
Учитывает ли google noindex: Учитывает ли Google такие ссылки
Что это за теги Nofollow и Noindex, в чем разница и как правильно прописывать
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.

- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
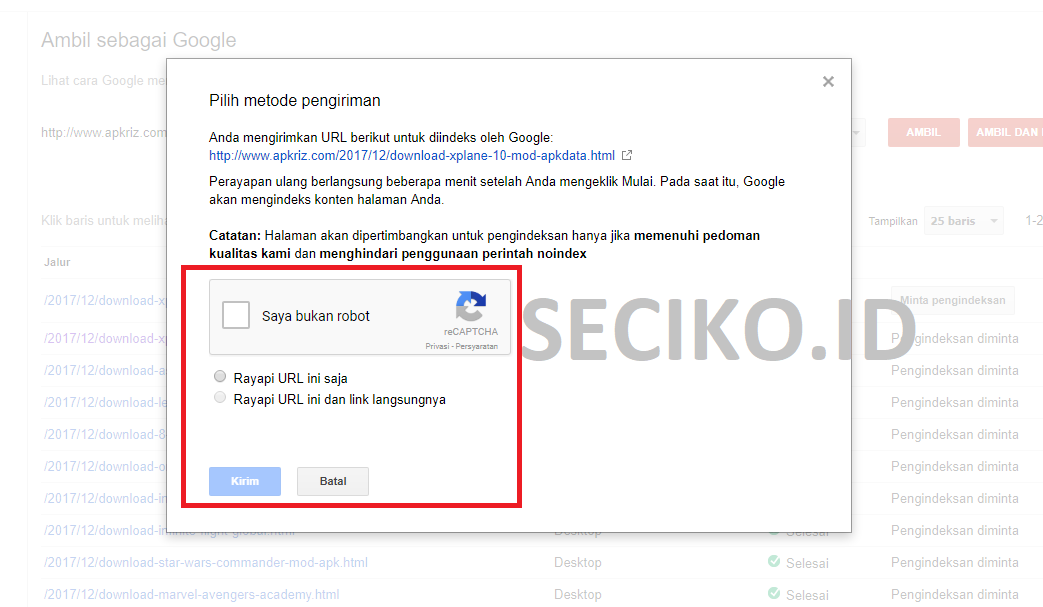
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта.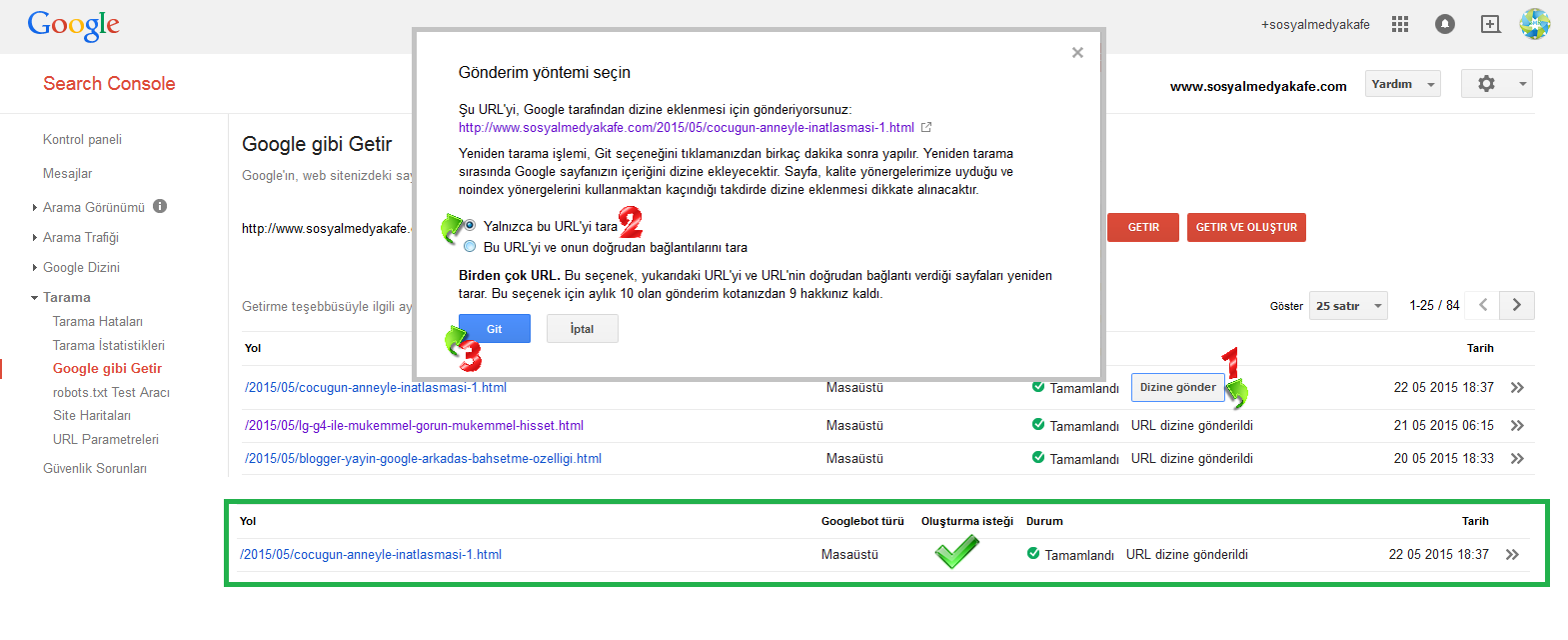
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
 Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком.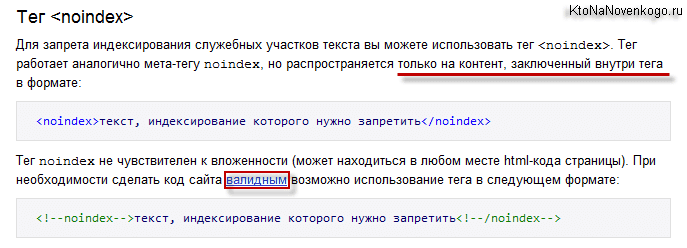 Посмотрим, как разрешить для роботов весь контент и все ссылки:
Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
Эксперимент с meta-тегом robots — Devaka SEO Блог
9331 просмотров
В начале ноября Игорь Бакалов провел интересный эксперимент для проверки, как поисковые системы учитывают meta-robots, а именно инструкции index/noindex, follow/nofollow. Результаты оказались такие, что Google интерпретирует всё, как описано в документации для вебмастеров, а Яндекс не переходит по ссылкам и не индексирует документы, находящиеся в разделах с мета-тегом “noindex,follow”.
Этот результат оказался странным, так как в документации Яндекса имеется явный пример с использованием мета-тега robots “noindex, follow”. Возможно, прошло мало времени, прежде чем делать выводы, либо где-то в эксперименте была допущена ошибка, а может быть Яндекс, действительно, учитывает всё не так, как рекомендует использовать.
В связи с этим было решено повторить эксперимент, при этом уменьшить различные возражения:
— Использовать больше страниц, чтобы сделать выборку репрезентативней.
— Дождаться более полной индексации страниц экспериментального сайта. Поставить дополнительные ссылки для ускорения индексации, при необходимости.
— Проверить маршрут поисковых ботов по серверным логам access_log.
Гипотеза эксперимента:
Проведение эксперимента
Для проведения эксперимента 28 ноября был создан поддомен exp.devaka.ru, на главной странице размещены ссылки на 4 основных раздела. Структура разделов имеет следующий вид:
В разделы, имеющие бОльшую неопределенность в индексации, было добавлено больше тестовых страниц. Всего сайт содержал 14 (и 2 дополнительные) уникальные страницы. Для поддомена настроено журналирование запросов.
