Простой пример: Простой пример HTML документа — Учебник по основам HTML
Простой пример HTML документа — Учебник по основам HTML
Как устроен HTML-документ
HTML-документ — это просто текстовый файл с расширением *.html (Unix-системы могут содержать файлы с расширением *.htmll). Вот самый простой HTML-документ:
<html>
<head>
<title>Пример 1</title>
</head>
<body>
<h2>Привет!</h2>
<P> Это простейший пример HTML-документа. </P>
<P> Этот *.html-файл может быть одновременно открыт и в Notepad, и в Netscape. Сохранив изменения в Notepad, просто нажмите кнопку Reload ('перезагрузить') в Netscape, чтобы увидеть эти изменения реализованными в HTML-документе. </P>
</body>
</html>
Для удобства чтения я ввел дополнительные отступы, однако в HTML это совсем не обязательно. Более того, браузеры просто игнорируют символы конца строки и множественные пробелы в HTML-файлах.
<html>
<head>
<title>Пример 1</title>
</head>
<body>
<h2>Привет!</h2>
<P>Это простейший пример HTML-документа.</P>
<P>Этот *.html-файл может быть одновременно открыт и в Notepad, и в Netscape. Сохранив изменения в Notepad, просто нажмите кнопку Reload ('перезагрузить') в Netscape, чтобы увидеть эти изменения реализованными в HTML-документе.</P>
</body>
</html>
Как видно из примера, вся информация о форматировании документа сосредоточена в его фрагментах, заключенных между знаками «<» и «>». Такой фрагмент (например, <html>) называется меткой (по-английски — tag, читается «тэг»).
Большинство HTML-меток — парные, то есть на каждую открывающую метку вида <tag> есть закрывающая метка вида </tag> с тем же именем, но с добавлением «/».
Метки можно вводить как большими, так и маленькими буквами. Например, метки <body>, <BODY> и <Body> будут восприняты браузером одинаково.
Многие метки, помимо имени, могут содержать атрибуты — элементы, дающие дополнительную информацию о том, как браузер должен обработать текущую метку. В нашем простейшем документе, однако, нет ни одного атрибута. Но мы обязательно встретимся с атрибутами уже в следующем разделе.
Обязательные метки
<html> … </html>
Метка <html> должна открывать HTML-документ. Аналогично, метка </html> должна завершать HTML-документ.
<head> … </head>
Эта пара меток указывает на начало и конец заголовка документа. Помимо наименования документа (см. описание метки <title> ниже), в этот раздел может включаться множество служебной информации, о которой мы обязательно поговорим чуть позже.
<title> … </title>
Все, что находится между метками <title> и </title>, толкуется браузером как название документа. Netscape Navigator, например, показывает название текущего документа в заголовке окна и печатает его в левом верхнем углу каждой страницы при выводе на принтер. Рекомендуется название не длиннее 64 символов.
<body> … </body>
Эта пара меток указывает на начало и конец тела HTML-документа, каковое тело, собственно, и определяет содержание документа.
<h2> … </h2> — <H6> … </H6>
Метки вида <Hi> (где i — цифра от 1 до 6) описывают заголовки шести различных уровней. Заголовок первого уровня — самый крупный, шестого уровня, естественно — самый мелкий.
<P> … </P>
Такая пара меток описывает абзац. Все, что заключено между <P> и </P>, воспринимается как один абзац.
Метки <Hi> и <P> могут содержать дополнительный атрибут ALIGN (читается «элайн», от английского «выравнивать»), например:
<h2 ALIGN=CENTER>Выравнивание заголовка по центру</h2>
или
<P ALIGN=RIGHT>Образец абзаца с выравниванием по правому краю</P>
Подытожим все, что мы знаем, с помощью примера 2:
<html>
<head>
<title>Пример 2</title>
</head>
<body>
<h2 ALIGN=CENTER>Привет!</h2>
<h3>Это чуть более сложный пример HTML-документа</h3>
<P>Теперь мы знаем, что абзац можно выравнивать не только влево, </P>
<P ALIGN=CENTER>но и по центру</P>
<P ALIGN=RIGHT>или по правому краю.</P>
</body>
С этого момента Вы знаете достаточно, чтобы создавать простые HTML-документы самостоятельно от начала до конца. В следующем разделе мы поговорим, как можно улучшить наш простой HTML-документ. Начнем с малого — с абзаца.
В следующем разделе мы поговорим, как можно улучшить наш простой HTML-документ. Начнем с малого — с абзаца.
Простой математический пример поставил в тупик людей и вызвал бурное обсуждение в сети (Фото)
Фото DP

Простая математическая задачка озадачила многих людей, а также вызвала среди пользователей очень бурные споры. Огромное число людей не может прийти к единому ответу на этот, казалось бы, простой пример.
how smart are my oomfs pic.twitter.com/YVxtzhNx4c
— dev ᴺᴹ ᴬᴳ (@iambuterastann) November 13, 2020
Одни утверждают, что ответ на задачку — «9», а другие, напротив, уверены, что конечный ответ на уравнение — «1». Все дело в разных подходах к решению: одни сначала считают числа внутри скобок (1+2=3), а потом умножают результат на получившуюся цифру перед скобкой (6:2=3). Получается 3*3=9.
Другие предпочитают сложить числа в скобках (1+2=3), затем умножить результат на число перед скобкой (3*2=6), а в конце выполнить деление (6:6=1). За несколько дней пост собрал свыше 36 тысяч комментариев, где продолжается бурное обсуждение. Впрочем, люди сходятся во мнении, что оба ответа имеют права на существование, а для корректного решения необходимо слегка поменять задачку и добавить еще одни скобки: (6 ÷ 2) (1 + 2) или 6 ÷ (2 (1 + 2)).
Как работает стратегия. Простой пример | by Сергей Славинский | Syndicated Brands
Стратегия — это модно. Несмотря на то, что до первой половины двухтысячных годов в мире были всего три стратегических уровня (портфельный, конкурентный и функциональный), первые два остались в ведении крупных специалистов, а вот количество функциональных стратегий выросло до гигантской популяции: стратегическим может быть практически всё. Потому как контент-маркетинг или брендинг — это не так дорого, как если добавить к ним слово “стратегический”. Хотя операционный контент-маркетинг или брендинг представить сложно — таких, собственно, не бывает.
Хотя операционный контент-маркетинг или брендинг представить сложно — таких, собственно, не бывает.
Но если вернуться к истокам, то портфельная стратегия нужна, соответственно, чтобы собрать под своё крыло различные бизнесы из разных отраслей и играющие на разных рынках, чтобы обезопасить себя от неопределенности, волатильности и всякого прочего, мешающего жить. Поэтому в рамках портфельной стратегии тракторы прекрасно уживаются с гиперкарами, а газировка с космическими кораблями. Но это, пожалуй, не наш формат. А наш — это стратегия конкурентная. Зачем она?
Всё предельно просто. Она помогает перескочить компании из сегодня в послезавтра.
Звучит абстрактно? Можно упростить.
Сегодня вы догоняете. Сформировался рынок, на который вы не успели и стремитесь выйти во чтобы это ни стало. Это нормальное состояние российского бизнеса: “давайте сделаем такое же, но дешевле”. Ну или дороже. Не суть. Важно, что такое же. Яркий глобальный пример — компания Fujifilm, которая “не успела” на рынок цифровых камер full frame, где сейчас доминирует компания Sony, а Nikon, Canon и Panasonic пытаются составить конкуренцию, что крайне сложно.
Бои разворачиваются на глазах, в реальном времени. Суть в том, что фото и видео “снизу” отъели смартфоны и продолжат это делать при помощи технологий обработки изображения. Поэтому производители фото и видео вынуждены уходить из сегмента любительского в просьюмерский. Отсюда и появились подозрения, что камеры с матрицами большого формата — это будущее фототехники, стремительно приближающейся по характеристикам к рынку оборудования для кино. А что важно для потребителя? Явные отличия, удерживающие его от того, чтобы перейти на смартфон. И размер матрицы — это одно из важных потребительских преимуществ на потребительском рынке. Чем больше, тем лучше. (Я говорю о тех, кто покупает камеру для себя и хобби, не про профи . Там другая история, связанная не с техникой, а с руками).
Но если вы готовы потратить 3–5–10 тысяч долларов на то, чтобы перестать снимать на смартфон — для вас есть прекрасные полнокадровые камеры, дающие любимое всеми мягкое размытие фона и эффект “боке” на закате. И Fuji на этот рынок опоздали.
И Fuji на этот рынок опоздали.
Несмотря на то, что сам рынок сформировался только в прошлом году, компании года три назад стало понятно, что они будут в догоняющих. Но зачем догонять, когда есть возможность опередить.
Если подумать, что тренд сохранится, то когда ваша полнокадровая камера Sony будет у вас, у соседа, у соседа которого вы ненавидите и у какого-нибудь раздражающего вас персонажа, то придётся задуматься о смене. И что тогда? У Fujifilm есть ответ — это средний формат. Закат еще эффектнее, “боке” еще красивее и в дополнение — даже самые мелкие пузырьки в бокале с шампанским. Невероятно красиво!
Упрощая, компания просто перешагнула через растущий рынок с высоким порогом входа и напряженной конкуренцией, и подумала о том, что будет дальше. После того, как закончится только начинающийся бой. И начала аккумулировать ресурсы и технологии для того, чтобы занять лидирующую позицию на следующем витке развития рынка. Раз уж этот виток они пропустили.
И если посмотреть на историю и успешные кейсы, когда лидером рынка вдруг становилась компания “ниоткуда” или крепкий середнячок, на который уже все забили — то такая связь стратегии с результатом выясняется достаточно часто. Это та самая “прорывная инновация”, которую все хотят. Но достаточно лишь посмотреть не на то, что будет завтра, а взглянуть на то, что будет после.
Это тот приём, который позволяет вырваться вперёд бизнесу второго эшелона. Он рискован, как и любые другие решения. Но в результате, получается очень любопытная картина, работающая во времени.
Для того, чтобы занять следующую позицию, лидеры будут использовать эффект ореола: “были хороши в полном кадре, будем прекрасными и в среднем формате”. А компания, которая пошла обходным путём — займет нишу эксперта, который дольше всех работает на этом рынке. И соберёт часть лояльных клиентов других марок, отобрав у каждого сегодняшнего игрока понемногу.
Это всё, безусловно, не предсказание, а лишь один из правдоподобных сценариев развития и отрасли, и рынка, и самой компании. И иллюстрирует этот пример суть стратегического подхода, которая очень проста: порой вместо того, чтобы догонять насыщенный рынок, надо обходить его и вставать впереди. Это одна из стратегий лидерства. Но её прелесть в том, что у вас есть достаточно времени, чтобы подготовиться к тому, чтобы этим лидером стать.
