
Rel nofollow noindex: Noindex и Nofollow: как и зачем использовать в SEO оптимизации
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.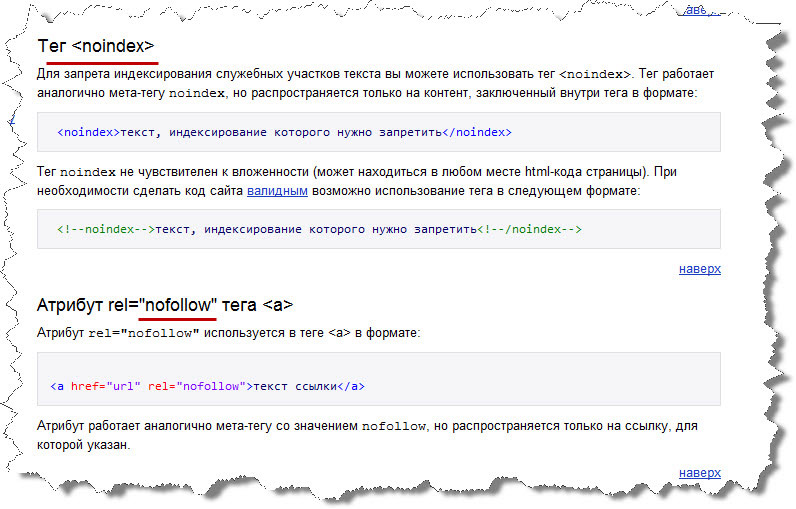
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.
 txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц. - <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
 txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots. txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
 txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
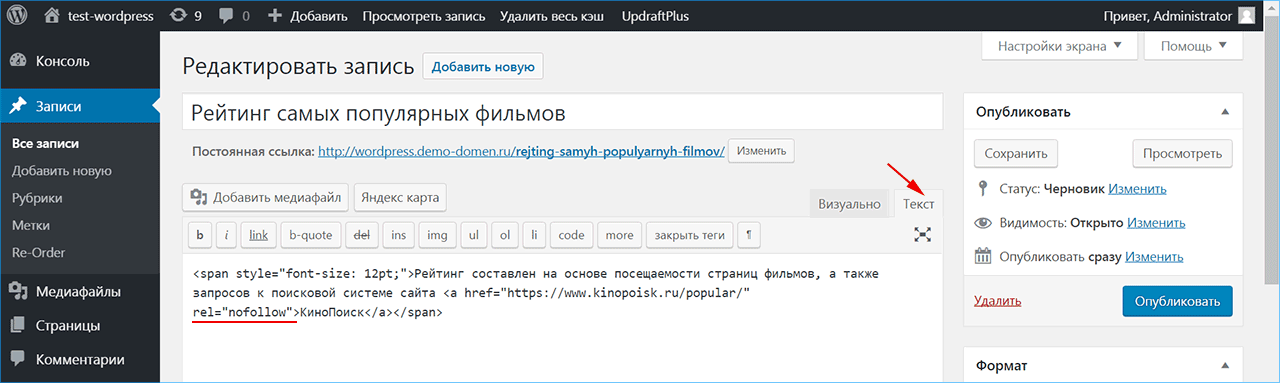
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.<a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
Нужно ли добавлять атрибут nofollow rel к ссылкам, если страница href содержит метатег роботов, содержащий noindex и nofollow?
Если у меня есть страница («dontFollowMe.html») с метатегом:
< meta name = "robots" content = "noindex, nofollow" / >
… и я ссылаюсь на эту страницу …
Нужно ли включать атрибут nofollow rel в элемент a? :
<a href="dontFollowMe.html" rel="nofollow">sign in</a>
Спасибо
html seo meta googlebot nofollowПоделиться Источник user1566224 06 февраля 2015 в 17:36
4 ответа
- Как добавить rel=»nofollow» к ссылкам с preg_replace()
Приведенная ниже функция предназначена для применения атрибутов rel=nofollow ко всем внешним ссылкам и никаких внутренних ссылок, если только путь не совпадает с предопределенным корнем URL, определенным как $my_folder ниже.
Итак, учитывая переменные… $my_folder = ‘http://localhost/mytest/go/’;… - SEO — noindex, nofollow и канонический тег
Мне нужно кое-что объяснить по поводу моего вопроса. Пример в моем заголовке уже добавлен <meta name=robots content=noindex, nofollow /> Должен ли я снова добавить канонический тег в свой заголовок? <link rel=”canonical” href=”http://www.example.com/product.php?item=big-fish” /> Дайте…
 Итак, учитывая переменные… $my_folder = ‘http://localhost/mytest/go/’;…
Итак, учитывая переменные… $my_folder = ‘http://localhost/mytest/go/’;…
5
Нет, вам не обязательно использовать nofollow на странице, которая не индексируется (по техническим причинам, как описано в вашем вопросе).
вес = «не передают ссылочный вес этой страницы. Просто притворись, что его не существует». Конечно, это всего лишь предложение поисковым системам.
noindex = » не индексируйте эту страницу. Мне все равно, будут ли другие страницы, связанные с ним, подписаны или нет, просто не индексируйте его. »
»
По SEO причинам: если этот вопрос предполагает, что вы ссылаетесь на внутреннюю страницу, то ответ на ваш вопрос будет заключаться в том, что обычно вы хотите не следовать ссылке на эту неважную страницу, а также не индексировать ее на неважной странице.
Поделиться rick6 06 февраля 2015 в 17:57
2
rel=»nofollow» будет сигнализировать искателям, чтобы они не следовали по ссылкам. Если вы хотите, чтобы пауки тратили качественное время на другие ссылки на странице, вы обычно добавляете rel=»nofollow» к ссылкам, которые вы не хотите обходить. Другая причина будет заключаться в том, что вы не можете поручиться за то, что есть на связанной странице. Наличие «no follow» на странице сигнализирует об отказе следовать по любым исходящим ссылкам на странице. Страница все равно будет сканироваться искателем google.
Поделиться minion 06 февраля 2015 в 18:41
0
nofollow как значение meta-robots и nofollow как тип ссылки означают разные вещи или точно то же самое, в зависимости от того, какому определению вы следуете ( подробнее ).
HTML5 определяет, что тип ссылки nofollow
[ … ] указывает на то, что ссылка не одобрена первоначальным автором или издателем страницы, или что ссылка на упомянутый документ была включена в основном из-за коммерческих отношений между людьми, связанными с этими двумя страницами.
Это не означает, что ссылка должна / не должна сопровождаться visitors/bots.
Поэтому, если вы не одобряете ссылку на ваш dontFollowMe.html или если вы добавили ее только по коммерческим причинам (например, реклама), вы не должны использовать тип ссылки nofollow .
Поделиться unor 07 февраля 2015 в 12:36
- Перенаправление исходящих ссылок и атрибут rel=»nofollow»-в чем разница?
Насколько я знаю, многие сайты добавляют атрибут rel=nofollow ко всем исходящим ссылкам внутри сообщений своего форума.
Насколько я понимаю, таким образом они говорят поисковым роботам не использовать эти ссылки для ранжирования веб-страниц. Кроме того, я заметил, что некоторые форумы используют… - Noindex, nofollow-достаточно ли поместить их в ответ HTTP?
Я думаю, что название этого вопроса говорит само за себя — при разработке и развертывании бета-версий, должен ли я поставить X-Robots-Tag: noindex, nofollow в ответе HTTP, или <meta name=robots content=noindex, nofollow> в разделе <head></head> каждой страницы?
 Насколько я понимаю, таким образом они говорят поисковым роботам не использовать эти ссылки для ранжирования веб-страниц. Кроме того, я заметил, что некоторые форумы используют…
Насколько я понимаю, таким образом они говорят поисковым роботам не использовать эти ссылки для ранжирования веб-страниц. Кроме того, я заметил, что некоторые форумы используют…
0
(Поскольку вы пометили свой вопрос тегом googlebot, я предполагаю, что ваш интерес связан с Google и атрибутом nofollow tag and link.)
Если у вас есть nofollow в качестве мета-тега, то вам не нужно добавлять отдельные ссылки, потому что :
Метатег nofollow robots применяется ко всем ссылкам на странице. Атрибут rel=»nofollow» link применяется только к определенным ссылкам на странице.
 Для получения дополнительной информации об атрибуте ссылки rel=»nofollow»,
пожалуйста, ознакомьтесь со статьями нашего справочного центра о пользовательском спаме и
rel=»nofollow».
Для получения дополнительной информации об атрибуте ссылки rel=»nofollow»,
пожалуйста, ознакомьтесь со статьями нашего справочного центра о пользовательском спаме и
rel=»nofollow».Как метатег nofollow robots сравнивается с атрибутом ссылки rel=»nofollow»?