Сайт был добавлен в адурилки Гугла и Яндекса. Через несколько дней Google проиндексировал основные страницы, в Яндексе появилась главная и страница page5.html. Картина не менялась до 6 декабря, после этого было решено поставить сквозняк с блога devaka.ru для ускорения индексации. Только сегодня, 18 декабря основная часть страниц проиндексировалась Яндексом и можно делать выводы.
Через несколько дней Google проиндексировал основные страницы, в Яндексе появилась главная и страница page5.html. Картина не менялась до 6 декабря, после этого было решено поставить сквозняк с блога devaka.ru для ускорения индексации. Только сегодня, 18 декабря основная часть страниц проиндексировалась Яндексом и можно делать выводы.
Результаты
Google, как и ожидалось, проиндексировал страницы “/index/nofollow/”, “/index/follow/”, а также все из раздела follow (3, 4, 5 и 9). Страницы из разделов nofollow не попали за это время в индекс.
Если посмотреть логи и отобрать из них лишь запросы гугла к разделу nofollow, то мы увидим, что он чётко следует правилам мета-тега robots:
66.249.78.213 - - [08/Nov/2014:01:32:48 +0300] "GET /noindex/nofollow/ HTTP/1.0" 200 1910 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 66.249.78.227 - - [08/Nov/2014:01:34:32 +0300] "GET /index/nofollow/ HTTP/1.0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.
 1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:11:13:05 +0300] "GET /index/nofollow/ HTTP/1.0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:11:30:32 +0300] "GET /noindex/nofollow/ HTTP/1.0" 200 1910 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:11:13:05 +0300] "GET /index/nofollow/ HTTP/1.0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:11:30:32 +0300] "GET /noindex/nofollow/ HTTP/1.0" 200 1910 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
По сути, Google сразу же в первый день пробежался по всем разрешенным страницам.
66.249.78.213 - - [08/Nov/2014:00:48:39 +0300] "GET / HTTP/1.0" 200 1738 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 66.249.78.213 - - [08/Nov/2014:01:32:48 +0300] "GET /noindex/nofollow/ HTTP/1.0" 200 1910 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 66.249.64.169 - - [08/Nov/2014:01:33:52 +0300] "GET /index/follow/ HTTP/1.0" 200 1781 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 66.249.78.227 - - [08/Nov/2014:01:34:32 +0300] "GET /index/nofollow/ HTTP/1.
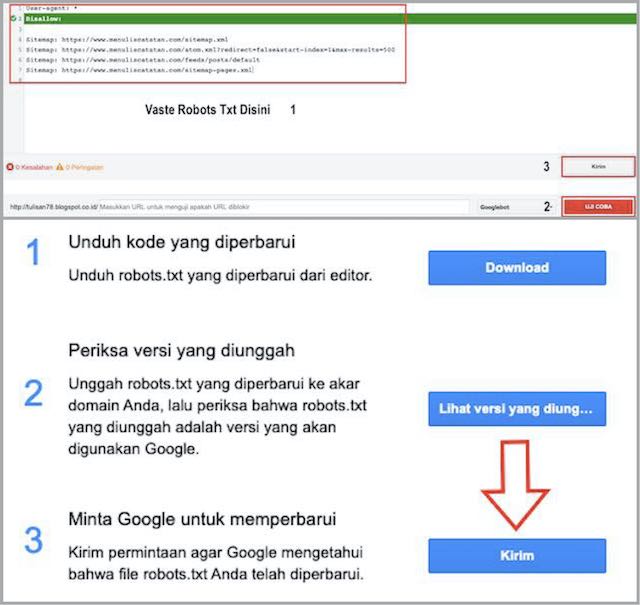 0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:35:12 +0300] "GET /noindex/follow/ HTTP/1.0" 200 2122 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:35:35 +0300] "GET /index/follow/page9.html HTTP/1.0" 200 1703 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:01:40:34 +0300] "GET /noindex/follow/page3.html HTTP/1.0" 200 2024 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:40:35 +0300] "GET /noindex/follow/page5.html HTTP/1.0" 200 2005 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:40:35 +0300] "GET /noindex/follow/page4.html HTTP/1.0" 200 1875 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.213 - - [08/Nov/2014:10:31:06 +0300] "GET /index/follow/ HTTP/1.
0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:35:12 +0300] "GET /noindex/follow/ HTTP/1.0" 200 2122 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:35:35 +0300] "GET /index/follow/page9.html HTTP/1.0" 200 1703 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:01:40:34 +0300] "GET /noindex/follow/page3.html HTTP/1.0" 200 2024 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:40:35 +0300] "GET /noindex/follow/page5.html HTTP/1.0" 200 2005 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:01:40:35 +0300] "GET /noindex/follow/page4.html HTTP/1.0" 200 1875 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.213 - - [08/Nov/2014:10:31:06 +0300] "GET /index/follow/ HTTP/1.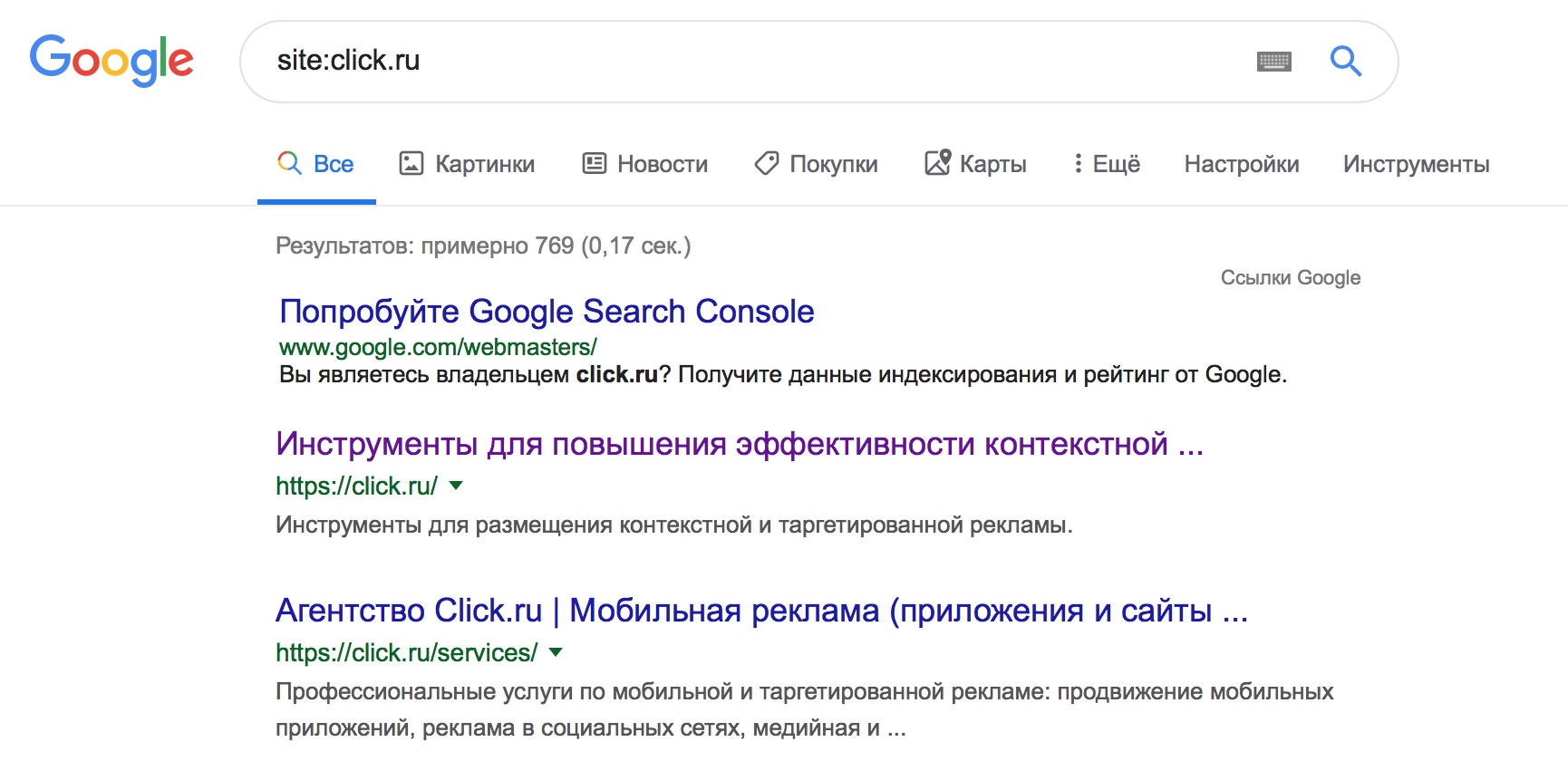 0" 200 1781 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:11:13:05 +0300] "GET /index/nofollow/ HTTP/1.0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:11:16:07 +0300] "GET /noindex/follow/ HTTP/1.0" 200 2122 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:11:30:32 +0300] "GET /noindex/nofollow/ HTTP/1.0" 200 1910 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
0" 200 1781 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:11:13:05 +0300] "GET /index/nofollow/ HTTP/1.0" 200 2280 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.227 - - [08/Nov/2014:11:16:07 +0300] "GET /noindex/follow/ HTTP/1.0" 200 2122 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.78.220 - - [08/Nov/2014:11:30:32 +0300] "GET /noindex/nofollow/ HTTP/1.0" 200 1910 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
В индекс Яндекса попали страницы 1, 2, 3, 4 и 5 из разделов noindex-follow и noindex-nofollow. При этом, не попали страницы из раздела index (скорей всего просто не успели проиндексироваться, как минимум документ в index-follow в эксперименте Игоря индексировался).
