл. Если страница заблокирована через файл robots.txt, поисковая система не может просканировать и увидеть атрибут noindex, поэтому она не знает, что они не должны оставлять страницу вне индекса.Чтобы быть уверенным, проверьте это на Spotibo:
- Добавить фильтр.
- Включить доступ поисковой системы для любого бота Nocrawl (robots.txt).
Страницы с тегом nofollow
Почему возникает ошибка?
Существуют страницы, содержащие «nofollow» в метатегах robots или в HTTP-заголовке X-Robots-Tag, что указывает поисковым роботам на то, что ссылки на этих URL-адресах не должны переходить.
Примечание : использование тега nofollow является общим как для HTML-страниц, так и для ссылок. Но в данном конкретном случае мы имеем в виду только мета-директивы роботов HTML-страницы.
Как это влияет на SEO?
Средне-высокая важность: ★★☆
Если вы используете атрибут nofollow на странице, поисковые системы не проходят по ссылкам и не пропускают ссылочный вес . Поскольку поисковые системы дальше не переходят по ссылкам, они не сканируют связанные страницы, и если нет других внутренних или внешних ссылок, указывающих на эти страницы, то они не будут проиндексированы.Неосторожное использование nofollow может привести к падению всего сайта в поисковой выдаче.
Поскольку поисковые системы дальше не переходят по ссылкам, они не сканируют связанные страницы, и если нет других внутренних или внешних ссылок, указывающих на эти страницы, то они не будут проиндексированы.Неосторожное использование nofollow может привести к падению всего сайта в поисковой выдаче.
Как исправить
- На панели инструментов откройте задачу Страницы с тегом nofollow .
- Вы окажетесь в таблице Explorer, где сможете фильтровать и группировать URL-адреса.
- Проверьте все страницы, содержащие nofollow, относительно внутренней структуры вашего веб-сайта. Если есть какие-либо страницы, которые вы не хотите помечать атрибутом nofollow, перепишите их, чтобы они следовали.
Чтобы заставить поисковые системы следить за вашей страницей, просто добавьте следующее в раздел HTML-кода конкретной страницы:
 Ссылка на страницу может появляться на других внутренних страницах или даже на внешних веб-сайтах, поэтому они все равно могут быть найдены поисковыми системами и проиндексированы. Ссылка nofollow не удаляет страницу из индекса. Для этого вместо этого используйте атрибут noindex.
Ссылка на страницу может появляться на других внутренних страницах или даже на внешних веб-сайтах, поэтому они все равно могут быть найдены поисковыми системами и проиндексированы. Ссылка nofollow не удаляет страницу из индекса. Для этого вместо этого используйте атрибут noindex.CSS заблокирован robots.txt
Почему возникает ошибка?
Файлы CSS запрещены в файле robots.txt на вашем веб-сайте.
Как это влияет на SEO?
Средне-высокая важность: ★★☆
Запрещая CSS в файле robots.txt, вы не позволяете сканерам поисковых систем отображать весь контент и проверять, правильно ли работает ваш сайт. Сканеры не могут полностью понять ваш сайт, что может привести к снижению рейтинга.
Как исправить
- В Dashboard открыта проблема CSS заблокирован robots.txt .
- В таблице Explorer вы можете увидеть затронутые URL-адреса.
- Для решения этой проблемы вам просто нужно разрешить поисковым роботам доступ к файлам CSS в файле robots. txt.
 txt.
txt. Файл Robots.txt находится по адресу: http://yourdomain.com/robots.txt. Блокировка CSS может выглядеть так:
Disallow: / css
Или, если вы используете сайт WordPress, вы можете увидеть его так:
Disallow: /wp-admin
Disallow: /wp-includes/
Disallow: /wp-content/
Чтобы решить эту проблему, удалите либо /css в исходном коде, либо /wp-includes/ и /wp-content/ в разделе SEO сайта WordPress.
JavaScript заблокирован robots.txt
Почему возникает ошибка?
Файлы JavaScript запрещены в файле robots.txt на вашем веб-сайте.
Как это влияет на SEO?
Средне-высокая важность: ★★☆
Запрещая JavaScript в файле robots.txt, вы можете запретить роботам поисковых систем отображать весь контент и проверять, правильно ли работает ваш веб-сайт. Это действие может стать существенной проблемой для веб-сайтов, построенных на JavaScript.Сканеры не могут полностью понять ваш сайт, и это может привести к снижению рейтинга.