Поделиться user29671 09 февраля 2015 в 10:17
Похожие вопросы:
Добавьте атрибут nofollow к ссылке, если тег заголовка отсутствует, используя PHP
У меня есть куча текста с html в нем. В основном то, что я хочу сделать, это для всех ссылок, найденных в этом тексте, я хочу добавить rel=noindex к каждой найденной ссылке, только если атрибут…
Добавление атрибута rel=»nofollow», чтобы все ссылки в постах WordPress
Я хочу добавить rel=nofollow ко всем ссылкам в моих постах wordpress, и я хочу иметь список ссылок, которые не получат nofollow. Я много старался, но не могу сделать это правильно, потому что я. ..
..
Добавление rel=nofollow к ссылкам will_paginate в rails
Есть ли какой-нибудь способ добавить rel=nofollow к ссылкам, созданным will_paginate gem в rails?
Как добавить rel=»nofollow» к ссылкам с preg_replace()
Приведенная ниже функция предназначена для применения атрибутов rel=nofollow ко всем внешним ссылкам и никаких внутренних ссылок, если только путь не совпадает с предопределенным корнем URL,…
SEO — noindex, nofollow и канонический тег
Мне нужно кое-что объяснить по поводу моего вопроса. Пример в моем заголовке уже добавлен <meta name=robots content=noindex, nofollow /> Должен ли я снова добавить канонический тег в свой…
Перенаправление исходящих ссылок и атрибут rel=»nofollow»-в чем разница?
Насколько я знаю, многие сайты добавляют атрибут rel=nofollow ко всем исходящим ссылкам внутри сообщений своего форума. Насколько я понимаю, таким образом они говорят поисковым роботам не. ..
..
Noindex, nofollow-достаточно ли поместить их в ответ HTTP?
Я думаю, что название этого вопроса говорит само за себя — при разработке и развертывании бета-версий, должен ли я поставить X-Robots-Tag: noindex, nofollow в ответе HTTP, или <meta name=robots…
PHP регулярное выражение для добавления rel=»nofollow» к внешним ссылкам
Мне нужно добавить rel=nofollow ко всем внешним ссылкам (не ведущим на мой сайт или его поддомены). Я сделал это в два этапа, сначала я добавляю rel=nofollow ко всем ссылкам (даже внутренним…
Установите NOINDEX, NOFOLLOW на конкретные продукты
My magento store имеет следующее, чтобы позволить google / поисковым системам сканировать весь сайт. <meta name=robots content=INDEX,FOLLOW /> Теперь я нуждаюсь в некоторых конкретных…
Как добавить `nofollow, noindex` всех страниц в robots.txt?
Я хочу добавить nofollow и noindex на свой сайт, пока он строится. У клиента есть запрос, чтобы я использовал эти правила. Я знаю о <meta name=robots content=noindex,nofollow> Но у меня есть…
У клиента есть запрос, чтобы я использовал эти правила. Я знаю о <meta name=robots content=noindex,nofollow> Но у меня есть…
| Справочник HTML
Элемент <noindex> (от англ. «no index» ‒ «не индексировать») устанавливает запрет на индексирование текста расположенного внутри данного элемента.
Этот тег работает так же, как и мета-тег <meta name=»robots» content=»noindex»>, но только запрещает индексацию не всей страницы, а только её части.
Примечание: Действие тега распространяется только на текст. Ссылки, а так же такие объекты как видео, аудио, изображения и прочее попав внутрь данного элемента, индексируются, как и прежде.
Совет: Если вам нужно закрыть ссылку для поисковиков, добавьте к ней атрибут rel со значением nofollow:
<a href=»//wm-school.ru» rel=»nofollow»>Ссылка не индексируется</a>
Совет: Элемент <noindex> поддерживается только поисковыми системами Яндекс и Рамблер. Он отсутствует в официальной спецификации HTML, поэтому его наличие приведет к невалидному коду. Браузеры его тоже не поддерживают. Поэтому, если вы беспокоитесь о валидации ваших страниц, то используйте тег <noindex> в виде комментариев.
Он отсутствует в официальной спецификации HTML, поэтому его наличие приведет к невалидному коду. Браузеры его тоже не поддерживают. Поэтому, если вы беспокоитесь о валидации ваших страниц, то используйте тег <noindex> в виде комментариев.
Синтаксис
<noindex> ... </noindex>
<!--noindex--> ... <!--/noindex-->Закрывающий тег
Обязателен.
Атрибуты
Нет.
Стилизация по умолчанию
Нет.
Различия между HTML 4.01 и HTML5
Тег <noindex> отсутствует в официальной спецификации HTML.
Пример использования:
Пример HTML: Попробуй сам<noindex><p>содержимое не индексируется</p></noindex>
<p>Содержимое индексируется</p>
<!--noindex--><p>Содержимое не индексируется</p><!--/noindex-->Поддержка браузерами
| Элемент | ||||||
| <noindex> | Да |
HTML уроки: HTML Элементы
Влияние тега noindex и атрибута «nofollow» на SEO
Здравствуйте, дорогие мои читатели. Сейчас дедушка-сеошник поделится своими мыслями по поводу использования тега <noindex> и атрибута у ссылок rel=nofollow.
Сейчас дедушка-сеошник поделится своими мыслями по поводу использования тега <noindex> и атрибута у ссылок rel=nofollow.
Использование тега <noindex>
Пример использования данного контейнера:
<noindex>
<form id="forma" class="justbox" method="get" action="/results.html" name="forma">
... [содержание формы] ...
</form>
</noindex>
Справочник BookHtml.ru: правильная и валидная запись тега noindex
Я вижу смысл данного тега только для того, чтобы показать поисковому роботу один факт: контент, заключённый в данном теге, необходимо считать не информативным для пользователя. Таким образом, я использую тег <noindex> для форм поиска, форм подбора какой-либо услуги (например, форма бронирования столиков на главной странице сайта). Т.е. в этом теге предпочтительно заключать информацию технической направленности. И чтобы не «захламлять» информационную составляющую своего сайта с точки зрения поисковой машину, и используется данный тег.
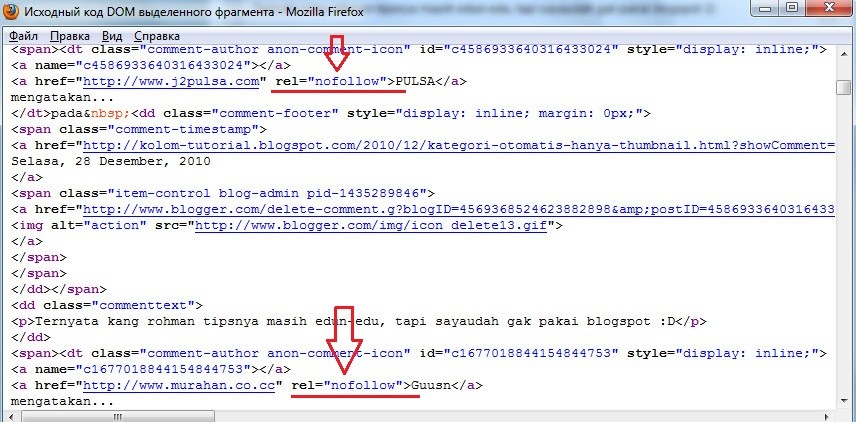
Поисковые системы (Яндекс и Google) замечательно индексируют и контент, и ссылки, которые находятся внутри контейнера <noindex>. Не стоит бояться покупать ссылки с таких сайтов — ведь намного важнее та ссылка, с которой есть реальные живые переходы, а не только сам факт её индексации.
Атрибут «nofollow» для ссылок
Атрибут «rel» со значением «nofollow» принятно использовать для того, чтобы данная ссылка не передавала вес. Удобно проставлять этот параметр по умолчанию со всех исходящих ссылок в темах и комментариях форума или профилей пользователей. Пример использования атрибута «rel» у ссылок:
<a href="url" rel="nofollow">анкор</a>
Справочник BookHtml.ru: правильная и валидная запись тега <a>
Только что было сказано насчёт ссылок в контейнере <noindex>. Абсолютно то же правило относится и к атрибуту «nofollow». Не надо бояться закупать или проставлять ссылки с данным атрибутом — они работают.
За сим разрешите откланяться. Ваш дед-сеошник.
Задавайте вопросы.
Что такое Nofollow
Nofollow — значение HTML-атрибута rel для внешних ссылок. Используется, чтобы поисковые роботы Гугла не учитывали конкретную ссылку и не передавали вес стороннему ресурсу, на которую они ведут. Также может выступать значением метатега «robots».
Использование Nofollow
Основное предназначение этого атрибута — борьба со спамом. Очень часто в рамках черной SEO-оптимизации предпринимаются попытки искусственно нарастить ссылочную массу и увеличить показатели Page Rank за счет размещения ссылок в комментариях, в записях форумов и блогов и т.д. Использование атрибута позволяет исключить придание веса данным ссылкам поисковыми системами.
Применение Nofollow востребовано для:
- малозначимых страниц сайта, появление которых в выдаче вам не нужно — страницы правил пользования и т. д.;
- блока для комментариев. Атрибут может применяться для каждой появляющейся новой ссылки, а в отдельных движках это делается автоматически или полуавтоматически;
- для внешних ссылок, тем самым можно заявить поисковикам, что вы хотите наращивать естественную ссылочную массу;
- ссылок на ресурсы с сомнительной репутацией. Эти линки будут проигнорированы поисковыми роботами, им не будет придаваться «вес».