Если посмотреть серверные логи, то в них видно, что в первый день Яндекс просканировал основные разделы, находящиеся в на 2м уровне вложенности. Но на следующий день он просканировал почти все документы в этих разделах, игнорируя лишь страницы 6, 7 и 8 (из р
Но на следующий день он просканировал почти все документы в этих разделах, игнорируя лишь страницы 6, 7 и 8 (из р
5 способов закрыть сайт от индексации в Google и Яндекс
Очень часто требуется закрыть сайт от индексации, например при его разработке, чтобы ненужная информация не попала в индекс поисковых систем или по другим причинам. При этом есть множество способов, как это можно сделать, все их мы и рассмотрим в этой статье.
Зачем сайт закрывают для индекса?
Есть несколько причин, которые заставляют вебмастеров скрывать свои проекты от поисковых роботов. Зачастую к такой процедуре они прибегают в двух случаях:
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
Не думайте, что если ваш ресурс только появился на свет и вы не отправили поисковикам ссылки для его индексации, то они его не заметят. Роботы помимо ссылок учитывают еще и ваши посещения через браузер.
- Иногда разработчикам требуется поставить вторую версию сайта, аналог основной на которой они тестируют доработки, эту версию с дубликатом сайта лучше тоже закрывать от индексации, чтобы она не смогла навредить основному проекту и не ввести поисковые системы в заблуждение.
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.

Какие есть способы запрета индексации сайта?
- Панель инструментов в WordPress.
- Изменения в файле robots.txt.
- Посредством мета-тега name=“robots”
- Написание кода в настройках сервера.
1. Закрытие индексации через WordPress
Если сайт создан на базе WordPress, это ваш вариант. Скрыть проект от ботов таким образом проще и быстрее всего:
- Перейдите в «Панель управления».
- Затем в «Настройки».
- А после – в «Чтение».
- Отыщите меню «Видимость для поисковиков».
- Возле строки «Рекомендовать поисковым роботам не индексировать сайт» поставьте галочку.
- Сохраните изменения.

Благодаря встроенной функции, движок автоматически изменит robots.txt, откорректировав правила и отключив тем самым индексацию ресурса.
На заметку. Следует отметить, что окончательное решение, включать сайт в индекс или нет, остается за поисковиками, и ниже можно увидеть это предупреждение. Как показывает практика, с Яндексом проблем не возникает, а вот Google может продолжить индексировать документы.
2. Посредством файла robots.txt
Если у вас нет возможности проделать эту операцию в WordPress или у вас стоит другой движок сайта, удалить веб-сайт из поисковиков можно вручную. Это также реализуется несложно. Создайте обычный текстовый документ, разумеется, в формате txt, и назовите его robots.
Затем скиньте его в корневую папку своего портала, чтобы этот файл мог открываться по такому пути site. ru/robots.txt
ru/robots.txt
Но сейчас он у вас пустой, поэтому в нем потребуется прописать соответствующие команды, которые позволят закрыть сайт от индексации полностью или только определенные его элементы. Рассмотрим все варианты, которые вам могут пригодиться.
Закрыть сайта полностью для всех поисковых систем
Укажите в robots.txt команду:
User-agent: * Disallow: /
Это позволит запретить ботам всех поисковиков обрабатывать и вносить в базу данных всю информацию, находящуюся на вашем веб-ресурсе. Проверить документ robots.txt, как мы уже говорили, можно, введя в адресной строке браузера: Название__вашего_домена.ru/robots.txt. Если вы все сделали правильно, то увидите все, что указано в файле. Но если, перейдя по указанному адресу, вам выдаст ошибку 404, то, скорее всего, вы скинули файл не туда.
Отдельную папку
User-agent: * Disallow: /folder/
Так вы скроете все файлы, находящиеся в указанной папке.
Только в Яндексе
User-agent: Yandex Disallow: /
Чтобы перепроверить, получилось ли у вас удалить свой блог из Яндекса, добавьте его в Яндекс.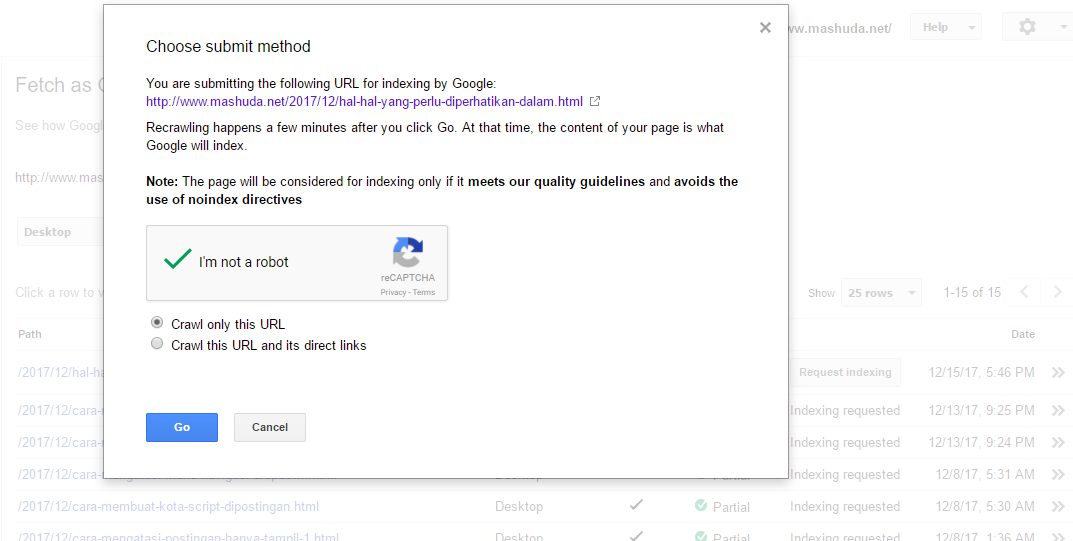 Вебмастер, после чего зайдите в соответствующий раздел по ссылке https://webmaster.yandex.ru/tools/robotstxt/. В поле для проверки URL вставьте несколько ссылок на документы ресурса, и нажмите «Проверить». Если они скрыты от ботов, напротив них в результатах будет написано «Запрещено правилом /*?*».