И иллюстрирует этот пример суть стратегического подхода, которая очень проста: порой вместо того, чтобы догонять насыщенный рынок, надо обходить его и вставать впереди. Это одна из стратегий лидерства. Но её прелесть в том, что у вас есть достаточно времени, чтобы подготовиться к тому, чтобы этим лидером стать.
“А что если….?” — спросите вы. Рынок свернёт в сторону, появится новая технология и т.д. и т.п…. Риск всегда будет. Потому как сама суть бизнеса — это рисковать и десяток ошибочных решений “покрывать” одним выигрышным. Так же, как работает киноиндустрия. Поэтому без риска не обойтись, он не исчезнет. Но вот в чём странность. Когда вы определяете вектор будущего развития рынка и он правдоподобен, вы снижаете риск того, что он (вектор) уйдёт в сторону от выбранной вами траектории. Но на эту тему я уже писал. Это как раз и есть “пророчества”, так пугающие некоторых бизнесменов:
Важно, очень важно думать о том, что будет завтра. Но это еще не стратегия. Стратегия начинается тогда, когда вы начинаете задумываться о том, стоит ли вообще вкладывать усилия в завтра. Вдруг есть возможность не догнать или с потерями защищать, то чаще всего стоит обогнать и стать лидером заранее? Не догоняя рынок, и не впрыгивая в последний вагон конкурентного поезда сейчас.
Вдруг есть возможность не догнать или с потерями защищать, то чаще всего стоит обогнать и стать лидером заранее? Не догоняя рынок, и не впрыгивая в последний вагон конкурентного поезда сейчас.
Простой пример — Искусственный интеллект
А теперь допустим, что некий сейсмолог доложил руководству этой компании результаты проведенного исследования участка номер 3, которые определенно показывают, что на этом участке имеется нефть. Какую сумму должна быть готова компания заплатить за эту информацию? Один из способов получения ответа на этот вопрос состоит в том, чтобы проверить, какие действия предприняла бы компания, обладая указанной информацией, как описано ниже.
• С вероятностью 1/n исследование покажет наличие нефти на участке 3. В этом случае компания купит участок 3 за С/n долларов и получит прибыль в долларов.
• С вероятностью (n-1)/n исследование покажет, что участок не содержит нефти, и в этом случае компания должна купить другой участок. Теперь вероятность обнаружения нефти на одном из других участков измеряется значением от 1/л до 1/(л-1), поэтому компания получит ожидаемую прибыль долларов.
Теперь мы можем рассчитать ожидаемую прибыль при наличии информации о результатах исследования:
Поэтому компания должна быть готова заплатить сейсмологу за эту информацию вплоть до С/n долларов, поскольку данная информация стоит столько же, сколько и сам участок.
Стоимость информации определяется тем фактом, что при наличии такой информации можно изменить собственную стратегию таким образом, чтобы она соответствовала действительной ситуации. Наличие информации позволяет выявить отличительные особенности рассматриваемой ситуации, а без этой информации в лучшем случае можно лишь найти среднее значение по всем возможным ситуациям. Вообще говоря, стоимость данного конкретного фрагмента информации определяется той разницей в ожидаемых значениях между наилучшими действиями, которая возникает до и после получения этой информации.
Вообще говоря, стоимость данного конкретного фрагмента информации определяется той разницей в ожидаемых значениях между наилучшими действиями, которая возникает до и после получения этой информации.
Использование простого синтаксиса запроса Lucene — Azure Cognitive Search
- Чтение занимает 7 мин
В этой статье
В Когнитивный поиск Azure простой синтаксис запроса вызывает средство синтаксического анализа запросов по умолчанию для полнотекстового поиска.In Azure Cognitive Search, the simple query syntax invokes the default query parser for full text search. Средство синтаксического анализа работает быстро и обрабатывает распространенные сценарии, включая полнотекстовый поиск, фильтрованный и аспектный Поиск, а также Префиксный поиск. The parser is fast and handles common scenarios, including full text search, filtered and faceted search, and prefix search. В этой статье приводятся примеры, иллюстрирующие простое использование синтаксиса в запросе поиска документов (REST API) .This article uses examples to illustrate simple syntax usage in a Search Documents (REST API) request.
The parser is fast and handles common scenarios, including full text search, filtered and faceted search, and prefix search. В этой статье приводятся примеры, иллюстрирующие простое использование синтаксиса в запросе поиска документов (REST API) .This article uses examples to illustrate simple syntax usage in a Search Documents (REST API) request.
Примеры заданий НьюNYC Jobs examples
В следующих примерах используется индекс поиска заданий Нью , состоящий из заданий, доступных на основе набора данных, предоставленного в городе Нью- Йорк опендата.The following examples leverage the NYC Jobs search index consisting of jobs available based on a dataset provided by the City of New York OpenData Initiative. Эти данные не являются текущими или завершенными.This data should not be considered current or complete. Индекс находится в службе «песочницы», предоставляемой корпорацией Майкрософт. Это означает, что для работы с этими запросами не требуется подписка Azure или Azure Когнитивный поиск. The index is on a sandbox service provided by Microsoft, which means you do not need an Azure subscription or Azure Cognitive Search to try these queries.
The index is on a sandbox service provided by Microsoft, which means you do not need an Azure subscription or Azure Cognitive Search to try these queries.
Для отправки HTTP-запроса по запросу GET или POST требуется соответствующее средство.What you do need is Postman or an equivalent tool for issuing HTTP request on GET or POST. Если вы не знакомы с этими инструментами, см. статью Краткое руководство. изучение Azure Когнитивный поиск REST API.If you’re unfamiliar with these tools, see Quickstart: Explore Azure Cognitive Search REST API.
Настройка запросаSet up the request
Заголовки запроса должны иметь следующие значения:Request headers must have the following values:
КлючKey ЗначениеValue Content-TypeContent-Type application/jsonapi-keyapi-key 252044BE3886FE4A8E3BAA4F595114BB(это фактический ключ API запроса для службы поиска «песочницы», в которой размещается индекс заданий Нью). (this is the actual query API key for the sandbox search service hosting the NYC Jobs index)
(this is the actual query API key for the sandbox search service hosting the NYC Jobs index)Задайте для команды значение
GET.Set the verb toGET.Задайте для URL-адреса значение
https://azs-playground.search.windows.net/indexes/nycjobs/docs?api-version=2020-06-30&search=*&$count=true.Set the URL tohttps://azs-playground.search.windows.net/indexes/nycjobs/docs?api-version=2020-06-30&search=*&$count=true.Коллекция Documents в индексе содержит все содержимое, доступное для поиска.The documents collection on the index contains all searchable content. Ключ API запроса, указанный в заголовке запроса, работает только для операций чтения, предназначенных для коллекции Documents.The query api-key provided in the request header only works for read operations targeting the documents collection.
$count=trueВозвращает количество документов, соответствующих условиям поиска.$count=truereturns a count of the documents matching the search criteria. В пустой строке поиска счетчик будет содержать все документы в индексе (около 2558 в случае заданий Нью).On an empty search string, the count will be all documents in the index (about 2558 in the case of NYC Jobs).search=*является неопределенным запросом, эквивалентным null или пустым поиском.search=*is an unspecified query, equivalent to null or empty search. Это не особенно полезно, но это самый простой поиск, который можно сделать, и Показать все доступные для получения поля в индексе со всеми значениями.It’s not especially useful, but it is the simplest search you can do, and it shows all retrievable fields in the index, with all values.
В качестве шага проверки вставьте приведенный ниже запрос в раздел GET и щелкните Отправить.
As a verification step, paste the following request into GET and click Send. Будут возвращены результаты в виде подробных документов JSON.Results are returned as verbose JSON documents.https://azs-playground.search.windows.net/indexes/nycjobs/docs?api-version=2020-06-30&$count=true&search=*&queryType=full
 (this is the actual query API key for the sandbox search service hosting the NYC Jobs index)
(this is the actual query API key for the sandbox search service hosting the NYC Jobs index)
 As a verification step, paste the following request into GET and click Send. Будут возвращены результаты в виде подробных документов JSON.Results are returned as verbose JSON documents.
As a verification step, paste the following request into GET and click Send. Будут возвращены результаты в виде подробных документов JSON.Results are returned as verbose JSON documents.Как вызвать анализ простого запросаHow to invoke simple query parsing
Для интерактивных запросов не нужно указывать дополнительные параметры: простой синтаксис используется по умолчанию.For interactive queries, you don’t have to specify anything: simple is the default. В коде, если был вызван ранее queryType=full , можно сбросить значение по умолчанию с помощью queryType=simple .In code, if you previously invoked queryType=full, you can reset the default with queryType=simple.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"queryType": "simple"
}
Пример 1.
 полнотекстовый поиск по конкретным полямExample 1: Full text search on specific fields
полнотекстовый поиск по конкретным полямExample 1: Full text search on specific fieldsПервый пример не связан с синтаксическим анализатором, но мы начали с него, чтобы представить первое фундаментальное понятие запроса: автономность.This first example is not parser-specific, but we lead with it to introduce the first fundamental query concept: containment. Этот пример ограничивает как выполнение запроса, так и ответ на несколько конкретных полей.This example limits both query execution and the response to just a few specific fields. Знать, как структурировать читаемый ответ JSON, важно, если используется инструмент Postman или обозреватель поиска.Knowing how to structure a readable JSON response is important when your tool is Postman or Search explorer.
Этот запрос предназначен только для business_title в searchFields , указывая с помощью select параметра то же поле в ответе.This query targets only business_title in searchFields, specifying through the select parameter the same field in the response.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"queryType": "simple",
"search": "*",
"searchFields": "business_title",
"select": "business_title"
}
Результат запроса должен выглядеть, как на снимке экрана ниже.Response for this query should look similar to the following screenshot.
Вы могли заметить оценку поиска в ответе.You might have noticed the search score in the response. Однородные баллы, равные 1 , происходят, когда нет ранга, так как поиск не является полнотекстовым поиском или не был предоставлен ни один критерий.Uniform scores of 1 occur when there is no rank, either because the search was not full text search, or because no criteria was provided. Для пустого поиска строки возвращаются в произвольном порядке.For an empty search, rows come back in arbitrary order. Когда вы добавите условие поиска, вы увидите, как оценки поиска превратятся в понятные значения. When you include actual criteria, you will see search scores evolve into meaningful values.
When you include actual criteria, you will see search scores evolve into meaningful values.