 д.;
д.;
Синтаксис атрибута:
<a href=»http://www.site.com» rel=»nofollow»>анкор</a>
Как проверить, является ли ссылка Nofollow?
Вот как проверить, является ли ссылка nofollow:
Щелкните правой кнопкой мыши в браузере и выберите «Просмотреть исходный код страницы».
2. Затем найдите ссылку в HTML-коде страницы.
Затем найдите ссылку в HTML-коде страницы.
3.Если вы видите атрибут rel = ”nofollow”, это значит, что ссылка не передает вес. В противном случае ссылка будет dofollow.
Вы также можете использовать расширение Chrome « Strike Out Nofollow Links ».
Этот удобный инструмент автоматически помещает строку через любые ссылки nofollow на странице:
(Таким образом, вам не нужно вручную проверять HTML)
Какие типы ссылок являются Nofollow?
Любая ссылка с тегом nofollow технически является ссылкой nofollow.
Но в целом входящие ссылки из этих источников имеют тенденцию быть nofollow:
- Комментарии блога
- Социальные сети (например, ссылки в сообщениях Facebook)
- Ссылки в сообщениях на форуме или в других формах пользовательского контента
- Определенные блоги и новостные сайты
- Ссылки из « виджетов »
- Ссылки в пресс-релизах
К стати, эти популярные веб-сайты используют тег rel = ”nofollow” во всех своих исходящих ссылках:
- Quora
- YouTube
- Википедия
- Twitch
Что такое noindex, nofollow?
Время чтения: 4 минуты Нет времени читать?
Всем Hello! Сегодня хочу рассказать про теги noindex и атрибут nofollow.
Тег noindex – что такое?
Если говорить коротко, то No index запрещает поисковым роботам индексировать какой-либо элемент на сайте. Данный тег не валидный, поэтому многие html-редакторы не воспринимают его. Например, чтобы редактор WordPress учитывал тег, то необходимо прописать:
Если прописать в таком формате тег не исчезнет. Еще нужно понимать, что тег noindex актуален только для поисковой системы Яндекс. В Google он никак не учитывается.<!—noindex —>
<!—/ noindex —>
Не путайте тег noindex с атрибутом noindex, который прописывает 1 раз в шапке сайта.
<noindex> запрещает индексировать контент внутри этого тега. Что касается meta name=”robots” content=”noindex, nofollow”, он закрывает всю страницу от индексации, но этом я рассказал в данной статье.
Рассмотрим пример noindex:
<noindex>Этот текст не появится в поисковой системе Яндекс</noindex>
Также вложенность не столь важна, и тег может располагаться на в любом месте html кода.
Не забывайте! Если есть открывающий тег <noindex>, то должен быть и закрывающий </noindex), иначе ПС Яндекс не проиндексирует всю информацию.
Оптимизаторы доспускают ошибки, когда заносят все ссылки под noindex. Текст, тобишь анкор учитывается, но сама ссылка и ее вес нет. Для этого используют атрибут nofollow в теге <a>.
Читайте в нашем блоге: Как правильно прописать Title страницы
Зачем нужно использовать noindex?
Давайте разберем в каких случаях стоит применять тег, а в каких это не требуется.
Я использую, когда нужно:
- Спрятать коды древних счетчиков, если вы их еще используете (LiveInternet, Rambler и прочие). Яндекс Метрику и Google Analytics помещать не обязательно;
- Спрятать различные RSS-ленты, подписку на рассылки итд.
Не нужно:
- Закрывать от индексации контекстную рекламу РСЯ, Adsense от поисковых систем Яндекс и Google. При обходе страницы роботы видят рекламу и не учитывают ее;
- Прописывать внешние и внутренние ссылки внутри тега, поисковые системы не будут воспринимать это все равно. Плюс это выглядит глупо, когда есть другой тег который отвечает за ссылки nofollow. Но о нем чуть ниже.
 При обходе страницы роботы видят рекламу и не учитывают ее;
При обходе страницы роботы видят рекламу и не учитывают ее;Каков итог:
Старайтесь по минимуму использовать данный тег, чтобы не было различий между поисковыми системами Яндекс и Google.
Атрибут nofollow тега <а> – Что это такое?
Google представил атрибуты noindex, nofollow
В 2005 году Google представил новый атрибут (названный атрибутом ссылок) Nofollow.
Атрибут nofollow используется при закрытии ссылок от индексации поисковыми роботами Яндекс и Google. Данный атрибут запрещает передавать вес с одного сайта на другой.
В чем отличие от noindex?
Ноиндекс – это тег, который запрещает роботу индексировать текст, нофоллоу – относится к тегу <a> (тег ссылки) запрещает передавать вес по ссылке.
Пример тега nofollow:
<a href=»http://site.ru" rel=»nofollow»>любой анкор</a>
Важно! Не стоит путать его с атрибутом nofollow мета-тега robots. Задача nofollow тега <a> скрыть конкретные ссылки, когда как meta robots content=”nofollow” не учитывает все ссылки на странице, то есть действует на всю страницу.
Узнать что такое атрибут content=”noindex, nofollow” тега meta name robots ?
Использование nofollow
Поисковая система Яндекс с мая 2010 перестал учитывать данный атрибут. Что касается Google то давайте разберем, как правильно использовать nofollow:
- Ненадежный сайт. Если вы ссылаетесь на сайт, но не уверены в его качестве (допустим он окажется спамным) то следует закрыть ссылку nofollow. Тем меньше спамных ссылок на сайте тем лучше;
- Платные ссылки. К данному пункту необходимо отнестись осторожно потому что, Google негативно относится к спамным ссылкам. От одной-двух ссылок ничего не будет, но если у вас таких ссылок, например, 100 штук, стоит об этом задуматься. Поэтому прописать атрибут важно, чтобы не получить санкции со стороны поисковой системы.
 От одной-двух ссылок ничего не будет, но если у вас таких ссылок, например, 100 штук, стоит об этом задуматься. Поэтому прописать атрибут важно, чтобы не получить санкции со стороны поисковой системы.
От одной-двух ссылок ничего не будет, но если у вас таких ссылок, например, 100 штук, стоит об этом задуматься. Поэтому прописать атрибут важно, чтобы не получить санкции со стороны поисковой системы.Одновременное использование nofollow и noindex
Поисковые системы допускают такое сочетание, когда их ставят друг с другом.
Пример
Таким образом, вы закрываете от индексации и анкор (с помощью noindex) и ссылку (с помощью).<noindex><a href=”http://site.ru” rel=”nofollow”>любой анкор</a></noindex>
Читайте в нашем блоге: Как не сделать говносайт
Заключение
Подводя итоги, хочу сказать, что поисковые системы в последнее время меньше стали учитывать данные теги и атрибуты, чем это было к примеру лет 10 назад. Поэтому не заостряйте внимание только на чём-то одном, ведь сейчас выигрывает тот, кто делает все комплексно.
Оставляйте комментарии к статье, если у вас остались вопросы. А я желаю вам удачи и продвижения своих сайтов белыми способами!
что это такое и как использовать
- – Автор: Игорь (Администратор)
В рамках данного обзора, я расскажу вам что такое Nofollow и Noindex, а так же ряд связанных с ними особенностей.
Раньше текст веб-страницы полностью формировался только ее автором. Однако, со временем появилась возможность влиять на содержимое текста обычными читателями. Это комментарии, темы в блогах, посты и тому подобное. Кроме того, сайты стали большими и появилась необходимость в страницах, которые бесполезны для поисковых систем, но нужны пользователям. Это дубликаты страниц, расположенных в разных разделах, автогенерируемые страницы с кусками текста и тому подобное.
Это дубликаты страниц, расположенных в разных разделах, автогенерируемые страницы с кусками текста и тому подобное.
Поэтому появилась необходимость как-то сигнализировать поисковым системам, таким как Яндекс и Google, о том, какой текст необходимо индексировать и какие ссылки учитывать в ссылочной массе. Этими сигналами стали специальные слова Nofollow и Noindex.
Но, обо всем по порядку.
Nofollow, Noindex это
Nofollow — это атрибут, который указывается в определенных ссылках или же мета-теге robots для запрета индексации ссылок и передачи по ним веса.
Noindex — это атрибут, который указывается в мета-теге robots для закрытия текста от индексации. Так же может быть представлен в виде отдельного тега, но учитывается только поисковыми системами Яндекс и Рамблер.
Как используется атрибут nofollow в ссылке:
<a href="/[адрес сайта]" <strong>rel="nofollow"</strong>>Текст</a>
Часть rel=»nofollow» информирует поисковые системы, что поисковым ботам нет необходимости переходить по данной ссылке.
Как используются атрибуты nofollow и noindex в мета-теге robots:
1. Индексировать и переходить по ссылкам в странице
<meta name="robots" <strong>content="index, follow"</strong> />
Если мета-тега в странице нет, то по умолчанию считается, что страницу можно индексировать и поисковому боту необходимо переходить по ссылкам (если они не запрещены атрибутом).