Вебмастер, после чего зайдите в соответствующий раздел по ссылке https://webmaster.yandex.ru/tools/robotstxt/. В поле для проверки URL вставьте несколько ссылок на документы ресурса, и нажмите «Проверить». Если они скрыты от ботов, напротив них в результатах будет написано «Запрещено правилом /*?*».
Только для Google
User-agent: Googlebot Disallow: /
Проверить, получилось ли сделать запрет, или нет, можно аналогичным способом, что и для Яндекса, только вам нужно будет посетить панель вебмастера Google Search Console. Если документ закрыт от поисковика, то напротив ссылки будет написано «Заблокировано по строке», и вы увидите ту самую строку, которая дала команду ботам не индексировать его.
Но с большой вероятностью вы можете увидеть «Разрешено». Здесь два варианта: либо вы что-то сделали неправильно, либо Google продолжает индексировать запрещенные в документе robots страницы. Я уже упоминал об этом выше, что для поисковых машин данный документ несет лишь рекомендационный характер, и окончательное решение по индексированию остается за ними.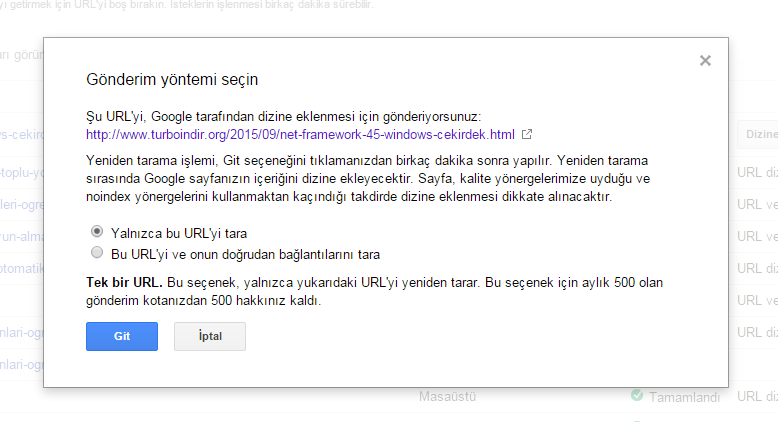
Для других поисковиков
Все поисковики имеют собственных ботов с уникальными именами, чтобы вебмастера могли прописывать их в robots.txt и задавать для них команды. Представляем вашему вниманию самые распространенные (кроме Яндекса и Google):
- Поисковик Yahoo. Имя робота – Slurp.
- Спутник. Имя робота – SputnikBot.
- Bing. Имя робота – MSNBot.
Список имен всех ботов вы с легкостью найдете в интернете.
Скрыть изображения
Чтобы поисковики не могли индексировать картинки, пропишите такие команды (будут зависеть от формата изображения):
User-Agent: * Disallow: *.png Disallow: *.jpg Disallow: *.gif
Закрыть поддомен
Любой поддомен содержит собственный robots.txt. Как правило, он находится в корневой для поддомена папке. Откройте документ, и непосредственно там укажите:
User-agent: * Disallow: /
Если такого текстового документа в папке поддомена нет, создайте его самостоятельно. Parser» search_bot
Parser» search_bot
5. С помощью HTTP заголовка X-Robots-Tag
Это тоже своего рода настройка сервера с помощью файла .htaccess, но этот способ работает на уровне заголовков. Это один из самых авторитетных способов закрытия сайта от индексации, потому что он настраивается на уровне сервера.
Мы подробно расписали как этот способ настроить и использовать в нашей статье.
Как проверить индексацию сайта и страниц?
Если вы не знаете как это сделать, то мы расписали подробно, всевозможные способы в нашей статье — все способы проверки индексации сайта.
Заключение
Вне зависимости от того, по какой причине вы хотите закрыть сайт, отдельные его страницы или материалы от индексации, можете воспользоваться любым из перечисленных способов. Они простые в реализации, и на их настройку не потребуется много времени. Вы самостоятельно сможете скрыть нужную информацию от роботов, однако стоит учесть, что не все методы помогут на 100%.
Noindex — что это? | Media Sova — поддержка и продвижение сайтов
Noindex — существует несколько принципиально разных понятий:
- тег <noindex>,
- мета-тег <meta name ”robots” content=”noindex, nofollow” />
- атрибут rel=”nofollow” (иногда его путают с noindex)
1. Тег <noindex>
 Тег <noindex>
Тег <noindex>Noindex – тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
В исходном коде сайта тег noindex выглядит так:<noindex>Здесь находится закрытый для индексации контент</noindex>
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия noindex
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта.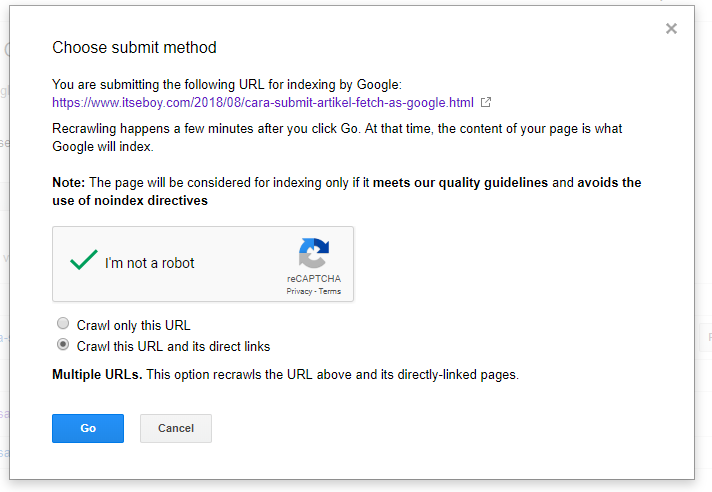 Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
2. <meta name ”robots” content=”noindex” />
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и в исходном коде выглядит так:
<head> ... <meta name ”robots” content=”noindex” /> ... </head>
В примере выше метатег запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.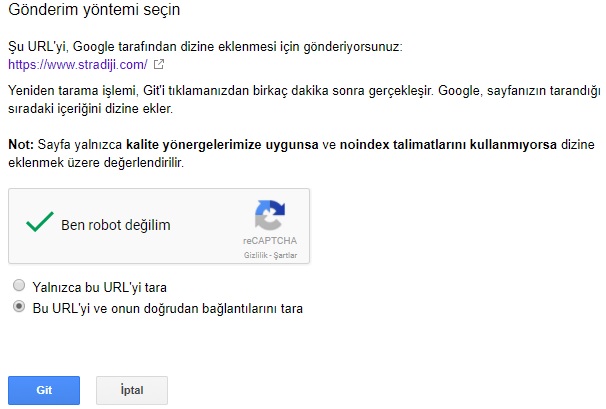
Но обычно используется комбинация с nofollow, чтобы запретить поисковому роботу переходить по ссылкам на данной странице (и по внешним, и по внутренним). В этом случае метатег выглядит так:
<head> ... <meta name ”robots” content=”noindex, nofollow” /> ... </head>
Возможные комбинации noindex + nofollow:
- <meta name=”robots” content=”noindex, follow” /> — используется в случае, если не нужно, чтобы страница была проиндексирована поисковиками, но роботам были доступны ссылки с этой страницы на другие внутренние или внешние ссылки с нее.
- <meta name=”robots” content=”noindex” /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но индексация ссылок на ней возможна.
- <meta name=”robots” content=”noindex, nofollow” /> – запрещает индексировать контент на соответствующей странице + запрещает роботам переходить по ссылкам. Т.е. полный запрет индексирования страницы.
- <meta name=”robots” content=”index, follow” /> – разрешает роботам индексировать страницу и ходить по ссылкам. Использовать данный вариант смысла нет, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия.