Это действие может стать существенной проблемой для веб-сайтов, построенных на JavaScript.Сканеры не могут полностью понять ваш сайт, и это может привести к снижению рейтинга.
Как исправить
- В Dashboard открытая проблема JavaScript заблокирован robots.txt.
- В таблице проводника вы можете увидеть затронутые URL-адреса.
- Убедитесь, что все заблокированные файлы JS не оказывают отрицательного влияния на отрисовку страницы. Если это так, вам следует разрешить поисковым роботам доступ к JS в файле robots.txt.
Файл Robots.txt находится по адресу: http://yourdomain.com/robots.txt. Блокировка JS может выглядеть так:
Disallow: /js
Или, если вы используете сайт WordPress, вы можете увидеть его так:
Disallow: /wp-admin
Disallow: /wp-includes/
Disallow: /wp-content/
Чтобы решить эту проблему, удалите либо /js в исходном коде, либо /wp-includes/ и /wp-content/ в разделе SEO сайта WordPress.
Дополнительные технические руководства по SEO:
Что означает метатег «NoIndex»?
Для упрощения это означает, что если вы используете метатег noindex, поисковые системы не будут индексировать эту страницу, и она не будет отображаться в результатах поиска. Тем не менее, он по-прежнему будет доступен пользователям на вашем веб-сайте через внутренние ссылки или навигационные меню.
Это предотвращает путаницу со стороны пользователя, но при этом позволяет странице существовать.
Теги Noindex и Nofollow
Вам может быть интересно: «В чем разница между тегами noindex и тегами nofollow?»метатег nofollow?»
Метатег noindex указывает поисковой системе, такой как Google, не индексировать страницу. Google по-прежнему может сканировать страницу, но не добавит ее в свой индекс и не отобразит на странице результатов поисковой системы (SERP).
Метатег nofollow указывает роботу поисковой системы не сканировать ссылки на странице и не передавать какой-либо ссылочный вес. Страница по-прежнему может быть проиндексирована и будет отображаться в поисковой выдаче.
Страница по-прежнему может быть проиндексирована и будет отображаться в поисковой выдаче.
Когда использовать метатег Noindex
Итак, зачем вам использовать метатег noindex? Какой цели это служит? И полезно это или вредно для SEO? Ниже несколько случаев, когда использование тега noindex полезно.
Guest Author Archives
Во-первых, теги noindex отлично подходят для использования, когда страница необходима для вашего сайта, но не должна быть найдена пользователями в результатах поиска. Например, если у вас есть страница со списком 100 авторов гостевых постов на вашем веб-сайте, эта страница, вероятно, не имеет значения для пользователей. В большинстве случаев сайты будут использовать метатеги noindex или канонические теги для этого конкретного типа контента.
Суть в том, что эти страницы не имеют отношения к вашей нише или стратегии публикации в блоге, поэтому практически эти страницы не должны индексироваться или появляться в результатах поиска.Эти страницы более ценны для внутренней организации для вас как веб-мастера вашего сайта, чем для пользователей.
Платные целевые страницы
Другой пример использования тега noindex — это платная целевая страница. Добавление тега noindex не позволяет поисковым системам приводить пользователей на страницу, поскольку предполагается, что она доступна только вашей платной аудитории. Вы не хотите, чтобы данные обычного поиска объединялись с вашими платными данными. У платных целевых страниц есть определенная цель — люди, которые заплатили за просмотр контента, и они не предназначены для ранжирования в Google.
Страницы категорий и страницы тегов
Другой пример использования тега noindex — страницы категорий или тегов блога. На этих страницах различные сообщения в блогах разделяются на определенные предопределенные категории и перечислены все статьи в этой конкретной категории. Вы также можете поместить страницы администратора и входа в это ведро.
Эти страницы также полезны для внутренней организации, но их не нужно показывать на странице результатов поисковой системы.
Тестирование или изменение дизайна страниц
Иногда вам нужно протестировать или изменить дизайн страницы на вашем веб-сайте.Это отличный пример использования тега noindex. Вы не хотите, чтобы пользователи в поисковой выдаче нашли страницу, которая не завершена или находится в процессе изменения дизайна. Использование тега noindex предотвратит отображение страницы в поисковой выдаче.
Как видите, иногда теги noindex могут пригодиться!