Пример 2. Поиск по идентификаторуExample 2: Look up by ID
При возврате результатов поиска в запросе логический последующий шаг заключается в предоставлении страницы сведений, которая содержит больше полей из документа.When you return search results in a query, a logical subsequent step is to provide a details page that includes more fields from the document. В этом примере показано, как вернуть один документ с помощью операции уточняющего запроса для передачи идентификатора документа.This example shows you how to return a single document using a Lookup operation to pass in the document ID.
Все документы имеют уникальный идентификатор.All documents have a unique identifier. Чтобы проверить синтаксис запроса поиска, сначала получите список идентификаторов документов, чтобы найти в нем нужный идентификатор.To try out the syntax for a lookup query, first return a list of document IDs so that you can find one to use. В индексе вакансий в Нью-Йорке идентификаторы хранятся в поле
В индексе вакансий в Нью-Йорке идентификаторы хранятся в поле id.For NYC Jobs, the identifiers are stored in the id field.
GET /indexes/nycjobs/docs?api-version=2020-06-30&search=*&$select=id&$count=true
Затем извлеките документ из коллекции на основе id «9E1E3AF9-0660-4E00-AF51-9B654925A2D5», который был первым в предыдущем ответе.Next, retrieve a document from the collection based on id «9E1E3AF9-0660-4E00-AF51-9B654925A2D5», which appeared first in the previous response. Следующий запрос возвращает все доступные для получения поля для всего документа.The following query returns all retrievable fields for the entire document.
GET /indexes/nycjobs/docs/9E1E3AF9-0660-4E00-AF51-9B654925A2D5?api-version=2020-06-30
Пример 3. Фильтрация запросовExample 3: Filter queries
Синтаксис фильтра — это выражение OData, которое можно использовать самостоятельно или с помощью search . Filter syntax is an OData expression that you can use by itself or with
Filter syntax is an OData expression that you can use by itself or with search. Автономный фильтр без параметра поиска полезен, когда выражение фильтра может полностью определить интересующие документы.A standalone filter, without a search parameter, is useful when the filter expression is able to fully qualify documents of interest. Без строки запроса не выполняется лексический или лингвистический анализ (все оценки имеют значение 1), нет оценки и рейтинга.Without a query string, there is no lexical or linguistic analysis, no scoring (all scores are 1), and no ranking. Обратите внимание, что строка поиска пуста.Notice the search string is empty.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "",
"filter": "salary_frequency eq 'Annual' and salary_range_from gt 90000",
"select": "job_id, business_title, agency, salary_range_from"
}
Если они используются вместе, сначала ко всему индексу применяется фильтр, а затем в результатах фильтрации выполняется поиск. Used together, the filter is applied first to the entire index, and then the search is performed on the results of the filter. Поэтому фильтры могут повысить производительность запросов, так как они уменьшают количество документов, которые поисковый запрос должен обработать.Filters can therefore be a useful technique to improve query performance since they reduce the set of documents that the search query needs to process.
Еще один эффективный способ объединения фильтра и поиска заключается search.ismatch*() в критерии фильтра, где можно использовать поисковый запрос в фильтре.Another powerful way to combine filter and search is through search.ismatch*() in a filter expression, where you can use a search query within the filter. Это выражение фильтра использует подстановочный знак для термина план, чтобы выбрать должность business_title, содержащую термины «план», «планировщик», «планирование» и т. д.This filter expression uses a wildcard on plan to select business_title including the term plan, planner, planning, and so forth.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "",
"filter": "search.ismatch('plan*', 'business_title', 'full', 'any')",
"select": "job_id, business_title, agency, salary_range_from"
}
Дополнительные сведения о функции см. в описании search.ismatch в разделе с примерами фильтров.For more information about the function, see search.ismatch in «Filter examples».
Пример 4. Фильтры диапазоновExample 4: Range filters
Фильтрация диапазона поддерживается в $filter выражениях для любого типа данных.Range filtering is supported through $filter expressions for any data type. В следующих примерах выполняется поиск по числовым и строковым полям.The following examples search over numeric and string fields.
Типы данных важны в фильтрах диапазона и лучше всего работают, когда числовые данные находятся в числовых полях, а строковые данные — в строковых. Data types are important in range filters and work best when numeric data is in numeric fields, and string data in string fields. Числовые данные в строковых полях не подходят для диапазонов, так как числовые строки не сравнимы в Azure Когнитивный поиск.Numeric data in string fields is not suitable for ranges because numeric strings are not comparable in Azure Cognitive Search.
Data types are important in range filters and work best when numeric data is in numeric fields, and string data in string fields. Числовые данные в строковых полях не подходят для диапазонов, так как числовые строки не сравнимы в Azure Когнитивный поиск.Numeric data in string fields is not suitable for ranges because numeric strings are not comparable in Azure Cognitive Search.
Следующий запрос является числовым диапазоном:The following query is a numeric range:
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "",
"filter": "num_of_positions ge 5 and num_of_positions lt 10",
"select": "job_id, business_title, num_of_positions, agency",
"orderby": "agency"
}
Результат запроса должен выглядеть, как на снимке экрана ниже.Response for this query should look similar to the following screenshot.
В этом запросе диапазон находится над строковым полем (business_title):In this query, the range is over a string field (business_title):
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "",
"filter": "business_title ge 'A*' and business_title lt 'C*'",
"select": "job_id, business_title, agency",
"orderby": "business_title"
}
Результат запроса должен выглядеть, как на снимке экрана ниже. Response for this query should look similar to the following screenshot.
Response for this query should look similar to the following screenshot.
Примечание
В приложениях поиска часто используется фасетная навигация на основе диапазонов значений.Faceting over ranges of values is a common search application requirement. Дополнительные сведения и примеры см. в разделе Создание фильтра аспектов.For more information and examples, see How to build a facet filter.
Пример 5. Геопространственный поискExample 5: Geo-search
Индекс выборки включает в себя поле geo_location с координатами широты и долготы.The sample index includes a geo_location field with latitude and longitude coordinates. В этом примере используется функция geo.distance, которая фильтрует документы в пределах окружности начальной точки до произвольного расстояния (в километрах), которое вы предоставляете.This example uses the geo.distance function that filters on documents within the circumference of a starting point, out to an arbitrary distance (in kilometers) that you provide. Вы можете отрегулировать последнее значение в запросе (4), чтобы уменьшить или увеличить площадь поверхности запроса.You can adjust the last value in the query (4) to reduce or enlarge the surface area of the query.
Вы можете отрегулировать последнее значение в запросе (4), чтобы уменьшить или увеличить площадь поверхности запроса.You can adjust the last value in the query (4) to reduce or enlarge the surface area of the query.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "",
"filter": "geo.distance(geo_location, geography'POINT(-74.11734 40.634384)') le 4",
"select": "business_title, work_location"
}
Для более удобочитаемых результатов результаты поиска будут обрезаны, чтобы они включали название задания и рабочий ресурс.For more readable results, search results are trimmed to include job title and the work location. Начальные координаты были получены из случайного документа в индексе (в данном случае для места работы в Статен-Айленде).The starting coordinates were obtained from a random document in the index (in this case, for a work location on Staten island.
Пример 6. Точность поискаExample 6: Search precision
Запросы терминов позволяют искать одиночные термины или наборы терминов, которые оцениваются независимо друг от друга. Term queries are single terms, perhaps many of them, that are evaluated independently. Запросы фраз заключаются кавычки и проверяются как буквальная строка.Phrase queries are enclosed in quotation marks and evaluated as a verbatim string. Точностью соответствия управляют операторы и параметр searchMode.Precision of the match is controlled by operators and searchMode.
Term queries are single terms, perhaps many of them, that are evaluated independently. Запросы фраз заключаются кавычки и проверяются как буквальная строка.Phrase queries are enclosed in quotation marks and evaluated as a verbatim string. Точностью соответствия управляют операторы и параметр searchMode.Precision of the match is controlled by operators and searchMode.
Пример 1. search=fire совпадение с результатами в 140, где все совпадения содержат слово Fire где-нибудь в документе.Example 1: search=fire matches on 140 results, where all matches contain the word fire somewhere in the document.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "fire"
}
Пример 2. search=fire department возвращает 2002 результата.Example 2: search=fire department returns 2002 results. Возвращаются документы, содержащие слово «fire» или «department».Matches are returned for documents containing either fire or department.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "fire department"
}
Пример 3. search="fire department" возвращает 77 результатов.Example 3: search="fire department" returns 77 results. При заключении строки в кавычки создается Поиск по фразам, состоящий из обоих терминов, а совпадения обнаруживаются по маркерам в индексе, состоящим из Объединенных терминов.Enclosing the string in quotation marks creates a phrase search consisting of both terms, and matches are found on tokenized terms in the index consisting of the combined terms. Это объясняет, почему поисковый запрос search=+fire +department не является эквивалентным.This explains why a search like search=+fire +department is not equivalent. Оба термина являются обязательными, но их наличие проверяется независимо друг от друга.Both terms are required, but are scanned for independently.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\""
}
Примечание
Поскольку запрос фразы задается в кавычках, в этом примере добавляется escape-символ ( \ ) для сохранения синтаксиса. Because a phrase query is specified through quotation marks, this example adds an escape character (
Because a phrase query is specified through quotation marks, this example adds an escape character (\) to preserve the syntax.
Пример 7. Логические операторы с параметром searchModeExample 7: Booleans with searchMode
Простой синтаксис поддерживает логические операторы в виде знаков (+, -, |).Simple syntax supports boolean operators in the form of characters (+, -, |). Параметр searchMode информирует о компромиссах между точностью и отзывом, при searchMode=any этом при помощи вызова Call (Match для любого критерия определяется документ для результирующего набора) и searchMode=all точность (все условия должны быть сопоставлены).The searchMode parameter informs tradeoffs between precision and recall, with searchMode=any favoring recall (matching on any criteria qualifies a document for the result set), and searchMode=all favoring precision (all criteria must be matched).
Значение по умолчанию — searchMode=any , что может быть запутанным, если вы накладываете запрос с несколькими операторами и получаете более широкие вместо более узких результатов.The default is searchMode=any, which can be confusing if you are stacking a query with multiple operators and getting broader instead of narrower results. Это особенно верно для оператора NOT, когда результаты включают в себя все документы, которые «не содержат» конкретный термин.This is particularly true with NOT, where results include all documents «not containing» a specific term.
При использовании searchMode по умолчанию (Any) возвращаются документы 2800: те, которые содержат фразу «пожарный отдел», а также все документы, у которых нет фразы «Метротеч Center».Using the default searchMode (any), 2800 documents are returned: those containing the phrase «fire department», plus all documents that do not have the phrase «Metrotech Center».