- <meta name=”robots” content=”index, nofollow” /> — разрешает индексировать страницу, но запрещает переходить по ссылкам и индексировать их.
- <meta name=”robots” content=”nofollow” /> — делает то же самое, т.е. разрешает индексировать контент на странице, но запрещает индексацию ссылок.
 Т.е. полный запрет индексирования страницы.
Т.е. полный запрет индексирования страницы.Отдельное использование Noindex для Google и Yandex
- <meta name=”googlebot” content=”noindex” /> — закрывает страницу от индексации для робота Google
- <meta name=”yandex” content=”noindex” /> — закрывает страницу от индексации для робота Yandex
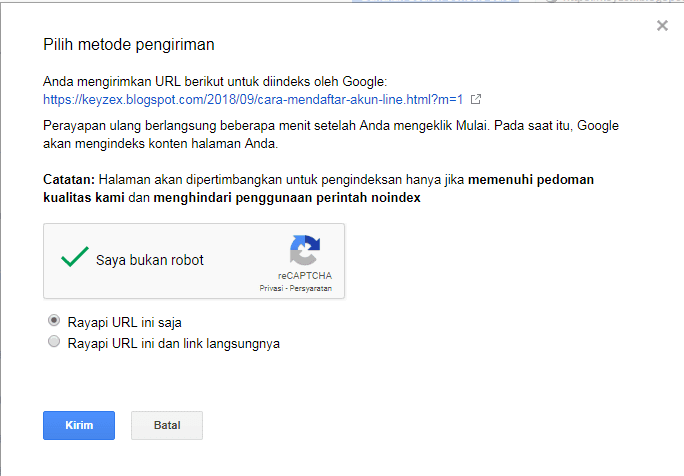
9 проверенных способов заставить Google проиндексировать ваш сайт как можно скорее
В этой статье мы расскажем о проверенных способах заставить Google быстрее проиндексировать контент сайта.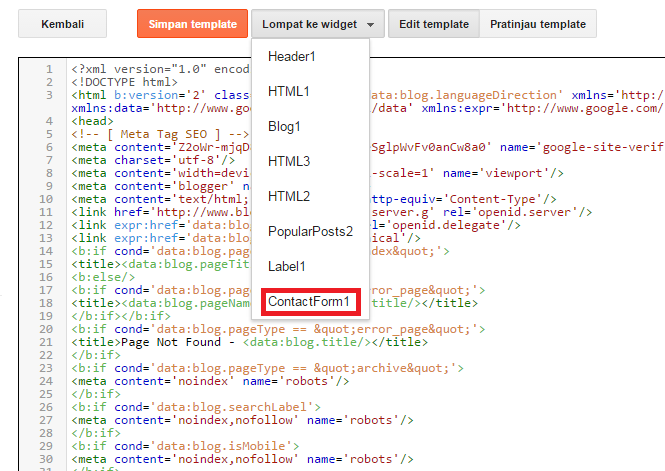
Индексирование – добавление сайта и его страниц в базу данных Google. Благодаря чему ваш сайт отображается в результатах поиска.
Поисковик обнаруживает новый контент на сайте, переходя по различным гиперссылкам. Найдя новые веб-страницы, Google добавляет их в свою базу данных.
Есть два простых способа узнать, проиндексировал ли сайт в Google:
- Выполнить поиск в Google.
- Используя операторы поиска Google. Например, site:www.example.com. Также можно ввести URL-адрес веб-страницы: site:www.example.com/your-web-page.
Кроме этого можно использовать Google Search Console, чтобы проверить статус индексирования конкретных веб-страниц (инструмент «проверка URL»).
Далее мы рассмотрим несколько простых способов быстрой индексации сайта в Google:
Карта сайта – это список важных страниц сайта, представленный в формате XML.
С помощью Sitemap.xml вы помогаете поисковым роботам перемещаться по сайту, находить новый контент и индексировать веб-страницы. Это повышает видимость сайта в поиске и новых веб-страниц, которые еще не имеют обратных ссылок.
Это повышает видимость сайта в поиске и новых веб-страниц, которые еще не имеют обратных ссылок.
Веб-страницы сайта не будут индексироваться, если на нем есть внутренние ссылки с тегом rel=«nofollow». Этот атрибут запрещает поисковым роботам сканировать ссылку.
В результате этого веб-страница не будет отображаться в результатах поиска. Чтобы преодолеть эту проблему, необходимо проверить внутренние ссылки и удалить теги nofollow.
Теги Noindex сообщают Google об исключении веб-страницы из процесса индексации. В результате поисковая система не сохранит веб-страницу в своей базе данных и не отобразит ее в результатах поиска. Тег noindex расположен в разделе <head> веб-страницы.
Для запрета индексации боту Google атрибут name будет включать googlebot.
Удалите этот тег, чтобы Google мог проиндексировать веб-страницу.
Еще один способ поиска тегов noindex – использование инструмента проверки URL-адреса в Search Console.
Если на веб-странице присутствует тег noindex, в http-заголовке «X-Robots-Tag» появится сообщение «обнаружено «Noindex».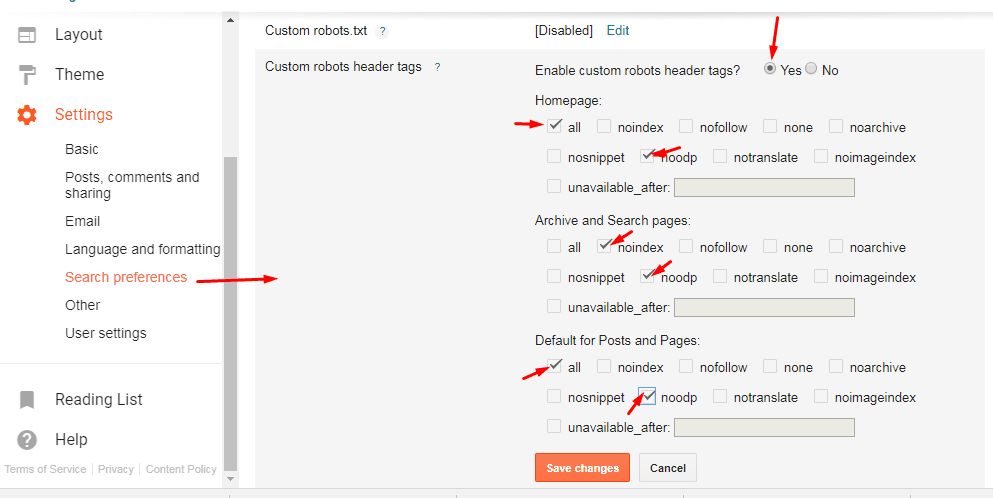
Файл Robots.txt сообщает поисковым роботам, какие веб-страницы они обходить не должны. Вы можете найти файл robots.txt, введя robots.txt в конце URL-адреса сайта (example.com/robots.txt). Теперь найдите следующий фрагмент кода и удалите его.
Этот код не позволяет поисковой системе сканировать сайт. Кроме этого URL-адрес веб-страницы не должен быть заблокирован, особенно для user-agent: googlebot.
Если на сайте тысячи записей, но большинство из них не несет для пользователей никакой пользы, Google сократит количество поисковых сканирований и индексаций площадки.
Если поисковый бот постоянно находит веб-страницы низкого качества, это замедлит обнаружение нового контента, появляющегося на сайте.
Чтобы избежать возникновения подобной проблемы, можно настроить редирект 301 для низкокачественных веб-страниц и перенаправить их на другие более качественные публикации.
Наличие дублированного контента может быть еще одной причиной медленной индексации сайта. Если веб-страница дублируется, Google вряд ли ее проиндексирует.
Чтобы ускорить индексацию сайта, делиться новыми публикациями в социальных сетях. Это повышает шансы на индексацию вашего сайта.
Например, Twitter, отлично подходит для популяризации контента. Google регулярно сканирует Twitter и даже демонстрирует соответствующий сниппет в результатах поиска.