Как деиндексировать страницу с помощью метатега Noindex
Если вы видите нежелательный метатег noindex на карте сайта, вы можете легко изменить его. С другой стороны, вы также можете быстро добавить тег noindex.Мы покажем тебе как!
Чтобы добавить или изменить тег noindex, вам потребуется доступ к файлу robots.txt или HTML-коду. Если вы еще не создали файл robots.txt, это можно сделать с помощью бесплатного генератора robots.txt.
Получив доступ к исходному HTML-коду страницы, которую вы не хотите индексировать, вы можете скопировать и вставить нужный тег в раздел
(или удалить его, чтобы удалить).
Или вы можете обновить файл robots.txt, если хотите добавить или удалить теги на нескольких страницах.
Преимущества тегов Noindex
Давайте рассмотрим некоторые преимущества использования метатегов noindex на вашем веб-сайте.
- Предотвращает путаницу. Использование тегов noindex на страницах, которые не представляют ценности для пользователей, предотвратит путаницу в результатах поиска как для пользователей, так и для поисковых систем. Страницы, к которым пользователям не нужно обращаться и которые не представляют большой ценности, не должны индексироваться.
- Поддерживает организацию. Теги Noindex помогают поддерживать внутреннюю организацию вашего веб-сайта с такими страницами, как архивы авторов, страницы категорий или страницы благодарности.
- Усиливает SEO вашего сайта. В некоторых случаях меньшее количество страниц для индексации роботами поисковых систем может помочь укрепить ваш сайт. Он четко формулирует для Google иерархию вашего сайта и передает важность определенных страниц. Если у вас слишком много страниц, которые поисковые системы могут сканировать и индексировать, глубина сканирования ботов может быть перегружена.
 Если у вас слишком много страниц, которые поисковые системы могут сканировать и индексировать, глубина сканирования ботов может быть перегружена.
Если у вас слишком много страниц, которые поисковые системы могут сканировать и индексировать, глубина сканирования ботов может быть перегружена.Использование тегов noindex на вашем веб-сайте может быть полезным для вашего сайта во многих различных ситуациях.
Надеюсь, эта статья помогла вам лучше понять теги noindex и их назначение.Для получения дополнительной информации о метаданных прочитайте наши сообщения в блоге о мета-описаниях и мета-тегах title!
Различия между nofollow и noindex
Правила noindex и nofollow в ссылках могут улучшить или разрушить страницу и то, как она индексируется. Большую часть времени они используются вместе, но иногда они рассматриваются как взаимозаменяемые или полностью неправильно используемые.
Итак, как правильно их использовать и когда?
Обе эти настройки являются атрибутами, которые можно добавить к ссылкам, чтобы помочь поисковым роботам.Итак, во-первых, их определения:
Что такое nofollow?
nofollow показывает, что ссылка не должна использоваться для передачи авторитета или чего-либо еще для ранжирования страницы.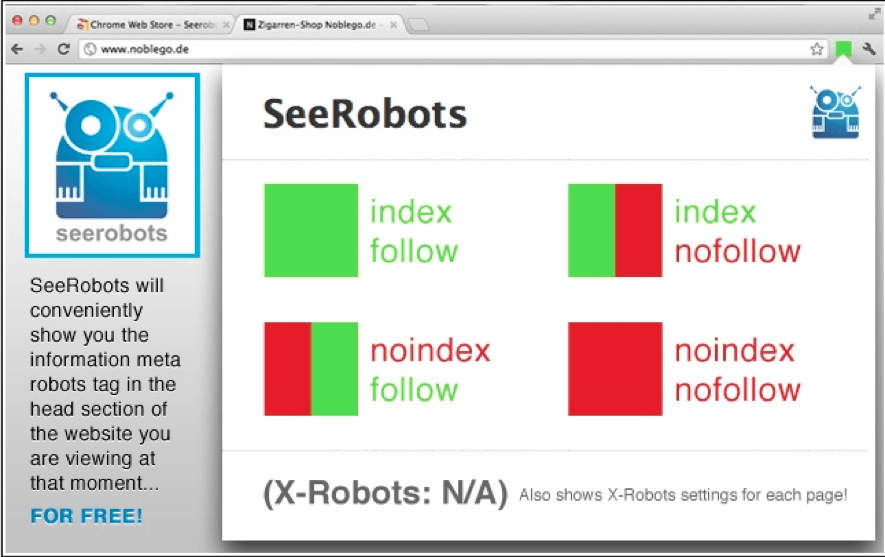 Если мы используем пример ссылок, являющихся голосованием или одобрением, то атрибут nofollow убирает это или дает нулевое значение.