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\"-\"Metrotech Center\"",
"searchMode": "any"
}
Результат запроса должен выглядеть, как на снимке экрана ниже.Response for this query should look similar to the following screenshot.
Изменение для searchMode=all применения совокупного воздействия на критерии и возвращает меньший результирующий набор — 21 документ, состоящий из документов, содержащих целую фразу «пожарный отдел», за вычетом этих заданий по адресу Метротеч Center.Changing to searchMode=all enforces a cumulative effect on criteria and returns a smaller result set — 21 documents — consisting of documents containing the entire phrase «fire department», minus those jobs at the Metrotech Center address.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\"-\"Metrotech Center\"",
"searchMode": "all"
}
Пример 8.
 Структурирование результатовExample 8: Structuring results
Структурирование результатовExample 8: Structuring resultsНесколько параметров управляют тем, какие поля добавляются в результаты поиска, числом документов, возвращаемых в каждом пакете, и порядком сортировки.Several parameters control which fields are in the search results, the number of documents returned in each batch, and sort order. В этом примере переводятся некоторые из предыдущих примеров, ограничивающие результаты конкретными полями с помощью $select оператора и условий поиска точных выражений, возвращая 82 соответствий.This example resurfaces a few of the previous examples, limiting results to specific fields using the $select statement and verbatim search criteria, returning 82 matches.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\"",
"searchMode": "any",
"select": "job_id,agency,business_title,civil_service_title,work_location,job_description"
}
Они добавлены к предыдущему примеру, и их можно отсортировать по заголовку. Appended onto the previous example, you can sort by title. Сортировка работает, так как поле civil_service_title является сортируемым в индексе.This sort works because civil_service_title is sortable in the index.
Appended onto the previous example, you can sort by title. Сортировка работает, так как поле civil_service_title является сортируемым в индексе.This sort works because civil_service_title is sortable in the index.
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\"",
"searchMode": "any",
"select": "job_id,agency,business_title,civil_service_title,work_location,job_description",
"orderby": "civil_service_title"
}
Результаты разбиения на страницы реализуются с помощью $top параметра. в этом случае возвращаются пять первых документов:Paging results is implemented using the $top parameter, in this case returning the top 5 documents:
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\"",
"searchMode": "any",
"select": "job_id,agency,business_title,civil_service_title,work_location,job_description",
"orderby": "civil_service_title",
"top": "5"
}
Чтобы получить следующие 5 документов, пропустите первый пакет.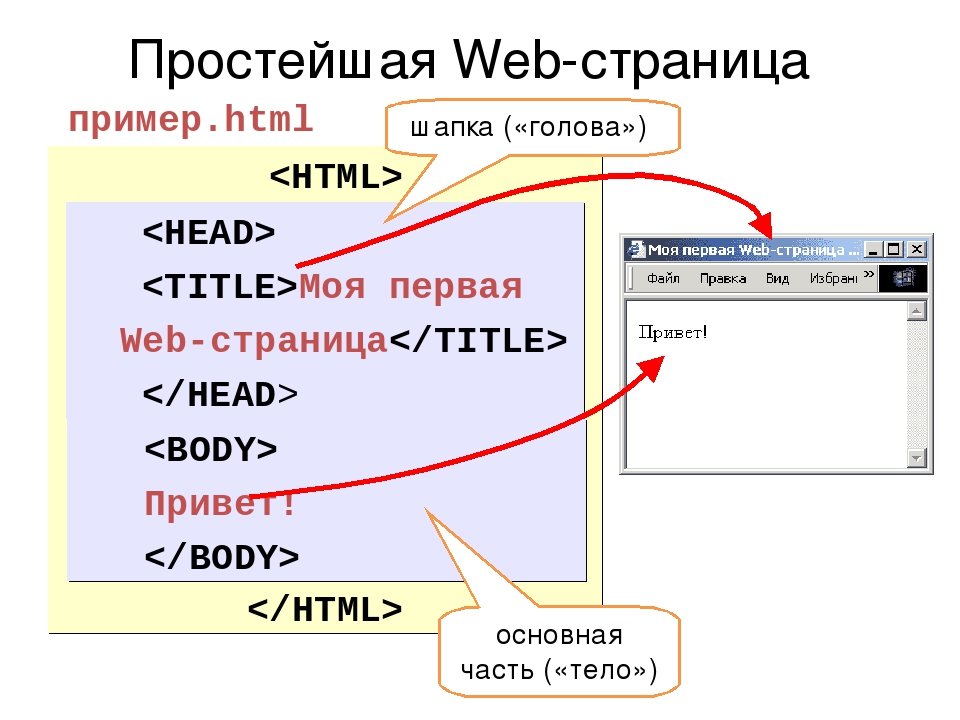 To get the next 5, skip the first batch:
To get the next 5, skip the first batch:
POST /indexes/nycjobs/docs/search?api-version=2020-06-30
{
"count": true,
"search": "\"fire department\"",
"searchMode": "any",
"select": "job_id,agency,business_title,civil_service_title,work_location,job_description",
"orderby": "civil_service_title",
"top": "5",
"skip": "5"
}
Дальнейшие действияNext steps
Попробуйте указать запросы в коде.Try specifying queries in code. Следующие ссылки содержат сведения о настройке поисковых запросов с помощью пакетов SDK для Azure.The following links explain how to set up search queries using the Azure SDKs.
Дополнительные справочные материалы по синтаксису, архитектуре запросов и примеры можно найти по следующим ссылкам:Additional syntax reference, query architecture, and examples can be found in the following links:
[ELMA3] Пример написания простого отчета
В данной статье рассмотрен процесс создания простого отчета «от и до»: формирование запроса в базу данных (далее по тексту — БД), настройку параметров отчета, моделирование макета отчета. В качестве примера выбран отчет по контрагентам с выводом информации об отрасли и ответственном менеджере контрагента – условно назовем отчет – Новый отчет.
В качестве примера выбран отчет по контрагентам с выводом информации об отрасли и ответственном менеджере контрагента – условно назовем отчет – Новый отчет.
Дизайнер
В Дизайнере в разделе Отчеты создаем Новый отчет, который будет выводить информацию о контрагентах, отрасль и ответственных за контрагентов. Используем справочники Контрагенты, Пользователи, Отрасль. Данные объекты можно найти на вкладке Источники данных отчета, в правой части окна – Объекты БД. В Объектах БД можно найти нужный справочник по полю Отображаемое имя, затем посмотреть имя таблицы в БД по полю Имя.
7Редактирование источника данных
1.1. На верхней панели выбираем пункт Редактировать и указываем язык запроса SQL.
1.2. На вкладке Параметры вводим параметр для отчета Ответственный менеджер (Тип: Пользователь, связь: Одиночная).
1.2 . Пишем запрос, который будет выводить Наименование контрагента, его отрасль и ответственного за данного контрагента. Все указанные поля по сути хранятся в одной таблице Контрагенты, но некоторые поля хранят в них только идентификаторы других таблиц, поэтому в запросе соединим нужные таблицы.
Текст запроса:
select Contractor.Name, ContractorIndustry.Industry, "User".FullName
from Contractor
left join "User" on Contractor.Responsible="User".Id
left join ContractorIndustry on Contractor.Industry=ContractorIndustry.Id
{if {$OtvetstvennyyMenedzher} <> Null }
where
"User".Id = {$OtvetstvennyyMenedzher.Id}
{end if}Описание запроса:
select Contractor.Name, ContractorIndustry.Industry, «User».FullName – выбираем поле Name из таблицы Contractor (Наименование контрагента), поле Industry из таблицы ContractorIndustry (Отрасль контрагента), поле FullName из таблицы «User» (Ответственный за контрагента).
from Contractor – указываем из какой таблицы брать данные.
left join «User» on Contractor.Responsible=»User».Id – соединяем таблицу User с таблицей Contractor через поле Responsible (Ответственный) из таблицы Contractor с полем Id из таблицы User. Это необходимо, чтобы в результате отчета в выводимом поле Ответственный было полное имя сотрудника, не его ID.
left join ContractorIndustry on Contractor.Industry=ContractorIndustry.Id – соединяем таблицу ContractorIndustry с таблицей Contractor через поле Industry (Отрасль) из таблицы Contractor с полем Id из таблицы ContractorIndustry. Это необходимо, чтобы в результате отчета в выводимом поле Отрасль было название отрасли, не его ID.
{if {$OtvetstvennyyMenedzher} <> Null }
where
«User».Id = {$OtvetstvennyyMenedzher.Id}
{end if} — указываем условие, при котором при пустом значении параметра Ответственный менеджер, будут показываться все записи, а при указанном параметре – будет отображаться только отфильтрованная запись.
Макет отчета
Переходим на вкладку Макет, где рисуем отображение отчета на FastReport в веб-части.
Выводим полученные Данные на макет: в часть Data: Данные. Переименовываем колонки.
Для проверки полученного отчета можно запустить режим отладки по соответствующей кнопке – Отладка.
Если не указывать Ответственного менеджера, получим следующий результат:
Укажем в параметре конкретного сотрудника – Администратор ELMA и снова покажем отчет:
В результате выведены те контрагенты, у которых ответственным менеджером назначен Администратор ELMA.
Сохраняем и публикуем отчет, после чего он станет доступен в веб-части для пользователей.
Таким образом, можно написать простой отчет с использованием одно параметра, с макетом на FastReport.
Простой пример разработки в команде технического проекта
Рассмотрим простой пример групповой разработки, который может использоваться в команде технического проекта.
К этому моменту существует удалённый репозиторий, в который конвертирована конфигурация из основного хранилища. Руководитель проекта создал в нём ветку tech-project/000001, в которой будет вестись разработка. В команде проекта есть два разработчика: Андрей и Василий.
Первый разработчик, Андрей, клонирует удалённый репозиторий. Для этого он переходит в перспективу
Git и в панели
Репозитории Git выполняет команду
Клонировать
репозиторий Git. Для разработки ему нужна только ветка
tech-project/000001, поэтому в мастере клонирования репозитория он отмечает только её.
Затем он делает изменения и создаёт локальный коммит 88a45e3 ().
Второй разработчик, Василий, выполняет то же самое — клонирует удалённый репозиторий и делает коммит с изменениями e81fdd8.
Теперь Василий отправляет свою работу на сервер ().
История коммитов его локального репозитория и история коммитов удалённого репозитория становятся одинаковыми.
Андрей также пытается отправить свои изменения на сервер.