Веб-страницы с высококачественными обратными ссылками будут иметь большее значение для Google, чем те, которые их не имеют. Когда сайт получает обратные ссылки с авторитетных площадок, Google сочтет его заслуживающим доверия и начнет быстрее индексировать контент ресурса.
Если на сайте есть веб-страница, на которой нет внутренних ссылок, Google не сможет найти через нее другой контент. В результате этого для индексации остальных страниц сайта может потребоваться много времени.
На площадке должны быть веб-страницы, которые получают наибольшее количество трафика. Эти веб-страницы могут занимать хорошие позиции в поисковой выдаче Google и должны приносить пользу пользователям.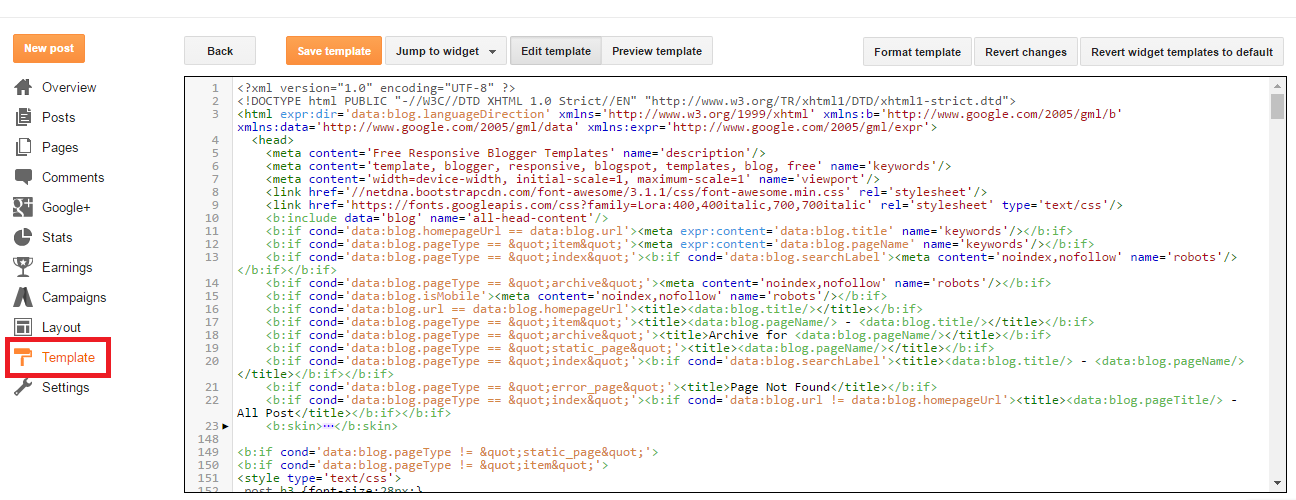 Размещая в них гиперссылки на другие страницы сайта, вы создадите мощные внутренние ссылки.
Размещая в них гиперссылки на другие страницы сайта, вы создадите мощные внутренние ссылки.
Если у вас возникли проблемы с индексацией сайта в Google, воспользуйтесь советами, перечисленными в этой статье.
Данная публикация представляет собой перевод статьи «9 Proven Ways to Get Google to Index Your Website Right Away» , подготовленной дружной командой проекта Интернет-технологии.ру
Индексируемые и не индексируемые ссылки |
Индексируемые и не индексируемые ссылки
В этой статье мы разберем, что значит индексируемая и не индексируемая ссылки и как их применяют.
Наверняка вам знаком факт, что параметры тИЦ и PR, образуются от количества и конечно же качества ссылок, так же знакомы слова, а точнее тэги noindex, nofollow, dofollow, вот об их значении каждого и поговорим в статье.
Когда вы указываете на сайте ссылку на какой-то другой источник, используя тег <a>, то эта ссылка будет индексироваться ПС.
Что это значит? а это значит, что ссылка передает какую-то часть веса вашей страницы на сайт, который ссылается.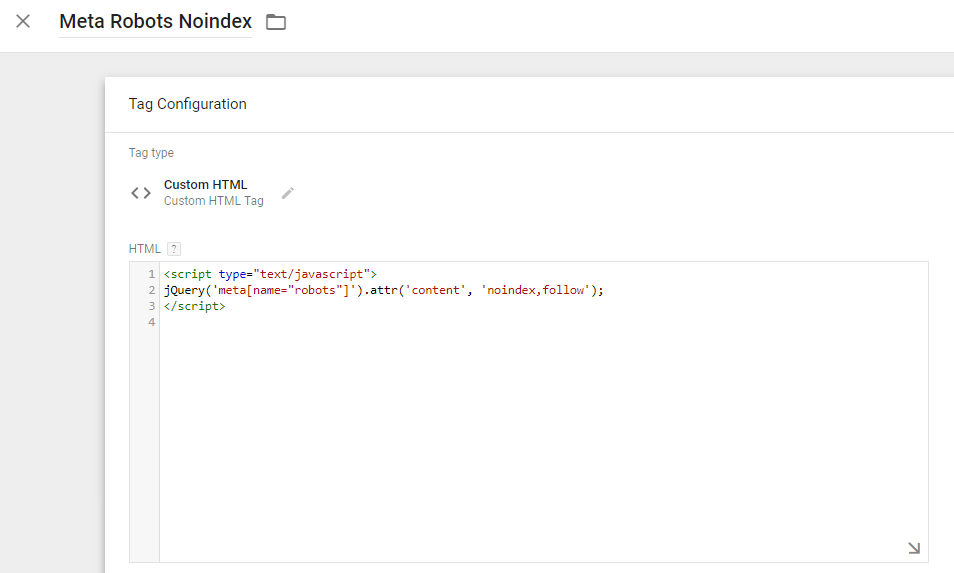 А значит поисковики индексируют (учитывают заносят в свою базу) такую ссылку. А если вы не хотите, чтобы вес передавался на ссылаемый сайт по разным причинам, то можете закрыть атрибутом rel=nofollow.
А значит поисковики индексируют (учитывают заносят в свою базу) такую ссылку. А если вы не хотите, чтобы вес передавался на ссылаемый сайт по разным причинам, то можете закрыть атрибутом rel=nofollow.
Надо заметить, что этот атрибут используется только в теге <a>. Например:
1 | <a href="http://myborder.ru" rel=nofollow >myborder.ru</a> |
<a href=»http://myborder.ru» rel=nofollow >myborder.ru</a>
Чтобы далее было понятно предлагаю ознакомиться с формулировкой, поясню своими словами:
Индексируемая ссылка — это ссылка, которая может передавать часть веса со страницы, где она расположена. Обязательно учитывается ПС.
Не индексируемая ссылка — это та ссылка, которая не передает никакого веса со страницы, где она расположена и не учитывается ПС. В данной ссылке используется атрибут nofollow.
Если ссылка была учтена поисковиками, то этот результат называется индексация ссылок. Те ссылки, которые были учтены яндексом или гуглом можно увидеть в вебмастере. Да, и сразу хочется добавить, что индексация ссылок яндекса отличается от индексации ссылок гугла, потому, что у каждого поисковика свои анализаторы качества ссылок, поэтому одни и те же ссылки могут попасть в яндекс, но некоторые не попадут в гугл и наоборот.
Те ссылки, которые были учтены яндексом или гуглом можно увидеть в вебмастере. Да, и сразу хочется добавить, что индексация ссылок яндекса отличается от индексации ссылок гугла, потому, что у каждого поисковика свои анализаторы качества ссылок, поэтому одни и те же ссылки могут попасть в яндекс, но некоторые не попадут в гугл и наоборот.
Причины для закрытия ссылки на внешний источник.
1. Причин может быть много, но зачастую это делают, для того, чтобы не передавать вес страницы (где расположена ссылка) на непонятный ресурс. Для примера это делают в комментариях, отписываются там много и соответственно ссылок там тоже много.