Если мы используем пример ссылок, являющихся голосованием или одобрением, то атрибут nofollow убирает это или дает нулевое значение.
Кодируется как внутри ссылки.
через GIPHY
Что такое noindex?
noindex — это атрибут, установленный на уровне страницы, а не ссылки.Он показывает, что страница, на которой он находится, не должна быть отправлена на индексацию. Несмотря на это, страницу по-прежнему можно сканировать и переходить по ссылкам с нее.
Кодируется в заголовке страницы как
Когда их использовать?
Во многих случаях может использоваться один или оба из них, но в основном они применяются к страницам, которые вы не хотите индексировать или передавать по авторитету. К ним относятся промежуточные сайты, страницы, которые вы хотите сделать более приватными, или альтернативные версии, чтобы избежать дублирования.
Есть нюансы в их использовании, и это часто приводит к неправильному использованию. Я рассмотрю их более подробно ниже.
Я рассмотрю их более подробно ниже.
Когда использовать nofollow
nofollow в большей степени связан со спамом и контролем количества просканированных ссылок на сайты и с них. Это помогает избежать потенциальных штрафов, контролируя количество ссылок между страницами.
Это никоим образом не остановит индексацию страниц, поэтому это не следует рассматривать как защиту от индексации.
Примеры использования
Если у вас есть партнерский веб-сайт, на который вы часто ссылаетесь, например, в нижнем колонтитуле, если вы разработали сайт, дочерняя компания или рекламный партнер.В этом случае вам не нужно будет учитывать каждый экземпляр, так как вы получите тысячи ссылок с одного домена на другой, что потенциально может вызвать проблемы со спамом.
через GIPHY
Однако пользователь захочет видеть и использовать эти ссылки, поэтому этот атрибут nofollow позволяет пользователю делать это, не позволяя сканерам подсчитывать каждую ссылку.
Другим примером является управление путями, по которым идут поисковые роботы, хотя это работает только для определенных поисковых роботов в зависимости от того, как они соблюдают nofollow.
В примере с Google сканер также не будет переходить по ссылке на целевой URL-адрес, поэтому, если вы хотите, чтобы сканеры переходили по ссылкам в заголовке, а не по ссылкам на содержимое тела, вы можете добавить nofollow к ссылкам в теле в вопрос. Это узкоспециализированное использование, но оно может потребоваться на более крупных и сложных сайтах. В таблице ниже представлена информация о том, как поисковые роботы взаимодействуют с nofollow.
Источник
Когда использовать noindex
noindex возможно проще, но не без сложностей.Если на странице есть тег noindex в заголовке, то страница не должна индексироваться поисковыми системами — например, на промежуточных и разрабатываемых сайтах.
Часто используется в сочетании с директивой disallow в файле robots.txt, чтобы убедиться, что эти страницы недоступны через индекс Google.
Примеры использования
Как уже упоминалось, чаще всего используется на промежуточных сайтах, чтобы убедиться, что эти временные URL-адреса не видны.
Это также может подпадать под дублирование, что является еще одним важным примером.Для архивов, версий для печати и других дубликатов может быть задано значение noindex, чтобы убедиться, что одна страница получает права доступа и видна поисковикам.
через GIPHY
Предостережения
Как и во всем, что связано с SEO, существует множество способов и методов. Ниже приведены несколько примеров предостережений и случаев, когда эти атрибуты могут быть не такими простыми, как кажутся.
Другие поисковые роботы
Не все поисковые роботы одинаковы, и хотя Google или Bing могут соблюдать определенную директиву, это не означает, что это сделают другие.Если вы действительно не хотите, чтобы что-то индексировалось, не делайте это общедоступным. Другие сканеры могут полностью игнорировать все эти директивы.
Альтернативы и Canonicals
Наличие тега noindex из-за альтернативных URL-адресов — это хорошо, но часто есть другие способы справиться с ними. Если у вас дублируется страница из-за языков, то необходим тег hreflang. Точно так же, если у вас есть альтернативы из-за немного отличающегося контента, то канонические теги могут наилучшим образом подойти к вашей ситуации.
Если у вас дублируется страница из-за языков, то необходим тег hreflang. Точно так же, если у вас есть альтернативы из-за немного отличающегося контента, то канонические теги могут наилучшим образом подойти к вашей ситуации.