Андрей не может выполнить отправку изменений, так как за это время Василий уже отправил свои. Это очень важно понять, так как мы видим, что эти два разработчика не редактировали один и тот же объект. При использовании Git’а, даже если редактировались разные объекты, вы должны слить коммиты локально.
Прежде чем Андрей сможет отправить свои изменения на сервер, он должен извлечь наработки Василия и затем выполнить слияние. Это выполняется одной командой .
Слияние прошло без проблем — история коммитов Андрея теперь выглядит как на рисунке:
Теперь Андрей может протестировать свой код, дабы удостовериться, что он по-прежнему работает нормально, а затем отправить свою работу, уже
объединённую с работой Василия, на сервер.
В результате история коммитов Андрея выглядит, как показано на рисунке:
Тем временем, Василий работал над тематической веткой. Он создал тематическую ветку с названием Проект54 () и сделал три коммита в этой ветке. Он ещё не получал изменения Андрея, так что его история коммитов выглядит, как показано на рисунке:
Василий хочет синхронизировать свою работу с Андреем, так что он извлекает изменения с сервера ().
Эта команда извлекает наработки Андрея, которые он успел выложить. История коммитов Василия теперь выглядит как на рисунке.
Теперь Василий может слить ветку tech-project/000001 со своей тематической веткой, слить свою ветку tech-project/000001 с работой Андрея ( origin/tech-project/000001), и затем отправить изменения на сервер.
Сначала он переключается на свою основную ветку tech-project/000001, чтобы объединить всю эту работу ().
Он может слить сначала ветку origin/tech-project/000001, а может и Проект54 — обе они находятся
выше в истории коммитов, так что не важно, какой порядок слияния он выберет. Конечное состояние репозитория должно получиться идентичным
независимо от того, какой порядок слияния он выберет; только история коммитов будет немного разная.
Конечное состояние репозитория должно получиться идентичным
независимо от того, какой порядок слияния он выберет; только история коммитов будет немного разная.
Он решает слить ветку Проект54 первой ().
Никаких проблем не возникло. Как видите, это была обычная перемотка.
Теперь Василий сливает работу Андрея ( origin/tech-project/000001).
Слияние проходит нормально, и теперь история коммитов Василия выглядит так, как показано на рисунке.
Теперь указатель origin/tech-project/000001 доступен из ветки tech-project/000001 Василия, так что он может спокойно отправить изменения на сервер (полагая, что Андрей не выкладывал свои изменения за это время):
В результате история коммитов Василия выглядит так, как показано на следующем рисунке. Каждый разработчик несколько раз выполнял коммиты и успешно сливал свою работу с работой другого.
Это один из простейших рабочих процессов. Вы работаете некоторое время, преимущественно в тематической ветке. Когда вы готовы поделиться
этой работой с другими, вы сливаете её в ветку
tech-project/000001, извлекаете изменения с сервера и сливаете
origin/tech-project/000001 (если за это время произошли изменения), и, наконец, отправляете свои изменения в ветку
tech-project/000001 на сервер. Общая последовательность действий выглядит так, как показано на рисунке:
Когда вы готовы поделиться
этой работой с другими, вы сливаете её в ветку
tech-project/000001, извлекаете изменения с сервера и сливаете
origin/tech-project/000001 (если за это время произошли изменения), и, наконец, отправляете свои изменения в ветку
tech-project/000001 на сервер. Общая последовательность действий выглядит так, как показано на рисунке:
Обновление ветки репозитория по состоянию основного хранилища
Через некоторое время после начала разработки технического проекта в основном хранилище было исправлено несколько ошибок. Руководитель проекта решает обновить репозиторий до состояния основного хранилища.
Для этого он получает изменения из удалённого репозитория ().
При этом, как вы видите, в ветку
master будут получены изменения, выполненные в основном хранилище, и перенесенные в репозиторий автоматически,
конфигурацией
1С:ГитКонвертер. А в ветку
tech-project/000001 будут получены изменения, выполненные за это время Андреем и Василием.
В результате история коммитов у руководителя проекта будет выглядеть следующим образом:
Основная ветка у него tech-project/000001, поэтому он может выполнить Получить и слить для того, чтобы слить её с изменениями Андрея и Василия ( origin/tech-project/000001).
В результате его история коммитов будет выглядеть следующим образом:
Теперь он может слить свою локальную ветку tech-project/000001 с удалённой веткой origin/master, чтобы объединить локальную ветку с изменениями, появившимися в основном хранилище.
В результате его история коммитов будет выглядеть следующим образом:
После этого он тестирует прикладное решение, дабы удостовериться, что оно по-прежнему работает нормально. А после этого отправляет ветку tech-project/000001 на сервер, чтобы Андрей и Василий могли использовать обновлённую версию разрабатываемого прикладного решения.
В результате история коммитов на сервере выглядит следующим
образом.
Руководитель проекта оповещает Андрея и Василия о том, что он обновил ветку технического проекта. Поэтому Андрей, прежде чем начать очередные изменения, сначала получает с сервера последние изменения и сливает их со своей локальной веткой ().
В результате Андрей имеет у себя ту же историю коммитов, которая находится на удалённом сервере.
37 Примеры простых предложений и рабочий лист
Если вы не знаете, что делает предложение простым, эти 37 примеров простых предложений помогут прояснить ситуацию. Этот тип предложения может иметь только одно независимое предложение. Он может быть длинным или коротким, но основная структура всегда одна и та же. Есть несколько типов простых предложений. Прочтите каждый тип ниже и используйте рабочий лист, чтобы научиться писать собственные простые предложения.
Одно подлежащее и один глагол
Простые предложения состоят из одного подлежащего и одного глагола или сказуемого.У некоторых из них есть прямой объект или модификатор, но у них по-прежнему есть только одно подлежащее и один глагол. Если вам нужно освежить в памяти эти части речи, прочтите статью «Понимание предметов, предикатов и объектов». Следующие примеры показывают, как это работает:
Если вам нужно освежить в памяти эти части речи, прочтите статью «Понимание предметов, предикатов и объектов». Следующие примеры показывают, как это работает:
- Кот потянулся.
- Джейкоб встал на цыпочки.
- Автомобиль повернул за угол.
- Келли кружила по кругу.
- Она открыла дверь.
- Аарон сфотографировал.
- Прошу прощения.
- Я танцевал.
Посмотреть и скачать PDF
Примеры с подразумеваемым предметом
В некоторых простых предложениях есть только подлежащее и глагол, но подлежащее в предложении не указано. Вместо этого читатель знает, кто является объектом, из контекста. Вы заметите, что многие из этих коротких примеров являются повелительными предложениями с подразумеваемым подлежащим «вы»:
- Беги!
- Осторожно откройте банку.
- Прочтите указания.
- Не плачь.
- Руководствуйтесь здравым смыслом.
- Сделайте все возможное.
- Догоняй!
В этих предложениях есть только одно независимое предложение. Освежите в памяти разницу между независимыми и зависимыми предложениями, если вам нужны пояснения.
Освежите в памяти разницу между независимыми и зависимыми предложениями, если вам нужны пояснения.
Составное подлежащее и один глагол
Вы также увидите простые предложения с составным подлежащим и одним глаголом. В этом случае подлежащие соединяются союзом типа «и», и все они выполняют действие, описанное в глаголе.Здесь также могут быть модификаторы и прямые объекты, как вы увидите в некоторых из этих примеров:
- Сара и Ира поехали в магазин.
- Мы с Дженни открыли все подарки.
- Съели кошка и собака.
- Мы с родителями пошли в кино.
- Миссис Хуарес и мистер Смит грациозно танцуют.
- Саманта, Элизабет и Джоан входят в комитет.
- Ветчина, стручковая фасоль, картофельное пюре и кукуруза не содержат глютен.
- Бумага и карандаш простаивали на столе.
Одно подлежащее и составной глагол
Вы также увидите несколько простых предложений с более чем одним глаголом и одним подлежащим. В данном случае это составные глаголы. Субъект выполняет все действия, и действия идут вместе. Проще всего в этом убедиться на нескольких примерах:
В данном случае это составные глаголы. Субъект выполняет все действия, и действия идут вместе. Проще всего в этом убедиться на нескольких примерах:
- Миша прошелся и огляделся.
- Моя мама хмыкнула и решила, куда пойти пообедать.
- Он ел и разговаривал.
- Я сполоснул и высушил посуду.
- Джо встал и обратился к толпе.
Примеры более длинных простых предложений
Хотя простое предложение может состоять из одного слова, оно также может быть намного длиннее. Добавление модификаторов или нескольких прямых объектов может увеличить длину предложения. Все эти примеры представляют собой простые предложения, несмотря на их длину:
- Паршивый, тощий бродячий пес поспешно проглотил беззерновой органический корм для собак.
- Я быстро надел красную зимнюю куртку, черные зимние штаны, непромокаемые ботинки, самодельные варежки и шарф ручной вязки.
- Непрерывное тиканье и перезвон эхом отражались от обветренных стен мастерской по ремонту часов.
- Я нервно развернул сморщенное и испачканное письмо моего давно умершего предка.
- В чемодан я небрежно бросил пару рваных джинсов, мой любимый свитер из средней школы, старую пару носков с полосками и 20 000 долларов наличными.

Примеры простых предложений из литературы
Писатели использовали простые предложения с тех пор, как люди писали.Рассмотрим эти примеры из литературы:
- «Духи всех трех будут стремиться во мне». Рождественская песнь Чарльза Диккенса
- «Я был более обманут». Офелия в Гамлете Уильяма Шекспира
- «Ни один мальчик не говорил». Приключения Тома Сойера Марка Твена
- «Зовите меня Измаил». Moby Dick by Herman Melville
Понять структуру предложения
Теперь, когда вы знаете о простых предложениях и видели несколько примеров, найдите время, чтобы узнать о других типах предложений, таких как составные предложения и сложные предложения. Чем больше вы знаете о том, как составляются предложения, тем лучше станет ваше письмо.
Чем больше вы знаете о том, как составляются предложения, тем лучше станет ваше письмо.
ENG 1001: Предложения: простые, сложные и сложные
Предложения: простые, сложные и сложные
Распространенная слабость письма — отсутствие разнообразных предложений. Осознавая трех основных типов предложений — простого, сложного и сложного — могут помочь вам варьируйте предложения в своем письме.
Для наиболее эффективного письма используется Разновидность типы предложений описаны ниже.
1. Простые предложения
Простое предложение содержит самые основные элементы, которые делают его предложение: подлежащее, глагол и завершенная мысль.
Примеры простых предложений включают следующее:
- Джо ждал поезда.