2. Не индексировать текст и переходить по ссылкам в странице
<meta name="robots" <strong>content="noindex, follow"</strong> />
Так же можно не указывать follow, так как поисковики считают по умолчанию, что индексация текста и переход по ссылкам разрешены.
3. Индексировать текст и не переходить по ссылкам в странице
<meta name="robots" <strong>content="index, nofollow"</strong> />
Так же можно не указывать index, так как поисковики считают по умолчанию, что индексация текста и переход по ссылкам разрешены.
4. Не индексировать текст и не переходить по ссылкам в странице
<meta name="robots" <strong>content="noindex, nofollow"</strong> />
5. Не индексировать текст и не переходить по ссылкам в странице с помощью none
<meta name="robots" <strong>content="none"</strong> />
Однако, стоит учитывать, что в мета-теге robots поддерживаются иные вариант специальных директив. Например, noarchive означает не сохранять копию странице в кэше поисковых систем. Поэтому применять none стоит с осторожностью.
Как выглядят тег noindex в поисковых системах Яндекс и Рамблер:
1. <noindex>Неиндексируемый кусок кода</noindex>
2. <!—noindex—>Неиндексируемый кусок кода<!—/noindex—>
Читателю стоит знать, что приоритетным считается второй вариант (в виде html комментария), так как тег из первого варианта корректно воспринимается только поисковыми системами Яндекс и Рамблер (для остальных же это наличие невалидного тега в коде html).
Для чего нужны Nofollow и Noindex?
Для чего применяется Nofollow:
1. Закрытие лишних ссылок.
2. Распределение веса. Открытые ссылки передают больше веса (подробнее об этом чуть далее).
3. Скрытие технических ссылок и передачи веса по ним.
4. Не передавать вес для отдельных сайтов. Например, сомнительные ссылки.
5. Чтобы избежать спама. Площадки с возможностью публиковать открытые ссылки часто становятся объектами для спама.
6. Рекламный контент.
7. Чтобы избежать большого числа внешних открытых ссылок.
8. Приоритет сканирования. Если nofollow ссылки и будут просканированы ботом, то только после открытых.
Для чего применяется Noindex:
1. Данные не статичны, поэтому нет смысла их индексировать.
2. Данные динамически генерируются, поэтому нет смысла индексировать такие страницы. Особенно, если речь о подгрузке данных с помощью ajax.
3. Закрытие информации, которую не хотелось бы, чтобы она отображалась в поиске. Например, личные контактные данные.
Например, личные контактные данные.
4. Технические блоки (в случае тега noindex), такие как счетчики.
5. Дубликаты страниц. Как альтернативу, лучше использовать canonical, но все же.
6. Защита от спама. Обычно применяется к тем разделам, в которых часто публикуют информацию для продвижения иных проектов.
7. Цитаты и копипаст (в случае тега noindex) для увеличения уникальности текста.
8. Яндексу отображать одно, для Google другое (в случае тега noindex).
9. Чтобы текст не оказался в сниппете (в случае тега noindex).
Особенности nofollow и noindex
Вот несколько особенностей использования Nofollow и Noindex:
1. Из-за того, что ажиотаж с использованием ссылок с nofollow порой доходит до абсурда, поисковые системы все же учитывают подобные ссылки, но с меньшим весом. Например, в большинстве социальных сетей, внешние ссылки автоматически закрываются в nofollow, какого бы качества не были сайты акцепторы.
2. Если внутри тега noindex находятся ссылки без nofollow, то они будут учитываться поисковыми системами. Для Яндекса они будут безанкорными, ну а остальные системы и вовсе игнорируют тег noindex. Поэтому, если необходимо так же скрывать ссылки, то в них необходимо задавать nofollow.
Для Яндекса они будут безанкорными, ну а остальные системы и вовсе игнорируют тег noindex. Поэтому, если необходимо так же скрывать ссылки, то в них необходимо задавать nofollow.
3. Поисковые системы Яндекс и Google по разному воспринимают nofollow. Яндекс не учитывает ссылки, но индексирует текст. Google же не только не учитывает ссылку, но и ее текст. Это важная особенность, так как если внутри текста ссылки был адрес сайта, то Яндекс увидит его, а Google нет. Но, как уже говорилось, помните про первую особенность.
4. Учтите, что если в мета-теге robots закрыть только индексацию текста, то ссылки будут учтены.
5. Так же поисковые системы учитывают специальный HTTP заголовок «X-Robots-Tag». Например, «X-Robots-Tag: noindex, nofollow» аналогичен мета-тегу с noindex и nofollow.
6. Если вы используете несколько мета-тегов, то поисковые системы могут по разному их интерпретировать (тем более, что механизмы постоянно корректируются). Поэтому старайтесь задавать необходимое в одном мета-теге.
7. Стоит помнить, что файл «robots.txt» предполагает более высокий приоритет, чем мета-теги. Логика в том, что если страница запрещена в файле, то поисковая система проигнорирует страницу, как и ее мета-теги. Хотя, отмечу, что в интернете порой упоминается, что далеко не всегда страницы, запрещенные к индексации в файле robots, не попадают в индекс. Например, если на страницу была внешняя ссылка.
8. Поисковые системы поддерживают собственный набор мета-тегов и вариаций их представления, более подробно о них лучше смотреть в справке необходимого поисковика. Сделано это для того, чтобы разным поисковым системам можно было указывать разные ограничения.
Теперь, вы знаете что такое nofollow и noindex, а так же некоторые важные особенности.
☕ Хотите выразить благодарность автору? Поделитесь с друзьями!
- Редирект (redirect) что это и зачем он нужен?
- Что такое карта сайта (sitemap)?
Добавить комментарий / отзыв
noindex vs.
 nofollow — Справочный центр Siteimprove
nofollow — Справочный центр SiteimproveМодуль Siteimprove SEO уведомляет пользователей о страницах, исключенных с помощью noindex / nofollow. Эта статья предназначена для объяснения разницы между метатегами noindex и nofollow, когда их использовать и как эти теги влияют на веб-индексирование и страницы результатов поиска (SERP).
Как noindex, так и nofollow являются частью протокола исключения роботов (REP) , стандарта для управления индексированием веб-страниц на вашем сайте.Давайте рассмотрим несколько примеров noindex и nofollow и то, как они контролируют доступ и индексацию вашего веб-сайта Google и другими поисковыми системами.
Что такое noindex и когда его использовать?
Обычно, когда робот Googlebot находит страницу, он читает все ссылки на этой странице, а затем выбирает эти страницы и индексирует их. Это основной процесс, с помощью которого робот Googlebot «сканирует» Интернет. Это полезно, поскольку позволяет Google включать все страницы вашего сайта, если они связаны друг с другом. Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что она не может добавить страницу в свой поисковый индекс, даже если поисковая система может сканировать страницу.
Пример Noindex
статей в разделе «Последние новости» CNN могут появиться только на несколько часов, прежде чем они будут обновлены и перемещены в раздел «Статьи». В этом случае CNN захочет проиндексировать полные статьи, а не раздел последних новостей с короткой частью полной статьи.
Таким образом, вы можете добавить тег noindex к статьям, находящимся в настоящее время в разделе «Последние новости», и удалить этот тег, как только статья больше не будет актуальной.
Чтобы превратить обычные ссылки в ссылки noindex, добавьте «noindex» в HTML-код:
Текст ссылки
Что такое nofollow и когда его использовать?
Nofollow — это атрибут HTML, который предписывает большинству поисковых систем воздерживаться от перехода по ссылке и тем самым передавать значение на страницу, на которую ведет ссылка. Некоторые эксперты по SEO интерпретируют это как способ сообщить поисковым системам, что вы не доверяете или не можете поручиться за содержание ссылки, на которую ведет ссылка. Короче говоря, если вы хотите, чтобы поисковая машина проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице; добавьте на свою страницу тег nofollow.
Некоторые эксперты по SEO интерпретируют это как способ сообщить поисковым системам, что вы не доверяете или не можете поручиться за содержание ссылки, на которую ведет ссылка. Короче говоря, если вы хотите, чтобы поисковая машина проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице; добавьте на свою страницу тег nofollow.
Чтобы превратить обычные ссылки в ссылки nofollow, добавьте «nofollow» в HTML-код *:
Текст ссылки
* Вы можете добавить код вручную, но многие CMS автоматически вставляют его при необходимости.Обратитесь к своему веб-мастеру за советом.
Nofollow, пример
Когда пользователи ищут в Google фразы, связанные с новостями, CNN хочет, чтобы разделы их статей (со статьями) занимали первые места в поисковой выдаче, потому что статьи являются наиболее ценным активом CNN.
Не имеет смысла располагать их раздел авторизации вверху.
Таким образом, чтобы сообщить Google, что статьи важнее входа в систему, CNN добавит тег nofollow к своей ссылке для входа.
Примечание. Сканер Siteimprove не учитывает «noindex» или «nofollow» при определении содержания для сканирования.Сканируем на основе настроек сканирования.