Мы с вами знаем, что сайты могут быть как СДЛ (сайты для людей) так и ГС (го-но сайты), дабы поисковики не понижали наш сайт в ранжировании за ссылки на ГС, мы закрываем ссылки от индексирования. Можно конечно сортировать, но когда записей в комментариях много, то вручную это хлопотно, поэтому одним волевым решением снимаем все проблемы.
По факту есть ссылка (грубо говоря кликабельная), но вес не передает.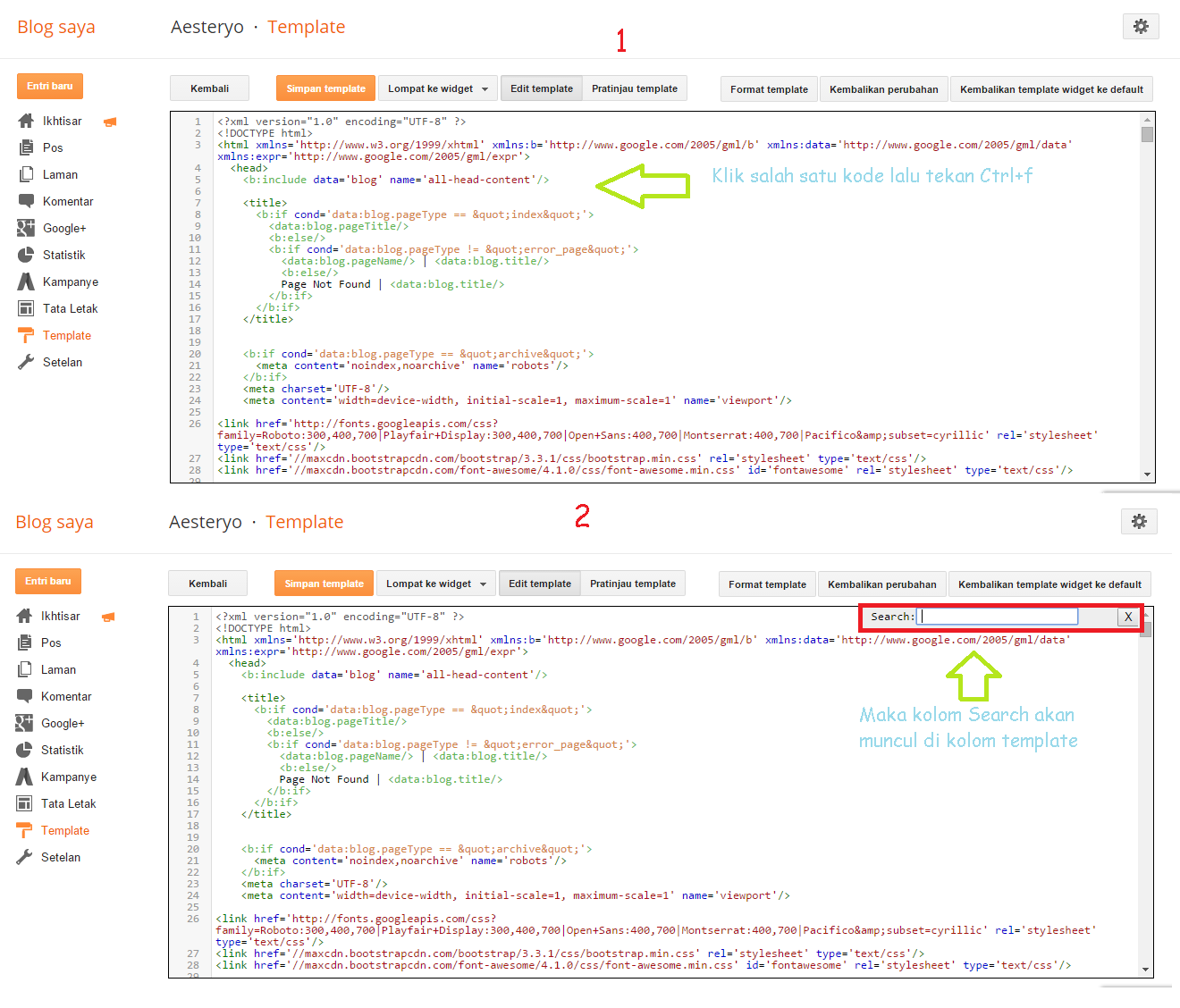
2. По причине множества таких ссылок на странице — это значит, что если много ссылок на странице, то вес отдельно взятой ссылки будет очень мал, так вот, чтобы увеличить вес каждой отдельной ссылки, нужно просто уменьшить их количество.
3. По причине заспамленности ссылками — если ваш сайт насыщен ссылками на внешние источники, то это может быть наказуемо со стороны ПС. Я писал статью про фильтры ПС, так вот на этой странице есть сервис для проверки сайта на разные параметры.
Если введете свой сайт в строку и нажмете проверить, то в отчете есть графа Заспамленность ссылками, и у того, у кого будет гореть желтым этот индикатор, то это значит вы уже ходите по грани и вероятность схватить фильтр от ПС становится велика. Ну а если красным, то возможно вы уже заслужили себе фильтр, что совсем не гуд.
Это чаще бывает, когда вы участвуете в бирже по продаже ссылок, либо любите писать статьи с указанием множества внешних ссылок.
Может не все понимают, но на всякий случай повторим:
АНКОРНАЯ И БЕЗАНКОРНАЯ ССЫЛКИ
Анкорная ссылка — это ссылка с иcпользованием тега <a>.
<a href=»http://myborder.ru»>анкорный текст</a>
Безанкорная ссылка — это ссылка, когда вместо текста указывается url. Пример:
<a href=»http://myborder.ru»>http://myborder.ru</a>
 Пример:
Пример:Для чего тег NOINDEX?
Ранее, до 2010 года Яндекс не воспринимал тег rel=nofollow (хотя Гугл уже использовал его), а значит нужно было закрывать ссылки для яндекса его(старым способом), а для гугла — новым. Посему код должен был выглядеть следующим образом:
1 | <noindex><a href="http://myborder.ru" rel="nofollow">анкорный текст</a></noindex> |
<noindex><a href=»http://myborder.ru» rel=»nofollow»>анкорный текст</a></noindex>
В этом случае мы удовлетворяли требования обоих поисковиков. Так что, те кто привык использовать ссылки таким форматом, использовали еще долгое время такой вариант.
Так что, те кто привык использовать ссылки таким форматом, использовали еще долгое время такой вариант.
А раз уже основные гиганты яша и гугл установили в этом отношении единый формат, то в нынешнее время достаточно использовать:
1 | <a href="http://myborder.ru" rel="nofollow">анкорный текст</a> |
<a href=»http://myborder.ru» rel=»nofollow»>анкорный текст</a>
Конечно может Яша не отказался от старого формата, но новый уже точно принят, поэтому, если норма принята, то не нужно забивать голову и сайт лишней информацией.
Для чего атрибут DOFOLLOW?