«Джо» = субъект, «ожидал» = глагол - Поезд опаздывал.
«Поезд» = субъект, «был» = глагол - Мэри и Саманта сели в автобус.
«Мэри и Саманта» = составное подлежащее, «взяла» = глагол - Я искал Мэри и Саманту на автобусной станции.
«Я» = субъект, «посмотрел» = глагол - Мэри и Саманта прибыли на автовокзал рано, но ждали
до полудня на автобусе.
«Мария и Саманта» = составной предмет, «прибыл» и «ожидал» = составной глагол
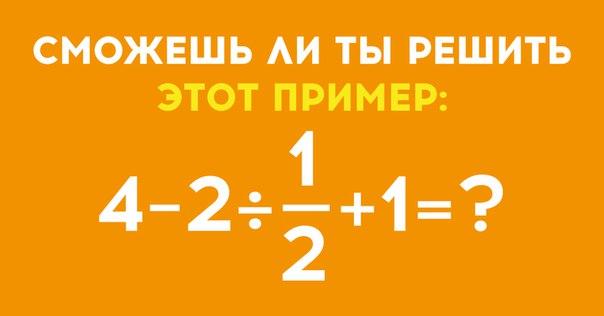
Совет : Если вы используете много простых предложений в эссе, вам следует подумать о том, чтобы пересмотреть некоторые предложений в составные или сложные предложения (объяснено ниже).
использование составных подлежащих, составных глаголов, предложных фраз (таких как «на автовокзале»), а другие элементы помогают удлинить простые предложения, но простые предложения часто бывают короткими. Использование слишком большого количества простых предложения могут сделать письмо «прерывистым» и помешать письму течет плавно.
Простое предложение может также именоваться независимым предложением . Это
называется «независимым», потому что, хотя он может быть частью
составное или сложное предложение, оно также может стоять само по себе как законченное предложение.
2. Сложные приговоры
Составное предложение относится к предложению, состоящему из двух независимых предложения (или полные предложения), связанные друг с другом с помощью согласования Соединение . Координационные союзы легко запомнить, если вспомнить слова «FAN BOYS»:
- Факс или
- A nd
- N или
- В ут
- O r
- Y и
- S или
Примеры составных предложений включают следующее:
- Джо ждал поезда, но поезд опаздывал.
- Я искал Мэри и Саманту на автовокзале, но они прибыли на вокзал раньше
полдень и уехал на
автобус до того, как я приехал.
- Мэри и Саманта прибыли на автовокзал до полудня, и уехали на
автобус до того, как я приехал.
- Мэри и Саманта вышли на
автобус до моего приезда, , так что я их не видел на автовокзале.

Совет : если вы в значительной степени полагаетесь на составные предложения в сочинении, вам следует подумать о том, чтобы преобразовать некоторые из них в сложные предложения (объяснено ниже).
Координационные союзы полезны для соединения предложений, но составные предложения часто используются слишком часто. При согласовании союзов можно указать на некоторые тип связи между двумя независимыми предложениями в предложении, они иногда не указывают на отношения. Слово «и» для Например, добавляет только одно независимое предложение к другому, не указывая, как две части предложения логически связаны. Слишком много сложных предложений, которые использование «и» может ослабить написание.
Более четкие и конкретные отношения могут быть установлены с помощью
сложные предложения.
3. Сложные предложения
Сложное предложение состоит из независимого предложения и одного или нескольких
К нему подключены зависимых статьи, . А
зависимое предложение похоже на независимое предложение или полное предложение, но
в нем отсутствует один из элементов, которые сделали бы его законченным предложением.
А
зависимое предложение похоже на независимое предложение или полное предложение, но
в нем отсутствует один из элементов, которые сделали бы его законченным предложением.
Примеры зависимых статей включают следующее:
- , потому что Мэри и Саманта прибыли на автовокзал до полудня
- пока ждал на вокзале
- после того, как уехали на автобусе
Зависимые предложения, такие как те, что выше , не могут быть выделены отдельно как предложение, но их можно добавить к самостоятельное предложение для образования сложного предложения.
Зависимые предложения начинаются с подчиненных союзов . Ниже приведены некоторые из наиболее распространенных подчинительных союзов:
- после
- хотя
- как
- потому что
- до
- хотя
- если
- с
- хотя
- , кроме С
- до
- когда
- всякий раз, когда
- тогда как
- везде
- , а
Сложное предложение объединяет независимое предложение с одним или несколькими зависимыми предложениями.
Зависимые предложения могут стоять первыми в предложении, за ними следует независимое предложение, как в следующем примере:
Совет : Когда зависимое предложение идет первым, для разделения этих двух предложений следует использовать запятую.
- Поскольку Мэри и Саманта прибыли на автовокзал до полудня, я не увидел их на вокзале.
- Пока он ждал на вокзале, Джо понял, что поезд опаздывает.
- После того, как они уехали на автобусе, Мэри и Саманта поняли, что Джо ждал на вокзале.
И наоборот, независимые предложения могут стоять первыми в предложении, за ними следует зависимое предложение, как в следующем примере:
Совет : Когда независимое предложение идет первым, для разделения двух предложений следует использовать запятую , а не .
- Я не видел их на вокзале, потому что Мэри и Саманта прибыли на автовокзал до полудня.
- Джо понял, что поезд опаздывает, когда он ждал на вокзале.
- Мэри и Саманта поняли, что Джо ждал на вокзале после того, как уехали на автобусе.

Сложные предложения часто более эффективны, чем составные предложения, потому что сложное предложение указывает на более четкие и конкретные отношения между основными частями предложения. Слово «раньше» например, говорит читателям, что одно происходит раньше другого. Такое слово, как «хотя», передает более сложные отношения, чем такое слово, как «и».
Термин периодическое предложение используется для обозначения сложного предложения, начинающегося с зависимого предложения и оканчивается независимой оговоркой, например: «Пока он ждал на вокзале, Джо понял, что поезд опаздывает.»Периодические предложения могут быть особенно эффективными, потому что завершенная мысль возникает в конец, так что первая часть предложения может развиваться до значения, которое приходит в конце.
Начальные предложения с «И» или «Потому что»
Если вы начинаете предложение с «и» или «но» (или одного из других союзы)?
Короткий ответ — «нет». Не следует начинать предложение с «и», «или», «но» или другого
координирующие союзы.Эти слова обычно используются для соединения частей
предложения, а не начинать новое предложение.
Не следует начинать предложение с «и», «или», «но» или другого
координирующие союзы.Эти слова обычно используются для соединения частей
предложения, а не начинать новое предложение.
Однако такие предложения можно использовать эффективно. Поскольку предложения, начинающиеся с этих слов, выделяются, они иногда используются для выделения. Если вы используете предложения, начинающиеся с одного из координирующих союзов, вам следует использовать эти предложения экономно и осторожно.
Следует ли начинать предложение со слова «потому что»?
Нет ничего плохого в том, чтобы начинать предложение со слов «потому что».«
Возможно, некоторым студентам предлагается не начинать предложение со слова «потому что», чтобы избежать фрагментов предложения. (что-то вроде «Потому что Мэри и Саманта прибыли на автовокзал до полудня» — это фрагмент предложения), но это прекрасно приемлемо начинать предложение с «потому что», пока предложение является полным (например, «Потому что Мэри и Саманта пришли к автовокзал до полудня, на вокзале я их не видел »)
Смотри!
 youtube.com/embed/Hby4NBOwf7E?rel=0″ frameborder=»0″ allowfullscreen=»»/>
youtube.com/embed/Hby4NBOwf7E?rel=0″ frameborder=»0″ allowfullscreen=»»/>
Простые, сложные и сложные предложения из Центра письма в Техасе A &
M
Простое предложение — примеры и определение простого предложения
Определение простого предложения
Простое предложение в грамматике имеет только одно главное или независимое предложение и не имеет зависимых или подчиненных предложений.Этот короткий и независимый синтаксический объект, состоящий из субъекта и предиката, предназначен для передачи полной идеи или значений идеи.
Простое предложение также известно как приговор по делу. У него может быть модификатор помимо подлежащего, глагола и объекта. Хотя он простой, иногда в нем могут быть составные глаголы и составные подлежащие. Он может использовать или не использовать запятые, но остается простым по конструкции. Например, «Исследования служат для удовольствия, украшения и способности». ( Исследования , Фрэнсис Бэкон)
Обычное употребление простого предложения
- Перо сильнее меча.
- Алиса каждый день ходит в библиотеку учиться.
- Возможно, упадок этой страны уже начался.
- Руководство вашей компании отлично выполнило свои обязанности.
- Людям, живущим в стеклянных домах, нельзя бросать камни.
- Они потеряли тысячи рабочих мест в Азии, Южной Америке и Мексике.

Типы простых предложений
Есть два разных типа простых предложений. В зависимости от структуры они включают:
- Составные глаголы и составные подлежащие — Некоторые предложения содержат одно подлежащее и два или более глаголов.В других предложениях есть один глагол и два или более подлежащих. Например:
- Собака лаяла и побежала (Составной глагол)
- Джек и Джилл поднялись на холм. (Составное существительное)
- Арнольд и Хуан каждый вечер играют в крикет. (Составное существительное)
- Кот и собака выли и выли соответственно. (Сложный глагол)
- Джулия и Мэри наняли такси до аэропорта. (Составное существительное)
 (Составное существительное)
(Составное существительное)Слова, выделенные курсивом в приведенных выше простых предложениях, являются составными глаголами или составными существительными соответственно.
- Одно подлежащее и один глагол — Этот тип простого предложения имеет только одно подлежащее и один глагол. Например:
- Персонал хорошо отработал.
- Белая рубашка всегда выглядит круто.
- Продал по высокой цене на амазоне.
- Чтобы мечта стала реальностью, нужно мечтать.
Примеры простых предложений в литературе
Пример № 1:
Большой сон (Раймонд Чендлер)«На мне был пудрово-синий костюм с темно-синей рубашкой, галстуком и платком, черные броги, черные шерстяные носки с темно-синими часами на них.
Чендлер прекрасно использовал простое предложение с несколькими предметами, чтобы описать свой синий костюм. Зависимых предложений нет. Одно независимое предложение передает полное представление.
Пример № 2:
Пробуждение (Кейт Шопен)«Она становилась собой и каждый день отбрасывала то вымышленное« я », которое мы принимаем как одежду, в которой предстаем перед миром».
Это еще один отличный пример простого предложения без использования запятых.Это просто одно предложение без придаточных предложений.
Пример № 3:
Чрезвычайно громко и невероятно близко (Джонатан Сафран Фоер)«Иногда я чувствую, как мои кости напрягаются под тяжестью всех жизней, которыми я не живу».