Игнорирование директив
noindex иногда игнорируется, и вы можете увидеть такие вещи в Google Search Console, как «Проиндексировано, хотя и заблокировано тегом noindex». По сути, это означает, что, несмотря на тег noindex, Google по какой-то причине считает его достойным индексации. В этом случае вам нужно будет изучить альтернативы или, возможно, удалить тег noindex с этой страницы, чтобы сделать ее более простой.
Если вы не уверены, не делайте предположений и делайте то, что считаете лучшим.Свяжитесь с нами и обсудите конкретные услуги SEO, адаптированные к вашим потребностям.
Поделиться этой публикацией
___________________________
Источник: https://www.koozai.com/blog/search-marketing/the-differences-between-nofollow-and-noindex/
Поисковые роботы | Руководство пользователя Adobe Commerce 2.
 4
4 Конфигурация Commerce включает параметры для создания и управления инструкциями для поисковых роботов и ботов, которые индексируют ваш сайт. Если запрос на robots.txt достигает Commerce (а не физического файла), он динамически перенаправляется на контроллер robots. Инструкции — это директивы, которые распознаются и соблюдаются большинством поисковых систем.
По умолчанию файл robots.txt, созданный Commerce, содержит инструкции для поискового робота, чтобы избежать индексирования определенных частей сайта, содержащих файлы, которые используются внутри системы. Вы можете использовать настройки по умолчанию или определить свои собственные инструкции для всех или для определенных поисковых систем.В Интернете есть много статей, подробно изучающих эту тему.
Пример: Пользовательские инструкции
Разрешает полный доступ
1
2
Агент пользователя:*
Запретить:
Запрещает доступ ко всем папкам
1
2
Агент пользователя:*
Запретить: /
Инструкции по умолчанию
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Агент пользователя: *
Запретить: /index. php/
Запретить: /*?
Запретить: /checkout/
Запретить: /приложение/
Запретить: /lib/
Запретить: /*.php$
Запретить: /pkginfo/
Запретить: /отчет/
Запретить: /var/
Запретить: /каталог/
Запретить: /клиент/
Запретить: /sendfriend/
Запретить: /обзор/
Запретить: /*SID=
 php/
Запретить: /*?
Запретить: /checkout/
Запретить: /приложение/
Запретить: /lib/
Запретить: /*.php$
Запретить: /pkginfo/
Запретить: /отчет/
Запретить: /var/
Запретить: /каталог/
Запретить: /клиент/
Запретить: /sendfriend/
Запретить: /обзор/
Запретить: /*SID=
php/
Запретить: /*?
Запретить: /checkout/
Запретить: /приложение/
Запретить: /lib/
Запретить: /*.php$
Запретить: /pkginfo/
Запретить: /отчет/
Запретить: /var/
Запретить: /каталог/
Запретить: /клиент/
Запретить: /sendfriend/
Запретить: /обзор/
Запретить: /*SID=
Настройка
robots.txt На боковой панели Admin выберите Content > Design > Configuration .
Найдите конфигурацию Global в первой строке сетки и нажмите Изменить .
Общая конфигурация проекта
Прокрутите вниз и разверните раздел Поисковые роботы и выполните следующие действия:
Роботы поисковых систем
Задайте для параметра Роботы по умолчанию одно из следующих значений:
ИНДЕКС, СЛЕДУЙТЕ Предписывает поисковым роботам проиндексировать сайт и проверить изменения позже. НОИНДЕКС, СЛЕДУЙТЕ Предписывает поисковым роботам не индексировать сайт, а проверять изменения позже. ИНДЕКС, NOFOLLOW Инструктирует поисковых роботов проиндексировать сайт один раз, но не проверять позже изменения. НОИНДЕКС, НОФОЛЛОУ Предписывает поисковым роботам избегать индексации сайта и не проверять позже изменения. При необходимости введите пользовательские инструкции в поле Изменить пользовательскую инструкцию файла robots.txt . Например, пока сайт находится в разработке, вы можете запретить доступ ко всем папкам.
Чтобы восстановить инструкции по умолчанию, нажмите «Восстановить настройки по умолчанию».
По завершении нажмите Сохранить конфигурацию.

Метатеги Noindex vs.Robots.txt: что следует использовать?