Какие страницы на вашем сайте использовать noindex или nofollow? • Yoast
Мишель ХеймансМихиэль был одним из наших первых сотрудников и раньше был партнером Yoast. Начните оптимизацию своего сайта с его статей!
Некоторые страницы вашего сайта служат определенной цели, но не для ранжирования в поисковых системах и даже не для привлечения трафика на ваш сайт.Эти страницы должны быть там, как клей для других страниц или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте. Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Однако, если вы новичок в этих условиях, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Что такое noindex nofollow?
noindex означает, что веб-страница не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поиска. nofollow означает, что пауки поисковых систем не должны переходить по ссылкам на этой странице. Вы можете добавить эти значения в свой метатег robots. Мета-тег robots — это фрагмент кода в разделе заголовка веб-страницы. Он сообщает поисковым системам, как сканировать и индексировать ли страницу.
Наше полное руководство по метатегам robots — отличное чтение, если вы хотите немного глубже погрузиться в эту тему.
Вкратце:
- Метатег robots в большинстве случаев выглядит следующим образом:
- VALUE1 и VALUE2 установлены на индекс
, по умолчанию используется, что означает данная страница может быть проиндексирована поисковыми системами, и по ссылкам на этой странице можно переходить для сканирования страниц, на которые они ссылаются. - VALUE1 и VALUE2 могут быть установлены на
noindex, nofollowили другую комбинацию, например индекс, nofollow.

Но пусть вас не пугает этот код. Yoast SEO поможет вам! Если вы хотите узнать, как noindex пост в WordPress супер-простым способом, вы должны прочитать этот пост: Как noindexing пост в WordPress: простой способ.
Но когда какое значение использовать?
Страниц для установки noindex
Авторский архив в блоге одного автора
Если вы единственный, кто пишет для своего блога, страницы ваших авторов, вероятно, на 90% совпадают с домашней страницей вашего блога.Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете noindex его. К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как нельзя индексировать архив автора.
К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как нельзя индексировать архив автора.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения, который вы не хотите индексировать.Например, в Yoast мы используем настраиваемые страницы для наших продуктов, поскольку мы не являемся типичным интернет-магазином, продающим физические продукты. Таким образом, нам не нужно изображение продукта, фильтры, такие как размеры и технические характеристики, на вкладке рядом с описанием. Поэтому мы не индексируем обычные страницы продуктов, которые выводит WooCommerce, и используем наши собственные страницы. Действительно, мы noindex тип сообщения продукта.
Соответственно, мы видели решения для электронной коммерции, которые также добавляли такие характеристики, как размеры и вес, в качестве настраиваемого типа сообщений.Эти страницы считаются некачественным контентом. Вы поймете, что эти страницы не нужны ни посетителям, ни Google, поэтому их тоже нужно держать подальше от страниц результатов поиска.
Страницы благодарности
Эта страница не служит никакой другой цели, кроме как поблагодарить вашего клиента / подписчика на новостную рассылку / впервые комментирующего. Эти страницы, как правило, представляют собой страницы с тонким контентом, с возможностью дополнительных продаж и социальных сетей, но они не представляют ценности для тех, кто использует Google для поиска полезной информации. Следовательно, этих страниц не должно быть на страницах результатов поиска.
Страницы администратора и входа в систему
Большинство страниц входа не должны находиться в Google. Но это так. Уберите свой индекс из индекса, добавив к нему noindex . Исключением являются страницы входа, которые обслуживают сообщество, например Dropbox или аналогичные службы. Просто спросите себя, стали бы вы гуглить одну из своих страниц входа в систему, если бы вы не работали в своей компании. Если нет, то можно с уверенностью сказать, что Google не нужно индексировать эти страницы входа. К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS автоматически не индексирует страницу входа на ваш сайт.
К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS автоматически не индексирует страницу входа на ваш сайт.
Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, вы ссылаетесь на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Таким образом, необходимо переходить по всем ссылкам, а мета-настройка роботов должна быть:
Yoast SEO следит за тем, чтобы для ваших внутренних поисковых страниц по умолчанию было установлено значение noindex.Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.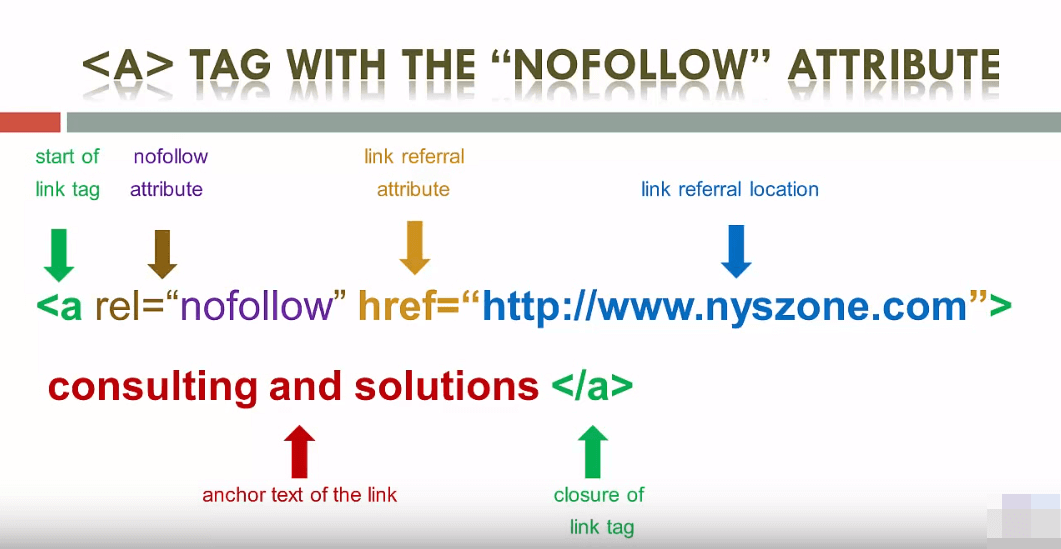
Только для разработчиков: если вы действительно хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Страниц для установки на nofollow
Для всех примеров, упомянутых выше, нет необходимости nofollow все ссылки на этих страницах.Вы не хотите отображать их в результатах поиска, но хотите, чтобы Google переходил по ссылкам на странице. Теперь, когда следует добавить nofollow в метатег роботов?
Если вы установите для страницы значение nofollow с метатегом robots, ни одна из ссылок на этой странице не будет переходить. Google придумал nofollow, чтобы иметь возможность различать ссылки на ненадежный контент (или, позже, оплаченный, например, рекламу). На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по любой ссылке .
Пример: если у вас есть страница со списком книг по SEO с избытком партнерских ссылок Amazon, они могут быть полезны для вашего сайта для ваших пользователей. Но я бы дал
Но я бы дал nofollow всю страницу, если на странице нет ничего важного. Однако вы могли бы проиндексировать его. Просто убедитесь, что вы правильно скрываете свои ссылки.
Одинарные ссылки Nofollow
Если у вас есть сообщение или страница с несколькими ссылками, вы можете помочь поисковым системам квалифицировать их.В настоящее время вы можете nofollow для одной ссылки или даже установить для нее спонсируемый или пользовательский контент. Добавление правильных атрибутов rel к вашей ссылке позволяет вам это сделать. Например, ссылка на рекламу будет выглядеть так: пример ссылки . С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
Заключение
Как мы уже видели, будет ли noindex страница или nofollow ссылка сводиться к двум вопросам: хотите ли вы, чтобы эта страница отображалась на страницах результатов поиска и , если поисковые системы переходят по ссылкам на эта страница? Например, для страниц с благодарностями или страниц входа в систему ответ на первый вопрос — «нет». Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
PS. Вы noindex пост или страницу, хотя вы этого не хотели? Не беспокойтесь, вы легко можете исправить случайную ошибку noindex !
Подробнее: Как не индексировать пост »
seo — это хорошая идея использовать имя в этой ситуации?
nofollow
nofollow означает, что бот не должен переходить по этой ссылке.Если вас беспокоит только Google (как предполагает ваш тег), это, вероятно, поможет:
Как Google обрабатывает nofollow-ссылки?
В общем, мы им не следуем. Это означает, что Google не передавать PageRank или якорный текст по этим ссылкам. По сути, использование nofollow приводит к тому, что мы отбрасываем целевые ссылки из нашего общего граф сети.
 Однако целевые страницы могут по-прежнему отображаться в нашем
index, если другие сайты ссылаются на них без использования nofollow, или если
URL-адреса отправляются в Google в файле Sitemap.Также важно
обратите внимание, что другие поисковые системы могут немного обрабатывать nofollow
различные пути.
[Источник]
Однако целевые страницы могут по-прежнему отображаться в нашем
index, если другие сайты ссылаются на них без использования nofollow, или если
URL-адреса отправляются в Google в файле Sitemap.Также важно
обратите внимание, что другие поисковые системы могут немного обрабатывать nofollow
различные пути.