В приведенном выше примере автор использовал короткое и независимое предложение, чтобы передать полное представление о растяжении костей.
Пример № 4:
Гордость и предубеждение (Джейн Остин)«Mr.Беннет был одним из первых из тех, кто прислуживал мистеру Бингли ».
Здесь Остин использовал простое и декларативное предложение без каких-либо запятых и предложений, чтобы описать черты характера мистера Беннета.
Пример № 5:
Сорокопут и бурундуки (Джеймс Тербер)«Ранний подъем и ранний сон делают самца здоровым, богатым и мертвым».
Это простое предложение может стоять отдельно. Он передает идею о том, чтобы вставать рано утром, всего в одном предложении, поясняющем значение.
Пример № 6:
Принцесса-невеста (Уильям Голдман)«Удачи штурму замка!»
Это очень простое и понятное утверждение с восклицательным знаком. Это независимое предложение передает эмоции автора своим читателям без волнений или сложности мысли.
Функция
Простое предложение — это одна из четырех основных структур предложения. Это простое утверждение. Он функционирует как средство коммуникации, добавляя информацию к существующим знаниям как говорящего, так и слушающего.Иногда писатели и ораторы используют это как мудрое высказывание или пословицу. Простое предложение избавляет от скуки и нервозности в письменных произведениях. Он также повышает ясность, точность и плавность чтения и речи, предоставляя ограниченный объем информации в краткой и точной форме.
Он также повышает ясность, точность и плавность чтения и речи, предоставляя ограниченный объем информации в краткой и точной форме.
Начало работы | Создание приложения с помощью Spring Boot
Если вы создаете веб-сайт для своего бизнеса, вам, вероятно, потребуется добавить некоторые службы управления. Spring Boot предоставляет несколько таких сервисов (например, работоспособность, аудит, bean-компоненты и т. Д.) С помощью модуля исполнительного механизма.
Если вы используете Gradle, добавьте в файл build.gradle следующую зависимость:
реализация 'org.springframework.boot: пружина-пыльник-стартер-привод' Если вы используете Maven, добавьте в файл pom.xml следующую зависимость:
<зависимость>
org.springframework.boot
пружинный пусковой механизм
Затем перезапустите приложение. Если вы используете Gradle, выполните следующую команду в окне терминала (в каталоге
Если вы используете Gradle, выполните следующую команду в окне терминала (в каталоге complete ):
Если вы используете Maven, выполните следующую команду в окне терминала (в каталоге complete ):
Вы должны увидеть, что в приложение был добавлен новый набор конечных точек RESTful. Это службы управления, предоставляемые Spring Boot. В следующем листинге показан типичный результат:
management.endpoint.configprops-org.springframework.boot.actuate.autoconfigure.context.properties.ConfigurationPropertiesReportEndpointProperties
management.endpoint.env-org.springframework.boot.actuate.autoconfigure.env.EnvironmentEndpointProperties
management.endpoint.health-org.springframework.boot.actuate.autoconfigure.health.HealthEndpointProperties
management.endpoint.logfile-org.springframework.boot.actuate.autoconfigure.logging.LogFileWebEndpointProperties
management.endpoints.jmx-org.springframework.boot.actuate. autoconfigure.endpoint.jmx.JmxEndpointProperties
management.endpoints.web-org.springframework.boot.actuate.autoconfigure.endpoint.web.WebEndpointProperties
management.endpoints.web.cors-org.springframework.boot.actuate.autoconfigure.endpoint.web.CorsEndpointProperties
management.health.status-org.springframework.boot.actuate.autoconfigure.health.HealthIndicatorProperties
management.info-org.springframework.boot.actuate.autoconfigure.info.InfoContributorProperties
management.metrics-org.springframework.boot.actuate.autoconfigure.metrics.MetricsProperties
management.metrics.export.simple-org.springframework.boot.actuate.autoconfigure.metrics.export.simple.SimpleProperties
management.server-org.springframework.boot.actuate.autoconfigure.web.server.ManagementServerProperties
management.trace.http-org.springframework.boot.actuate.autoconfigure.trace.http.HttpTraceProperties  autoconfigure.endpoint.jmx.JmxEndpointProperties
management.endpoints.web-org.springframework.boot.actuate.autoconfigure.endpoint.web.WebEndpointProperties
management.endpoints.web.cors-org.springframework.boot.actuate.autoconfigure.endpoint.web.CorsEndpointProperties
management.health.status-org.springframework.boot.actuate.autoconfigure.health.HealthIndicatorProperties
management.info-org.springframework.boot.actuate.autoconfigure.info.InfoContributorProperties
management.metrics-org.springframework.boot.actuate.autoconfigure.metrics.MetricsProperties
management.metrics.export.simple-org.springframework.boot.actuate.autoconfigure.metrics.export.simple.SimpleProperties
management.server-org.springframework.boot.actuate.autoconfigure.web.server.ManagementServerProperties
management.trace.http-org.springframework.boot.actuate.autoconfigure.trace.http.HttpTraceProperties
autoconfigure.endpoint.jmx.JmxEndpointProperties
management.endpoints.web-org.springframework.boot.actuate.autoconfigure.endpoint.web.WebEndpointProperties
management.endpoints.web.cors-org.springframework.boot.actuate.autoconfigure.endpoint.web.CorsEndpointProperties
management.health.status-org.springframework.boot.actuate.autoconfigure.health.HealthIndicatorProperties
management.info-org.springframework.boot.actuate.autoconfigure.info.InfoContributorProperties
management.metrics-org.springframework.boot.actuate.autoconfigure.metrics.MetricsProperties
management.metrics.export.simple-org.springframework.boot.actuate.autoconfigure.metrics.export.simple.SimpleProperties
management.server-org.springframework.boot.actuate.autoconfigure.web.server.ManagementServerProperties
management.trace.http-org.springframework.boot.actuate.autoconfigure.trace.http.HttpTraceProperties Привод показывает следующее:
Существует также конечная точка / actator / shutdown , но по умолчанию она видна только через JMX. Чтобы включить его в качестве конечной точки HTTP, добавьте Чтобы включить его в качестве конечной точки HTTP, добавьте management.endpoint.shutdown.enabled = true в файл application.properties и выставьте его с помощью management.endpoints.web.exposure.include = health, info, shutdown . Однако вам, вероятно, не следует включать конечную точку выключения для общедоступного приложения. |
Вы можете проверить работоспособность приложения, выполнив следующую команду:
$ curl localhost: 8080 / исполнительный механизм / здоровье
{"status": "UP"} Вы также можете попробовать вызвать завершение работы через curl, чтобы увидеть, что произойдет, если вы не добавили необходимую строку (показанную в предыдущем примечании) в приложение .свойства :
$ curl -X POST localhost: 8080 / активатор / выключение
{"timestamp": 1401820343710, "error": "Not Found", "status": 404, "message": "", "path": "/ actator / shutdown"} Поскольку мы не включили его, запрошенная конечная точка недоступна (поскольку конечная точка не существует).
Для получения дополнительных сведений о каждой из этих конечных точек REST и о том, как настроить их параметры с помощью файла application.properties (в src / main / resources ), см. Документацию по конечным точкам.
1.1 Простой пример | Разработка и выбор функций: практический подход к прогнозным моделям
Простой пример
В качестве простого примера того, как разработка функций может повлиять на модели, рассмотрим рисунок 1.2a, на котором показан график двух коррелированных переменных-предикторов (обозначенных как A и B ). Точки данных окрашены в соответствии с их результатом, дискретной переменной с двумя возможными значениями («PS» и «WS»). Эти данные взяты из эксперимента Hill et al.(2007), который включает более широкий набор предикторов. Для их задачи модель потребует высокой степени точности, но ее не нужно будет использовать для вывода. Для этой иллюстрации будут рассмотрены только эти два предиктора. На этом рисунке видно диагональное разделение между двумя классами. Здесь будет использоваться простая модель логистической регрессии (Hosmer and Lemeshow 2000), чтобы создать уравнение прогноза на основе этих двух переменных. В этой модели используется следующее уравнение:
На этом рисунке видно диагональное разделение между двумя классами. Здесь будет использоваться простая модель логистической регрессии (Hosmer and Lemeshow 2000), чтобы создать уравнение прогноза на основе этих двух переменных. В этой модели используется следующее уравнение:
\ [журнал (p / (1-p)) = \ beta_0 + \ beta_1 A + \ beta_2 B \]
, где p — это вероятность того, что выборка относится к классу «PS», а значения \ (\ beta \) — это параметры модели, которые необходимо оценить на основе данных.
Рисунок 1.2: (а) пример набора данных и (б) кривая ROC из простой модели логистической регрессии.
Стандартная процедура (оценка максимального правдоподобия) используется для оценки трех параметров регрессии на основе данных. Авторы использовали 1009 точек данных для оценки параметров (т.е. обучающий набор ) и зарезервировали 1010 выборок строго для оценки производительности (набор тестов ). Используя обучающую выборку, параметры были оценены как \ (\ hat {\ beta_0} = 1. 73 \), \ (\ hat {\ beta_1} = 0,003 \) и \ (\ hat {\ beta_2} = -0,064 \).
73 \), \ (\ hat {\ beta_1} = 0,003 \) и \ (\ hat {\ beta_2} = -0,064 \).
Для оценки модели на тестовой выборке делаются прогнозы. Логистическая регрессия естественным образом производит вероятности классов, которые дают указание на вероятность для каждого класса. Хотя для прогнозирования жесткого класса обычно используется ограничение на 50%, производительность, полученная при использовании этого значения по умолчанию, может вводить в заблуждение. Чтобы избежать применения ограничения вероятности, здесь используется метод, называемый кривой рабочей характеристики приемника (ROC).Кривая ROC оценивает результаты по всем возможным отсечениям и отображает соотношение истинно положительных результатов и ложноположительных результатов. Кривая для этого примера показана на рисунке 1.2b. Наилучшая возможная кривая — это та, которая смещена как можно ближе к верхнему левому углу, а неэффективная модель останется вдоль пунктирной диагональной линии. Общим суммарным значением для этого метода является использование области под кривой ROC, где значение 1,0 соответствует идеальной модели, а значения около 0,5 указывают на модель без возможности прогнозирования. Для текущей модели логистической регрессии площадь под кривой ROC составляет 0,794, что указывает на умеренную точность классификации ответа.
Для текущей модели логистической регрессии площадь под кривой ROC составляет 0,794, что указывает на умеренную точность классификации ответа.