Даже те, кто некоторое время занимается SEO-бизнесом, могут запутаться в том, использовать ли метатеги noindex или файлы robots.txt для управления тем, как веб-страницы «просматриваются» (и должны ли они отображаться в результатах поиска). ) поисковыми системами.
В этом посте мы писали о некоторых причинах использования файлов robots.txt на определенных страницах, и они также относятся к использованию тегов noindex. Вот и все сходство между использованием роботов.txt и noindex, как вы увидите далее.
Какая разница?
Проще говоря:
- Файл robots.txt управляет сканированием. Он инструктирует роботов (также известных как пауки), которые ищут страницы для сканирования, чтобы «держаться подальше» от определенных мест. Вы помещаете этот файл в корневой каталог вашего сайта.
- Тег noindex управляет индексацией. Он сообщает паукам, что страница не должна быть проиндексирована. Вы помещаете этот тег в код соответствующей веб-страницы. Вот пример тега:
 Вы помещаете этот тег в код соответствующей веб-страницы. Вот пример тега:
Вы помещаете этот тег в код соответствующей веб-страницы. Вот пример тега: Когда использовать robots.текст.
Не весь контент на вашем сайте должен быть или должен быть найден. В некоторых случаях вы можете не захотеть, чтобы разделы вашего сайта отображались в результатах поиска, например информация, предназначенная только для сотрудников, корзины покупок или страницы благодарности.
Используйте файл robots.txt, если вам нужен контроль на уровне каталога или на вашем сайте. Однако имейте в виду, что роботы не обязаны следовать этим директивам. Большинство из них, например Googlebot, но безопаснее держать любую особо конфиденциальную информацию вне общедоступных областей сайта.
Когда использовать метатеги noindex.
Как и в случае с файлами robots.txt, теги noindex исключат страницу из результатов поиска. Страница по-прежнему будет сканироваться, но не будет проиндексирована. Используйте эти теги, если вы хотите управлять на уровне отдельной страницы.
Не говоря уже о разнице между сканированием и индексированием: сканирование (с помощью пауков) — это то, как паук поисковой системы отслеживает ваш сайт; результаты сканирования попадают в индекс поисковой системы. Хранение этой информации в индексе ускоряет получение релевантных результатов поиска — вместо сканирования каждой страницы, связанной с поиском, для оптимизации скорости выполняется поиск в индексе (базе данных меньшего размера).Если бы индекса не было, поисковая система просмотрела бы каждый бит данных или информации, связанной с поисковым запросом, и у нас у всех было бы время приготовить и съесть пару бутербродов, ожидая отображения результатов поиска. Индекс использует пауков, чтобы поддерживать свою базу данных в актуальном состоянии.
Будьте осторожны!
Как мы предупреждали в нашем посте о файлах robots.txt, всегда существует опасность того, что вы можете сделать весь веб-сайт недоступным для сканирования, поэтому будьте внимательны при использовании этих директив.
Сьюзен Сислер
Сьюзен управляет SEO-кампаниями клиентов DAGMAR и разрабатывает новые стратегии входящего маркетинга. Она хорошо разбирается в техническом SEO и имеет опыт работы в графическом дизайне.
Последние сообщения Susan Sisler (посмотреть все)
Теги поисковых систем, атрибуты, команды и предложения
Часть 2
Ранее я говорил об использовании файлов robots.txt и канонизации для направления поисковых систем на ваш сайт.Теперь давайте закончим обсуждение с 301 редиректом и тегами noindex/nofollow.