[Источник]Однако добавление этого атрибута ни в коем случае не является жестким ограничением, стандарта нет, и некоторые боты могут его вообще игнорировать. Кроме того, поисковые системы могут по-прежнему помечать страницу как сайт для построения ссылок в зависимости от соотношения содержания / ссылки.
noindex
noindex не используется в ссылках Google (про другие не знаю).Он предназначен для атрибута robots в заголовке html и применяется ко всей странице. Так что это, скорее всего, бесполезно для вас. Пример:
линкбилдинг
200 ссылок, однако, тоже не очень удобны для пользователя. Вам следует серьезно подумать о сокращении количества ссылок, (например) выбрав те, которые имеют схожую тему.
Пока вы это читаете, смотрите направо, да, здесь, на Stack Overflow, есть «Коробка» под названием Related .Вот как вы это делаете. Представьте, что они помещают туда каждой отдельной темы, когда-либо созданной … Не очень полезно.
Также, если вы сделаете это с некоторой логикой, как я предложил выше, а не просто случайным образом выбирая N ссылок из списка, вы, вероятно, можете удалить nofollow , так как ссылки станут полезными, а Google любит полезные ссылки.
Затем вы также можете добавить «прожектор» для сайтов с низким трафиком (хотя им, вероятно, понадобится nofollow).
Страницы веб-роботов
О теге
роботовВ двух словах
Вы можете использовать специальный тег HTML, чтобы запретить роботам индексировать
содержимое страницы и / или не сканировать его на предмет наличия ссылок.
Например:
...
При использовании тега robots необходимо учитывать два важных момента:
- роботы могут игнорировать ваш тег. Особенно вредоносные роботы, сканирующие Интернет на наличие уязвимостей безопасности и сборщики адресов электронной почты, используемые спамерами. не обращаю внимания.
- директива NOFOLLOW применяется только к ссылкам на этой странице.Это вполне вероятно, что робот найдет такие же ссылки на других страница без NOFOLLOW (возможно, на каком-то другом сайте), и так далее попадает на вашу нежелательную страницу.
Не путайте это NOFOLLOW с rel = «nofollow» атрибут ссылки.
Детали
Как и /robots.txt, robots META тег является стандартом де-факто. Он возник в результате встречи «птиц пера» в 1996 году. распределенный семинар по индексации, который был описан в заметках о совещании
Тег META также описан в HTML
Спецификация 4. 01, Приложение B.4.1.
01, Приложение B.4.1.
Остальная часть этой страницы дает обзор того, как использовать роботов. Теги на ваших страницах с некоторыми простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как написать метатег для роботов
Куда девать
Как и любой тег, он должен быть помещен в раздел HEAD HTML-кода. page, как в примере выше. Вы должны поместить его на каждую страницу своего сайт, потому что робот может найти глубокую ссылку на любой страницу на вашем сайте.
Что в него положить
Атрибут «ИМЯ» должен быть «РОБОТЫ».
Допустимые значения для атрибута «CONTENT»: «ИНДЕКС», «НОИНДЕКС», «СЛЕДУЮЩИЕ», «НЕ СЛЕДУЕТ». Допускается несколько значений, разделенных запятыми, но очевидно, только некоторые комбинации имеют смысл. Если нет тег роботов, по умолчанию — «INDEX, FOLLOW», так что нет необходимости объяснять это. Остается:
Прочтите, когда и как использовать Noindex, Nofollow, Canonical и Disallow
Сложно ли вам решить, как и когда использовать теги, атрибуты и команды, такие как Noindex, Nofollow, Canonical или Disallow?
Мы убедили Хенрика Бондтофте (датского мастера поисковой оптимизации) выступить в роли вашего судьи.
Nofollow
Nofollow был разработан совместно Yahoo, MSN и Bing в 2005 году. Его цель заключалась в том, чтобы подавить растущую проблему спама в комментариях.
Nofollow — это атрибут HTML, который предписывает большинству поисковых систем воздерживаться от перехода по ссылке и тем самым передавать ценность сайту, на который ведет ссылка.
Ссылка nofollow не гарантирует, что целевой сайт не будет сканироваться автоматически. На самом деле у Google есть бот, предназначенный исключительно для этой цели.
Тег, однако, сообщает поисковой системе, что вы не доверяете или не можете поручиться за содержание веб-сайта, на который ведет ссылка.
Вот почему довольно глупо использовать nofollow для внутренних целей на вашем собственном сайте. Это странный сигнал для поисковых систем — что на вашем сайте есть контент, за который вы не можете поручиться. Так что, пожалуйста, не делай этого.
Nofollow можно вставить, добавив rel = ”nofollow” в активную ссылку. В большинстве CMS / систем управления контентом вы можете установить его в редакторе WYSIWYG при вставке активной ссылки.
Nofollow также можно реализовать с помощью метатега.Вы можете увидеть пример ниже.
Фактически это была исходная форма Nofollow, но поскольку она затемняла всю страницу, она оказалась менее адаптируемой и полезной, чем атрибут, который мог бы добавляться к ссылкам индивидуально.
Disallow: (Robots.txt)
Robots.txt — это привратник вашего веб-сайта.
Он находится в корне вашего веб-сайта, и его директивы важнее всех остальных.
Вы должны использовать Disallow, если на вашем веб-сайте есть целые папки, которые необходимо отключить.И особенно если они раньше не индексировались.
Создавая Disallow в файле robots.txt, вы сообщаете поисковым системам, что они не должны сканировать соответствующую страницу или папку.
Вы можете заблокировать даже весь свой сайт, но это не означает, что страница не будет проиндексирована.
Если ваша страница продолжает отображаться в индексе Google, вы можете использовать Инструменты Google для веб-мастеров, чтобы запросить ее повторное удаление. Если, конечно, вы настаиваете на использовании robots.txt для этой цели.
Если вы объедините и Disallow, и Noindex, последний будет проигнорирован, потому что ваша команда Disallow уже сообщила поисковым системам, что они могут не просматривать страницу.
Вот почему использование этих двух тегов вместе излишне. Если вы хотите быть абсолютно уверены, что ваш URL-адрес не индексируется поисковыми системами, используйте Noindex и ничего больше.
Использование Disallow на уже проиндексированных страницах, например, с входящими ссылками, означает, что вы теряете ценность, которая иначе была бы передана другим страницам вашего сайта.
Вот почему я настоятельно рекомендую вам по возможности использовать Noindex.
Если вы размещаете внутренние ссылки на страницы, которые запрещены в вашем файле robots.txt вы тратите свой внутренний рейтинг страницы.
Примеры запрещающих команд
Disallow: / folder-we-dont-want-to-show / Запретить: /file-we-dont-want-to-show.html Разрешить: /folder-we-dont-want-to-show/single-file-we-want-to-show-from-folder.html
(Разрешить поддерживается Google, но не всеми поисковыми системами)
Noindex
Тег Noindex сообщает поисковым системам, что соответствующая страница не должна индексироваться в их результатах поиска.
Если вы не добавили Nofollow к тегу, поисковые системы все равно будут переходить по всем ссылкам на странице.
Другими словами, страница будет прочитана поисковыми системами, но не будет проиндексирована.
Если вы не хотите, чтобы поисковые системы переходили по ссылкам на вашей странице, вам нужно добавить в команду Nofollow.
Не индексировать, а переходить по ссылкам .
Не индексировать и не переходить по ссылкам.
Преимущество отказа от использования Nofollow с Noindex состоит в том, что Pagerank может проходить через Noindex и переходить к страницам, на которые есть ссылки.Этого не может произойти при сочетании с атрибутом Nofollow.
Канонический тегКанонический тег используется для обозначения первой страницы, когда у вас есть несколько страниц с повторяющимся содержанием.
Если у вас пять версий одной и той же страницы, то четыре из них должны быть помечены каноническим тегом, указывающим на основную страницу. Таким образом, поисковые системы могут видеть, что это правильный URL.
Канонические теги — это всего лишь рекомендация. Вот почему нередко можно найти в индексе страницы с каноническим тегом.Это также причина того, что вы, вероятно, немного потеряете свой рейтинг страницы, если будете использовать канонические теги вместо Noindex.
Примеры канонических тегов
Приведенный выше фрагмент кода необходимо вставить в заголовок страницы
Резюме
В заключение я ранжирую эти четыре метода в следующем порядке:
- Тег Noindex, без атрибута Nofollow
- Канонический тег
- Роботы.txt disallow command. Если только папки не нужно экранировать целиком, в этом случае я рекомендую robots.txt выше Canonical или Noindex.
- Nofollow — На самом деле, я вообще не рекомендую вам использовать этот последний.
Пожалуйста, помогите нам убедить Хенрика написать больше статей для DashboardJunkie.com
Если вам нравится это руководство, нажмите кнопки ниже или оставьте комментарий.
Помогите себе и своей сети прямо сейчас!
Хенрик Бондтофте руководит успешной датской компанией онлайн-маркетинга Bondtofte. dk, интернет-магазине спортивного снаряжения Wolfgear.dk и написала одну из самых популярных датских книг о SEO.
dk, интернет-магазине спортивного снаряжения Wolfgear.dk и написала одну из самых популярных датских книг о SEO.
Получайте уведомления о новых статьях!