С учетом этих двух переменных-предикторов имеет смысл попробовать различные преобразования и кодировки этих данных в попытке увеличить площадь под кривой ROC. Поскольку оба предиктора больше нуля и, по-видимому, имеют распределения со смещением вправо, можно было бы склониться к тому, чтобы взять отношение A / B и ввести только этот член в модель.В качестве альтернативы мы могли бы также оценить, будут ли полезны простые преобразования каждого предиктора. Одним из методов является преобразование Бокса-Кокса, в котором используется отдельная процедура оценки до модели логистической регрессии, которая может поместить предикторы в новую шкалу. Используя эту методологию, процедура оценки Бокса-Кокса рекомендовала использовать оба предиктора в обратной шкале (т. Е. 1/ A вместо A ). Это представление данных показано на рисунке 1. 3а. Когда эти преобразованные значения были введены в модель логистической регрессии вместо исходных значений, площадь под кривой ROC изменилась с 0,794 до 0,848, что является значительным увеличением. На рисунке 1.3b показаны обе кривые. В этом случае кривая ROC, соответствующая преобразованным предикторам, всегда лучше, чем исходный результат.
3а. Когда эти преобразованные значения были введены в модель логистической регрессии вместо исходных значений, площадь под кривой ROC изменилась с 0,794 до 0,848, что является значительным увеличением. На рисунке 1.3b показаны обе кривые. В этом случае кривая ROC, соответствующая преобразованным предикторам, всегда лучше, чем исходный результат.
Рисунок 1.3: (а) преобразованные предикторы и (б) кривая ROC из обеих моделей логистической регрессии.
Этот пример демонстрирует, как изменение предикторов, в данном случае простое преобразование, может привести к повышению эффективности модели.При сравнении данных на рисунках 1.2a и 1.3a легче визуально различить две группы данных. При индивидуальном преобразовании данных мы позволили модели логистической регрессии лучше справляться с разделением классов. В зависимости от природы предикторов, использование инверсии исходных данных может затруднить выводный анализ.
Однако разные модели предъявляют разные требования к данным. Если асимметрия исходных предикторов была проблемой, влияющей на модель логистической регрессии, существуют другие модели, которые не имеют такой же чувствительности к этой характеристике.Например, нейронная сеть также может использоваться для подбора этих данных без использования обратного преобразования предикторов. Эта модель смогла достичь площади под кривой ROC 0,848, что примерно эквивалентно результатам улучшенной логистической модели. Можно сделать вывод, что модель нейронной сети всегда лучше, чем логистическая регрессия, поскольку нейронная сеть не восприимчива к распределительным аспектам предикторов. Но мы не должны делать такой общий вывод из-за теоремы «Нет бесплатного обеда» (см. Раздел 1.2.3). Кроме того, модель нейронной сети имеет свои недостатки: она совершенно не интерпретируема и требует обширной настройки параметров для достижения хороших результатов. В зависимости от того, как модель будет использоваться, одна из этих моделей может быть более подходящей для этих данных, чем другая.
Если асимметрия исходных предикторов была проблемой, влияющей на модель логистической регрессии, существуют другие модели, которые не имеют такой же чувствительности к этой характеристике.Например, нейронная сеть также может использоваться для подбора этих данных без использования обратного преобразования предикторов. Эта модель смогла достичь площади под кривой ROC 0,848, что примерно эквивалентно результатам улучшенной логистической модели. Можно сделать вывод, что модель нейронной сети всегда лучше, чем логистическая регрессия, поскольку нейронная сеть не восприимчива к распределительным аспектам предикторов. Но мы не должны делать такой общий вывод из-за теоремы «Нет бесплатного обеда» (см. Раздел 1.2.3). Кроме того, модель нейронной сети имеет свои недостатки: она совершенно не интерпретируема и требует обширной настройки параметров для достижения хороших результатов. В зависимости от того, как модель будет использоваться, одна из этих моделей может быть более подходящей для этих данных, чем другая.
Более подробное описание того, как различные функции могут по-разному влиять на модели, кратко дается в разделе 1.3. Перед этим примером в следующем разделе обсуждались несколько ключевых концепций, которые будут использоваться в этом тексте.
Простой пример | Soufflé • Инструмент синтеза журнала данных для статического анализа
Редактировать меняТеперь мы рассмотрим простую программу Datalog и исследуем некоторые особенности Soufflé. Это только вводит некоторые из самых основных доступных функций, и опытным пользователям рекомендуется поискать в другом месте.
Допустим, у нас есть файл журнала данных example.dl , содержимое которого показано на рисунке.
.decl край (x: число, y: число)
.входной край
.decl путь (x: число, y: число)
.output путь
path (x, y): - край (x, y).
path (x, y): - путь (x, z), край (z, y).
Мы видим, что edge является отношением . и поэтому будет считываться с диска. Кроме того,  input
input путь является отношением . Output и поэтому будет записан на диск.
Последние две строки говорят, что 1) «существует путь от x до y, если есть ребро от x до y», и 2) «существует путь от x до y, если существует путь от x до некоторого z, и есть ребро от этого z до y ».
Итак, если входное отношение ребро представляет собой пары вершин в графе, по этим двум правилам выходное отношение путь даст нам все пары вершин x и y, для которых существует путь в этом графе от x до y.
Например, если содержимое входного файла с разделителями табуляции edge.facts равно
Содержимое выходного файла path.csv после оценки этой программы будет
Мы можем оценить эту программу, запустив
$./ SRC / суфле -F. -D. example.dl
Опции -F и -D определяют каталоги для входных и выходных файлов соответственно. Итак, в этом случае
Итак, в этом случае edge.facts находится в текущем рабочем каталоге . Здесь же будут создаваться и path.csv .
Если бы вместо edge.facts находился в подкаталоге с именем input , а мы хотели бы иметь paths.csv в подкаталоге с именем output , мы могли бы сделать
$./ SRC / суфле -F./input -D./output example.dl
При таком запуске Soufflé используется режим интерпретатора , что означает, что программа Datalog оценивается немедленно. Суффле также поддерживает режим компилятора , который преобразует программу журнала данных в программу C ++, которая затем компилируется для создания исполняемого файла.
Итак, если мы запустим Суфле с опцией -o , как показано ниже.
$ ./src/souffle -F. -D. -oпример пример.дл
Мы получаем файл C ++ example.cpp и исполняемый файл example . Обратите внимание, что не было создано
Обратите внимание, что не было создано path.csv , так как программа еще не была оценена.
$ ls
example.dl
edge.facts
example.cpp
пример
Чтобы оценить нашу программу, мы должны запустить скомпилированный исполняемый файл
Обратите внимание, что скомпилированный исполняемый файл поддерживает параметры -F и -D , поэтому выполнение следующего также возможно.
$ ./example -F./input -D./output
Параметр -r особенно полезен для отладки, так как он создает отчет об отладке в формате html. Выполнение следующего приводит к созданию файла example.html с этим отчетом.
$ ./src/souffle -F. -D. -rexample.html example.dl
Суфле также позволяет профилировать с помощью опции -p . Выполнение следующего приведет к созданию нового файла example.log с журналом информации профилирования.
$ ./src/souffle -F. -D. -pexample.log example.dl
Чтобы проанализировать данные профилирования в example.log , нам нужно открыть его с помощью прилагаемой программы souffle-profile , как показано ниже.
$ ./src/souffle-profile example.log
Профилировщик включает множество функций, полезных для анализа производительности программ Datalog. Он также имеет справочный текст, который задается следующей командой.
$ ./src/souffle-profile -h
Как уже отмечалось, у Суфле есть много других полезных опций, так что обязательно изучите их!
будущее время по-французски
Что такое
Futur Simple? Le futur simple соответствует будущему времени в английском языке. В основном мы используем это время, чтобы говорить о планах или намерениях на будущее, а также делать прогнозы о том, что может произойти в будущем. Мы спрягаем будущее время, добавляя окончания -ai, -as, -a, -ons, -ez и -ont к инфинитиву глагола.
Мы спрягаем будущее время, добавляя окончания -ai, -as, -a, -ons, -ez и -ont к инфинитиву глагола.
Изучите все, что вам нужно знать о futur simple по французской грамматике, используя быстрые и простые примеры Lingolia, а затем проверьте свои знания в упражнениях.
Пример
- Demain, je rangerai les dossiers.
- Tu ne finiras jamais en une journée.
- Est-ce que tu pourras m’aider? Si на range à deux, на finira plus vite.
Когда использовать
futur simple на французском языкеМы используем futur simple в следующих случаях:
- , чтобы поговорить о будущих намерениях
- Пример:
- Demain je rangerai les dossiers. Завтра я отсортирую файлы.
- , чтобы делать предположения или предсказания о будущем
- Пример:
- Tu ne finiras jamais en une journée. Вы никогда не закончите это за один день.
- в условных предложениях (, если предложения)
- Пример:
- Si on range à deux, on finira plus vite. Если мы приберемся вместе, мы сделаем это быстрее.
 Вы никогда не закончите это за один день.
Вы никогда не закончите это за один день.Как спрягать
futur simple на французскомЧтобы спрягать futur simple , мы берем инфинитив глагола и добавляем следующие окончания (для глаголов -re мы удаляем последние e ):
Глаголы Avoir и être являются неправильными в глаголе Futur Simple .
Чтобы увидеть спряжение любого французского глагола в futur simple , перейдите к нашему спрягателю глаголов.
Исключения из правил спряжения
- Короткий e в основе слова получает серьезный акцент (акцентный могила) в Futur Simple
- Пример:
- вес peserto — je pèserai Модель
- для модели — je modèlerai
- Некоторые глаголы удваивают свои согласные.
- Пример:
- бросок jeterto — je jetterai
- Для некоторых глаголов, оканчивающихся на — rir , i опускается перед добавлением будущего окончания.
- Пример:
- Courirto Run — Je Courrai
- mourirto die — je mourrai
- Для глаголов, оканчивающихся на — yer, , y становится i в futur simple . (Для глаголов, оканчивающихся на — ayer , разрешены как y, так и i)
- Пример:
- работодатель, чтобы нанять — j’emploierai, tu emploieras, il emploiera, nous emploierons, vous emploierez, ils emploieront
payerto pay — je payerai / paierai
- Глаголы, оканчивающиеся на — или , являются неправильными в futur simple , как и aller, envoyer, faire и venir .Проверьте их спряжение в списке неправильных глаголов.
- Пример:
- pouvoirto иметь возможность — je pourrai , tu pourras , il pourra , nous pourrons , vous pourrez , ils pourront

Наши онлайн-упражнения для французского помогут вам изучить и практиковать грамматические правила в интерактивном режиме.