1. 301 Перенаправление
Это, вероятно, тот, с которым вы знакомы лучше всего. 301 — это статус, которым отвечает сервер, который отправляет поисковые системы и пользователей на новую страницу, если старая больше не является предпочтительной, передавая значение установленного URL-адреса вновь созданному URL-адресу. Это постоянное движение, поэтому используйте его осторожно. Зачем использовать 301? Возможно, ваш сайт переехал и изменились URL-адреса.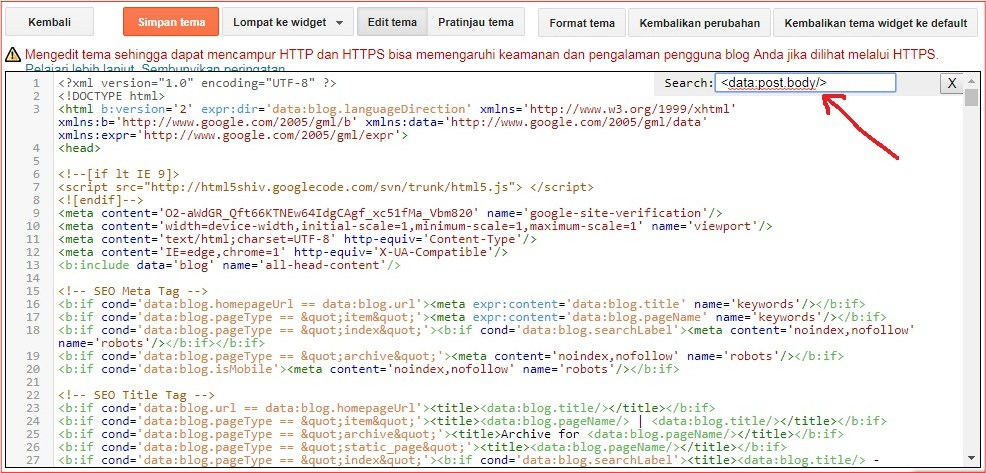 Возможно, ваша страница устарела.Или, может быть, у вас есть несколько версий одной и той же страницы. Во всех этих случаях вы можете использовать редирект 301. В любом случае, вы не хотите терять ценность страницы, срок действия которой истек, перемещен или не является предпочтительным.
Возможно, ваша страница устарела.Или, может быть, у вас есть несколько версий одной и той же страницы. Во всех этих случаях вы можете использовать редирект 301. В любом случае, вы не хотите терять ценность страницы, срок действия которой истек, перемещен или не является предпочтительным.
Вы можете настроить переадресацию 301, используя файл .htaccess вашего сервера, но если ваша CMS позволяет вам загружать плагин, вы можете очень легко настроить их, введя «старый» и «новый» URL-адреса. В WordPress есть плагин перенаправления специально для этого. Вот несколько довольно технических инструкций (прокрутите вниз, чтобы найти файл «RedirectPermanent Directive.»)
Примечание : перенаправление 302 является временным перенаправлением и не должно использоваться слишком часто. Редко бывает подходящее время для использования 302. Один из примеров, когда вы можете использовать его, — это продукт, которого временно нет в наличии. Вы можете перенаправить кого-то на страницу категории на время, пока товар недоступен. Опять же, это не идеально, но сработает.
Опять же, это не идеально, но сработает.
2. «nofollow» и «noindex»
Они похожи, поэтому я объединим их. Обычно вы просто называете их «без подписки» и «без индекса».
Поисковая система будет сканировать (или читать) веб-страницу, переходить по ссылкам на этой странице и индексировать эту страницу в результатах поиска, если только не будет указано НЕ сканировать ее (в файле robots.txt). Есть некоторые страницы, которые вы бы не хотели, чтобы поисковая система сканировала; например, страница условий и положений, страница результатов викторины или страница «спасибо за игру» в игре.
Затем вы используете эти теги. Вы просто добавляете их в раздел
вашей страницы:<метаимя=”роботы” контент=”ноиндекс”>
<метаимя=”роботы” содержание=”nofollow”>
Или объедините их:
Тег no index указывает поисковой системе не включать эту страницу в результаты поиска.Тег no follow говорит поисковой системе не переходить и не передавать значение ссылкам на этой странице.
Инструменты, которые вы должны использовать:
Я планирую будущие блоги по каждому из них, а пока вот некоторые инструменты, которые вы должны использовать (они бесплатны!):
- Инструменты для веб-мастеров: настройте файлы robots.txt, отправьте карты сайта, получите сообщения от Google о своем веб-сайте и посмотрите, что происходит за кулисами вашего веб-сайта.
- Screaming Frog: запустите отчет по любому веб-сайту, чтобы увидеть, какие URL-адреса на самом деле просматриваются поисковыми системами (вы будете удивлены), и легко получите список ошибок 404, обнаруженных на вашем веб-сайте.
- Open Site Explorer: узнайте, какие сайты ссылаются на ваш
Понравился этот пост? Подробнее о Лоре читайте здесь.