Да, пожалуйста, сообщите мне
Noindex vs Nofollow vs Disallow Commands
29 марта 2019 г.
Части следующего адаптированы из моей книги Техническое руководство по SEO , теперь доступно на Amazon.
Часто возникает путаница относительно разницы между командами noindex, nofollow и disallow.Все три являются мощными инструментами, которые можно использовать для повышения эффективности обычного поиска на веб-сайте, но каждый имеет уникальные ситуации, в которых они могут применяться. К сожалению, во многих случаях они применяются неправильно, что значительно снижает эффективность поиска на сайте.
Чтобы понять, что делают команды noindex, nofollow и disallow, давайте сделаем шаг назад и рассмотрим, что делают роботы поисковых систем. Поисковые системы рассылают роботов, чтобы они сканировали и понимали сайт.Эти роботы сложны, но выполняют две основные операции.
- Сканирование : как только робот обнаруживает веб-сайт, он просматривает все страницы и файлы на веб-сайте, которые может найти. Можно установить ограничения для файлов и страниц, которые может видеть робот, и внести другие изменения, чтобы робот находил все, что ему нужно.
- Индексирование : после сканирования роботы берут всю информацию, собранную во время этого сканирования, чтобы решить, какая информация, содержащаяся на конкретной странице, может и должна отображаться в результатах поиска.В рамках этого роботы поисковых систем также будут решать, в какие результаты поиска следует включить страницы веб-сайта (если таковые имеются) и где страница должна занимать место в этих результатах.

Disallow против Noindex против Nofollow
Disallow: Controlling CrawlingПервый метод управления поисковым роботом — это команда disallow. Это указано в файле robots.txt. Файл robots.txt — это простой текстовый файл, размещенный в корневом каталоге вашего веб-сайта.Он предоставляет роботам директивы, сообщающие им, какие каталоги вы бы предпочли, чтобы они не сканировали.
Если указано, поисковый робот, который соблюдает эту команду, не будет сканировать страницу, файл или каталог, которые были запрещены. Например, вы можете указать это в файле robots.txt, чтобы запретить поисковому роботу сканировать все, что находится в / a-secret-directory.
Disallow: / a-secret-directory
Вы также можете указать запрет только для определенного робота.Например, эта запись в файле robots.txt указывает ботам Google избегать каталога my-content-admin-area. Однако боты Bing все еще могли сканировать этот каталог.
user-agent: googlebot
Disallow: / my-content-admin-area /
Запрещенные файлы могут по-прежнему индексироваться и отображаться в результатах поиска. Например, Google и Bing могут найти ссылку на запрещенную страницу на вашем веб-сайте или в другом месте в Интернете. Они не могли сканировать страницу, чтобы увидеть ее содержимое, но они знали бы, что страница существует, и могли бы показать ее в индексе Google.
Как правило, лучше ничего не запрещать. Один набор файлов, который вы никогда не должны запрещать, — это файлы JavaScript, CSS или изображения. Эти файлы управляют внешним видом страницы, и Google полагается на эти факторы дизайна при оценке страницы, особенно при определении удобства для мобильных устройств.
Meta Robots Nofollow: Controlling Crawling Далее у нас есть команда nofollow. На самом деле существует два разных оператора nofollow. Команда nofollow, управляющая сканированием, — это мета-робот nofollow. Этот nofollow применяется на уровне страницы путем указания nofollow в метатеге robots в теге
Этот nofollow применяется на уровне страницы путем указания nofollow в метатеге robots в теге
...
...
При размещении в
веб-страницы мета-nofollow предписывает роботу поисковой системы не сканировать никакие ссылки на странице. Это часть большого набора директив, которые вы можете указать в метатеге robots.Роботы, соблюдающие эту директиву, смогут сканировать эту страницу, но не будут сканировать страницы, на которые есть ссылки с этой страницы. Если вы не хотите, чтобы роботы вообще сканировали страницу, не говоря уже о ссылках, содержащихся на этой странице, то запрет robots.txt — лучший метод управления сканированием.
Rel Nofollow: объяснение природы ссылки Другой вариант nofollow — это команда rel = ”nofollow”. Это может повлиять на сканирование, но более важная цель состоит в том, чтобы объяснить, почему эта ссылка включена. Традиционно rel = ”nofollow” использовался для указания любых ссылок, которые были спонсируемыми или имели денежные отношения. С тех пор Google ввел другие типы квалификаторов: rel = «sponsored» и rel = «ugc». Квалификатор rel = «sponsored» предназначен для любой платной ссылки, rel = «ugc» — для любой ссылки, содержащейся в пользовательском контенте, а rel = «nofollow» — для любой другой ссылки, с которой вы бы предпочли, чтобы роботы Google не связывали Ваш сайт.
Традиционно rel = ”nofollow” использовался для указания любых ссылок, которые были спонсируемыми или имели денежные отношения. С тех пор Google ввел другие типы квалификаторов: rel = «sponsored» и rel = «ugc». Квалификатор rel = «sponsored» предназначен для любой платной ссылки, rel = «ugc» — для любой ссылки, содержащейся в пользовательском контенте, а rel = «nofollow» — для любой другой ссылки, с которой вы бы предпочли, чтобы роботы Google не связывали Ваш сайт.
Эти команды rel указываются на уровне ссылки с атрибутом rel, добавленным к определенному тегу .Например, эта ссылка будет nofollowed, и эта ссылка на страницу / no-robots-here не будет связана с вашим веб-сайтом.
Noindex: управление индексированием
Команда «noindex» может быть указана на странице в мета-роботах тег. Если на страницу включен метатег noindex, поисковым роботам разрешено сканировать страницу, но им не рекомендуется индексировать страницу (это означает, что страница не будет включена в результаты поиска, если эта команда будет соблюдена).
Пример:
Пара примечаний:
- Раньше вы могли указать noindex в файле robots.txt. Однако это больше не поддерживается Google (и, вероятно, никогда не было). При этом официальном отсутствии поддержки единственный способ указать noindex — на уровне страницы.
- Если вы не можете добавить метатег к странице, вы также можете использовать X-Robots в заголовке HTTP. Это может быть полезно для запрета индексации содержимого, отличного от HTML, например PDF-файлов или некоторых изображений.
Важно четко понимать, как команды Disallow и Noindex работают вместе. Эти команды можно объединить тремя способами, чтобы повлиять на индексирование и сканирование.
| Disallow | Noindex | ||
| Сценарий 1 | X | ||
| X | |||
| X | X | |
В сценарии 1 страница с параметром noindex не будет включена в результат поиска. Однако робот все еще может сканировать страницу, то есть роботы могут получать доступ к содержанию на странице и переходить по ссылкам на странице.
Однако робот все еще может сканировать страницу, то есть роботы могут получать доступ к содержанию на странице и переходить по ссылкам на странице.
В сценарии 2 страница не будет сканироваться, но может быть проиндексирована и появится в результатах поиска. Поскольку робот не сканировал страницу, робот ничего об этом не знает. Любой контент, включенный в эту страницу в результаты поиска, будет собираться из других источников, например, из ссылок на страницу.
Сценарий 3 будет работать точно так же, как Сценарий 2, если в метатеге robots был указан noindex.Это связано с тем, что при указании Disallow робот не будет сканировать страницу. Если робот не сканирует страницу, он не увидит метатег, указывающий на то, что страницу не индексировать. Если для страницы необходимо установить значение noindex и запретить, сначала установите noindex, а затем, после удаления страницы из поискового индекса, установите запрет.
Рекомендации по использованию Nofollow Когда использовать Nofollow для управления сканированием? Как правило, роботу нужно сообщить, что он может переходить по всем ссылкам на странице. Если слишком агрессивно указывать, по каким ссылкам следовать или nofollow, может начаться впечатление, что веб-сайт пытается манипулировать восприятием веб-сайта роботом. Это практика, известная как формирование страницы, где команды nofollow используются для моделирования того, как сигналы с одной страницы передаются на другую. В лучшем случае эти попытки манипулировать роботом больше не работают. В худшем случае попытки манипулировать роботами с помощью rel nofollow могут привести к штрафу.
Если слишком агрессивно указывать, по каким ссылкам следовать или nofollow, может начаться впечатление, что веб-сайт пытается манипулировать восприятием веб-сайта роботом. Это практика, известная как формирование страницы, где команды nofollow используются для моделирования того, как сигналы с одной страницы передаются на другую. В лучшем случае эти попытки манипулировать роботом больше не работают. В худшем случае попытки манипулировать роботами с помощью rel nofollow могут привести к штрафу.
Когда использовать квалификаторы Rel в ссылках
Rel = ”nofollow”, rel = ”sponsored” или rel = ”ugc” следует использовать в конкретных случаях, когда необходимо четко указать характер ссылки.Ярким примером являются ссылки на странице, на которой был произведен платеж в обмен на ссылку. Например, если сообщение в блоге содержит ссылки на рекламу, эти ссылки должны иметь атрибут rel nofollow. Однако с помощью дополнительных квалификаторов Google дает понять, что любые пользовательские ссылки должны иметь этот квалификатор.
Disallow, Noindex или Nofollow не являются обязательными
Disallow, Noindex и Nofollow не являются обязательными — роботам не нужно выполнять ни одну из этих команд. На самом деле слово «команда» — это немного преувеличение.Эти директивы являются рекомендациями. Боты Google могут игнорировать любую из этих рекомендаций. Часто игнорирование этих команд является признаком более серьезной проблемы, связанной с тем, что роботы неправильно понимают, как сканировать ваш сайт. В таких ситуациях вы хотите исследовать, в чем заключается эта более серьезная проблема, и решить ее, вместо того, чтобы просто переоснащать свои команды noindex, disallow или nofollow.
Кроме того, поскольку эти команды являются необязательными, вы не хотите полагаться на них для каких-либо важных аспектов своего веб-сайта.Если часть веб-сайта не должна быть общедоступной или если вы хотите, чтобы часть вашего веб-сайта не попала в результаты поиска Google, вам следует рассмотреть альтернативы. Обычной областью, где это становится проблемой, являются промежуточные веб-сайты, которые вы явно не хотите, чтобы роботы Google сканировали, и определенно не хотите индексировать их. На промежуточном веб-сайте запрета запрета или noindex недостаточно для гарантии того, что боты покинут сайт. Вместо этого вы захотите потребовать логин для доступа к этому промежуточному сайту.Вход в систему не является обязательным и не может быть проигнорирован, что означает, что боты не смогут его сканировать или индексировать.
Обычной областью, где это становится проблемой, являются промежуточные веб-сайты, которые вы явно не хотите, чтобы роботы Google сканировали, и определенно не хотите индексировать их. На промежуточном веб-сайте запрета запрета или noindex недостаточно для гарантии того, что боты покинут сайт. Вместо этого вы захотите потребовать логин для доступа к этому промежуточному сайту.Вход в систему не является обязательным и не может быть проигнорирован, что означает, что боты не смогут его сканировать или индексировать.
Самое важное, что нужно запомнить, — это две операции: сканирование и индексация. Мы можем контролировать или влиять на оба из них, используя разные директивы.
В итоге эти директивы таковы:
- Disallow запрещает роботу сканировать страницу, файл или каталог.
- Noindex говорит роботу не индексировать страницу.
- Meta nofollow говорит роботу не переходить по определенной ссылке или всем ссылкам на странице.
- Rel = «nofollow» (или rel = «sponsored» или rel = «ugc») дополнительно уточняет природу ссылки

Используйте квалификаторы Disallow, Noindex, Meta Nofollow и rel умеренно и только после тщательного рассмотрения всех возможных последствий как их использование повлияет на эффективность SEO вашего сайта. При их использовании убедитесь, что вы не блокируете доступ роботов к важным частям вашего веб-сайта, таким как JavaScript, CSS или файлы изображений.В случае сомнений не добавляйте никаких директив.
Тестирование команд роботаЕсли вы решили использовать команды робота, вы хотите протестировать их, чтобы убедиться, что роботы правильно понимают команды. Хотя вы можете использовать инструменты сканирования, чтобы помочь в этом, более простой метод тестирования — в Google Search Console.
Тестирование Robots.txt
В консоли поиска Google вы можете проверить текущий файл robots.txt, чтобы узнать, какие страницы, если таковые имеются, в настоящее время указаны как страницы, к которым Google не должен получать доступ. В настоящее время он недоступен в области навигации в Google Search Console, но доступен как устаревший инструмент (доступ прямо здесь).
В настоящее время он недоступен в области навигации в Google Search Console, но доступен как устаревший инструмент (доступ прямо здесь).
На этой странице вы увидите текущий файл robots.txt вашего сайта. Под файлом robots.txt вы можете ввести URL-адреса со своего веб-сайта и проверить, не сможет ли Google сканировать эту страницу из-за файла robots.txt. В этом примере каталог wp-admin заблокирован для сканирования, но все остальные URL-адреса должны быть разрешены для сканирования.
Проверка возможности сканирования и индексирования
Другой метод проверки того, могут ли роботы сканировать или индексировать страницу в Google Search Console, заключается в использовании инспектора URL.В новой консоли поиска Google введите URL-адрес, который вы хотите протестировать.
После загрузки результатов в отчете о покрытии вы можете увидеть, разрешены ли сканирование и индексирование. В этом примере разрешены оба варианта — это предполагаемый ответ. Если, однако, я указал noindex или disallow для этой страницы, сканирование или проиндексированные разрешенные ответы должны быть отрицательными.
Если, однако, я указал noindex или disallow для этой страницы, сканирование или проиндексированные разрешенные ответы должны быть отрицательными.
Если вам нужна помощь, давайте поговорим, прежде чем вносить какие-либо изменения.Или для получения дополнительной информации о noindex, nofollow, disallow и других технических вопросах SEO, пожалуйста, обратитесь к Техническому руководству по SEO в мягкой обложке или Kindle на Amazon. Теперь доступно за всего за 9,99 $ !
РесурсыРазница между метатегами Noindex и Nofollow
Слышал про index, noindex, follow, nofollow… .и интересно, о чем, черт возьми, люди говорят? Прочтите это руководство, чтобы узнать больше!
NOINDEX
Директива noindex — это часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не включать эту конкретную страницу в свой список результатов поиска.
По умолчанию веб-страница настроена на «индексирование». Вы должны добавить директиву на веб-страницу в разделе
Какие примеры страниц следует установить на «noindex»?
- Страницы с благодарностью. Если вы включаете на свой веб-сайт формы для сбора потенциальных клиентов, такие как «Связаться с нами» или «Назначить встречу», вы, вероятно, направите пользователей из своих веб-форм на уникальные страницы с благодарностью после того, как пользователь отправит форму.Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как он заполнит вашу веб-форму. Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
- страниц только для участников. Если у вас есть раздел вашего веб-сайта, посвященный вашим сотрудникам или членам организации, но вы не хотите, чтобы эти веб-страницы были доступны широкой публике или поисковым системам, директива noindex поможет защитить эти страницы от быть найденным в поисковой выдаче.
 Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.NOFOLLOW
Директива nofollow — это часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не передавать равенство ссылок через любые ссылки на данной веб-странице.
Ссылки — важная часть поисковой оптимизации, хотя эксперты все время спорят о том, какую роль ссылки играют в общем рейтинге. Мы знаем, что ссылки с внешних авторитетных веб-сайтов помогут укрепить доверие к нашему собственному веб-сайту и повысить его рейтинг. Внутренние ссылки тоже полезны! Они помогают пользователям и роботу Google перемещаться по вашему веб-сайту и объединять важные идеи.
Внутренние ссылки тоже полезны! Они помогают пользователям и роботу Google перемещаться по вашему веб-сайту и объединять важные идеи.
По умолчанию ссылки настроены на «подписку». Вы можете установить ссылку на «nofollow» следующим образом: Anchor Text , если вы хотите предложить Google что гиперссылка не должна передавать ссылочной стоимости / ценности SEO целевой ссылке.
Какие примеры ссылок следует установить на «nofollow»?
- Ссылки в комментариях блога — Если вы потратили время на то, чтобы написать ценный пост для своего веб-сайта, вы не хотите, чтобы конкурент или спамер по ссылкам мог добавить бесполезный комментарий к вашему сообщению в блоге со ссылкой на свой собственный. веб-сайт, на котором написано что-то вроде «Отличный блог.Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
- платных ссылок. Еще одна тактика SEO, которая приобрела популярность в SEO-сообществе blackhat, — это массовая покупка ссылок в Интернете.Владельцы веб-сайтов со страницей спонсоров на своем сайте могут выбрать включение логотипов и ссылок на свои веб-сайты спонсоров мероприятия, но использовать метатег «nofollow» для каждой ссылки на странице спонсора, чтобы указать Google, что они не могут поручиться за каждую. веб-сайт организации, на который делается ссылка. Имейте в виду, что, хотя ссылки «nofollow» не предназначены для повышения SEO связанного контента, они по-прежнему ценны для взаимодействия с пользователем и привлечения трафика.
 Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.ЗАКЛЮЧЕНИЕ
Надеюсь, это руководство дало вам лучшее понимание noindex vs.nofollow и когда каждый из них может быть полезен. Напоминаем:
Напоминаем:
- «noindex» предлагает поисковым системам (в первую очередь Google) не индексировать определенную веб-страницу.
- «nofollow» предлагает поисковым системам (в первую очередь Google) не передавать ссылочную массу через ссылки на веб-странице.
Обязательно проконсультируйтесь с квалифицированным агентством цифрового маркетинга при применении директив noindex и nofollow к своему веб-сайту. Если все сделано неправильно, эти маленькие теги могут нанести большой ущерб вашему органическому трафику.
Познакомьтесь с Кэти Хельгесен
Кэти Хельгесен, директор по SEO в Launch Digital Marketing, имеет более чем 15-летний опыт работы в области цифрового маркетинга, SEO и аналитики. Она любит кататься на американских горках, читать, смеяться, спать и проводить время со своим мужем, 3 детьми и 2 собаками. Просмотреть все сообщения Кэти Хельгесен → .