Лаура Ли — Менеджер по работе с клиентами
Настройки Noindex в All-in-One SEO
Уведомление: В настоящее время вы просматриваете устаревшую документацию.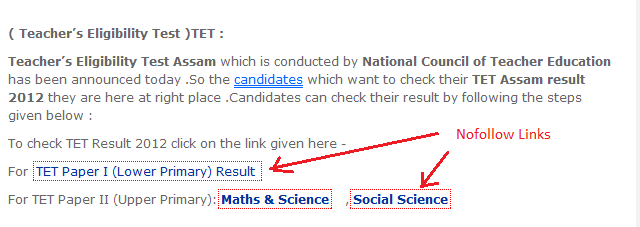
Понимание метатега роботов NOINDEX
NOINDEX — это метатег, который может отображаться для поисковых роботов, который просит их не индексировать контент.Это означает, что контент не будет отображаться в результатах поиска.
Например, вы не хотите, чтобы такие страницы, как ваша политика конфиденциальности или страницы терминов, появлялись в результатах поиска. Никто не ищет эти страницы. Если они захотят ознакомиться с вашей политикой конфиденциальности или условиями, они посетят ваш сайт и проверят нижний колонтитул или свяжутся с вами.
Понимание метатега роботов NOFOLLOW
NOFOLLOW — это метатег, который может отображаться для поисковых роботов и требует от них не переходить ни по каким ссылкам в контенте.Это может быть полезно, если вы не хотите, чтобы поисковые системы переходили по исходящим ссылкам на сайты других людей.
Теперь, когда вы знаете, что делают эти полезные метатеги, давайте посмотрим на основные настройки Noindex и Nofollow в All in One SEO.
Значение по умолчанию NOINDEX
В настройках по умолчанию для Noindex вы можете управлять настройками по умолчанию для NOINDEX для различных типов контента на вашем сайте.
Установите соответствующий флажок, чтобы установить метатег NOINDEX для этого типа контента.Этот параметр можно переопределить для определенных сообщений, страниц и т. д.
Значение по умолчанию NOFOLLOW
В настройках по умолчанию для Nofollow вы можете управлять настройками по умолчанию для NOFOLLOW для различных типов контента на вашем сайте.
Установите соответствующий флажок, чтобы установить метатег NOFOLLOW для этого типа содержимого. Этот параметр можно переопределить для определенных сообщений, страниц и т. д.
Использовать Noindex для категорий
Эта опция установит тег NOINDEX для всех категорий.Этот параметр можно переопределить для определенных категорий, если вы используете All in One SEO Pro.
Использовать Noindex для архивов дат
Эта опция установит тег NOINDEX для всех архивов дат.
Использовать Noindex для авторских архивов
Эта опция установит тег NOINDEX для всех авторских архивов.
Использовать Noindex для архивов тегов
Эта опция установит тег NOINDEX для всех тегов. Этот параметр можно переопределить для определенных тегов, если вы используете All in One SEO Pro.
Использовать Noindex для страницы поиска
Эта опция установит тег NOINDEX на странице результатов поиска.
Использовать Noindex для страницы 404
Эта опция установит тег NOINDEX на странице 404. Это может работать не на всех темах, это будет зависеть от того, имеет ли тема статическую страницу 404 или динамически генерирует страницу 404.
Использовать noindex для архивов таксономии
Эта опция установит тег NOINDEX на страницах архива для выбранных таксономий.
Использовать Noindex для страниц/сообщений с разбивкой на страницы
Этот параметр установит тег NOINDEX для контента с разбивкой на страницы, например, http://mydomain. com/page/2/ будет иметь тег NOINDEX, а http://mydomain.com/ — нет. Это для тех, кто не хочет, чтобы контент с разбивкой на страницы индексировался поисковыми системами отдельно, а вместо этого индексировалась только первая страница.
com/page/2/ будет иметь тег NOINDEX, а http://mydomain.com/ — нет. Это для тех, кто не хочет, чтобы контент с разбивкой на страницы индексировался поисковыми системами отдельно, а вместо этого индексировалась только первая страница.
Примечание:
Это относится только к домашней странице с разбивкой на страницы, любому типу сообщений и любой таксономии. Это не относится к архивам, таким как архивы даты или автора.
Использовать Nofollow для страниц/сообщений с разбивкой на страницы
Этот параметр установит тег NOFOLLOW для всего контента с разбивкой на страницы, например, http://mydomain.com/page/2/ будет иметь тег NOFOLLOW, а http://mydomain.com/ — нет. Это для тех, кто не хочет, чтобы поисковые системы переходили по ссылкам в разбивке на страницы.
Примечание:
Это относится только к домашней странице с разбивкой на страницы, любому типу сообщений и любой таксономии. Это не относится к архивам, таким как архивы даты или автора.