Суть в том, что когда мы указываем в ссылке атрибут nofollow, то ссылка становится неиндексируемой, то есть поисковик не учитывает ссылку. А когда этот атрибут не указываем, то ссылка будет автоматически считаться всеми как dofollow, просто по умолчанию. Вот в этом случае ПС учитывают эту ссылку и эта ссылка приобретает свой вес(в глазах поисковиков).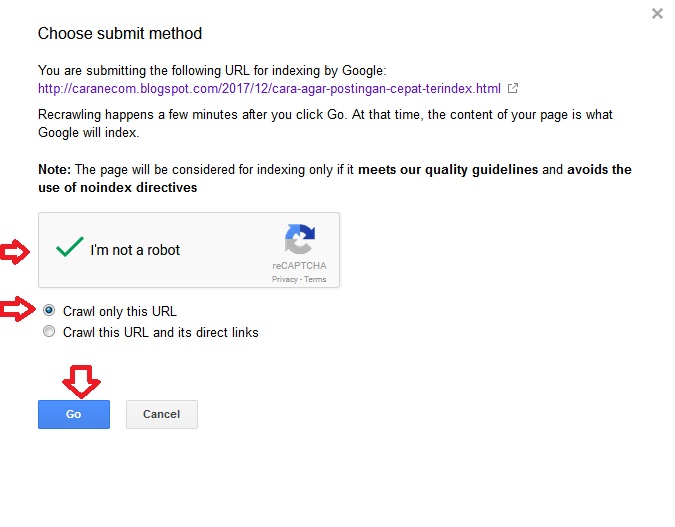
Конечно можно и указать этот тег, но опять же зачем лишний код, когда и так все понимают, что это единое правило.
Для информации скажу, что если вы видите на сайте эмблему или надпись dofollow, то значит в комментариях ссылки не закрыты атрибутом nofollow. Это делают как правило мало-мальские раскрученные сайты, которые уже имеют достаточно большой тИЦ и таким не так важно экономить вес своих страниц. Более того это привлекает тех, кто хочет оставить обратную ссылку на свой сайт. Что явно добавит посещаемости.
Такой фактор притягивает и служит уже рекламой для увеличения притока посетителей. Отступая от темы скажу, часто многие сайты упираются в определенный порог посещаемости и не могут его перепрыгнуть, это говорит о том, что нужно что-то улучшать, добавлять и привлекать. В таком случае многие применяют такую фишку и делают сайт DOFOLLOW, и это оправдано + ваш сайт внесут в списки DOFOLLOW сайтов, которых в интернете не так много. А сие значит, что у вас прибавится количество бэк-линков.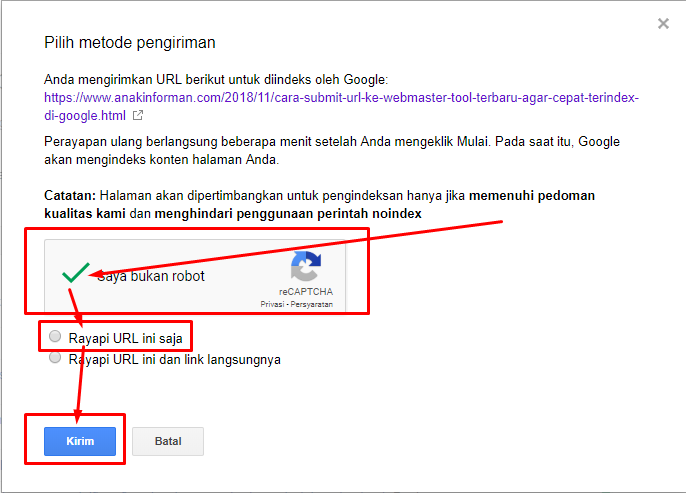
Еще хотел бы добавить, что процесс индексирования ссылок можно ускорить, т.е. чтобы ссылки быстрее были учтены ПС можно воспользоваться определенными сервисами и программами, а почитать об этом можно здесь.
Если у вас возникли вопросы задавайте.
Всем удачи!
Что делать NOINDEX?
Ладно, кому-то этот пост будет колоссально скучен. Но я хотел дать вам возможность взглянуть на дебаты за кулисами в группе качества поиска Google. Вот обсуждение политики NOINDEX и того, как Google должен обрабатывать метатег NOINDEX. Во-первых, вы хотите прочитать этот пост о том, как Google обрабатывает метатег NOINDEX. Вы также можете посмотреть это видео о том, как удалить свой контент из Google или вообще предотвратить его индексирование.Вот вывод из моего предыдущего сообщения в блоге:
Итак, исходя из размера выборки в одну страницу, похоже, что поисковые системы обрабатывают метатег «NOINDEX»:
— Google никак не отображает страницу
— Ask никак не отображает страницу
— MSN показывает ссылку на URL и кешированную ссылку, но без фрагмента.
— Yahoo! показывает ссылку на URL и кешированную ссылку, но без фрагмента. Щелчок по кэшированной ссылке возвращает кешированную страницу.
 Нажатие на кешированную ссылку ничего не возвращает.
Нажатие на кешированную ссылку ничего не возвращает. Вопрос в том, следует ли Google полностью исключать страницу с NOINDEX из результатов поиска или показывать ссылку на страницу или что-то среднее между ними? Приведу аргументы по каждому:
Полностью удалить страницу NOINDEX
Так мы поступаем последние несколько лет, и веб-мастера к этому привыкли. Мета-тег NOINDEX дает хороший — по сути, единственный способ — полностью удалить все следы сайта из Google (другой способ — наш инструмент для удаления URL).Это невероятно полезно для веб-мастеров. Единственный угловой случай заключается в том, что если Google видит ссылку на страницу A, но на самом деле не сканирует ее, мы не узнаем, что страница A имеет тег NOINDEX, и можем показать страницу как непросканированный URL. Для этого есть интересное средство: в настоящее время Google разрешает директиву NOINDEX в robots. txt, которая полностью удаляет все соответствующие URL-адреса сайтов из Google. (Это поведение, конечно, может измениться в результате обсуждения политики, поэтому мы не особо об этом говорили.)
txt, которая полностью удаляет все соответствующие URL-адреса сайтов из Google. (Это поведение, конечно, может измениться в результате обсуждения политики, поэтому мы не особо об этом говорили.)
Веб-мастера иногда стреляют себе в ногу, используя NOINDEX, но если посещаемость сайта из Google очень низкая, веб-мастер будет мотивирован самостоятельно диагностировать проблему. Кроме того, мы могли бы добавить проверку NOINDEX в консоль для веб-мастеров, чтобы помочь веб-мастерам самостоятельно диагностировать, удалили ли они свой собственный сайт с помощью NOINDEX. Мета-тег NOINDEX выполняет полезную роль, отличную от robots.txt, и этот тег находится достаточно далеко от проторенного пути, поэтому мало кто использует тег NOINDEX по ошибке.
Показать ссылку / ссылку на страницы NOINDEX
Наш высший долг — перед нашими пользователями, а не перед отдельным веб-мастером. Когда пользователь выполняет навигационный запрос, а мы не возвращаем нужную ссылку из-за тега NOINDEX, это ухудшает взаимодействие с пользователем (плюс это похоже на проблему Google). Если веб-мастер действительно хочет, чтобы его не было в Google, он может использовать инструмент удаления URL-адресов Google. Цифры небольшие, но мы определенно видим, что некоторые сайты случайно удаляются из Google.Например, если веб-мастер добавляет метатег NOINDEX для завершения сайта, а затем забывает удалить этот тег, сайт не будет отображаться в Google, пока веб-мастер не поймет, в чем проблема. Кроме того, недавно мы увидели, как несколько популярных корейских сайтов не возвращаются в Google, потому что все они имеют метатег NOINDEX. Если громкие сайты вроде
— http://www.police.go.kr/main/index.do (Национальное полицейское агентство Кореи)
— http://www.nmc.go.kr/ (Национальный медицинский центр Кореи)
— http: // www.yonsei.ac.kr/ (Университет Йонсей)
не отображаются в Google из-за метатега NOINDEX, что плохо для пользователей (и, следовательно, для Google).
Некоторая золотая середина между
Подавляющее большинство веб-мастеров, использующих NOINDEX, делают это намеренно и правильно используют метатег (например, для припаркованных доменов, которые они не хотят отображать в Google). Больше всего пользователей обескураживает, когда они ищут известный сайт и не могут его найти. Что, если бы Google по-другому относился к NOINDEX, если бы сайт был хорошо известен? Например, если сайт находился в открытом каталоге, то показать ссылку на страницу, даже если сайт использовал метатег NOINDEX.В противном случае вообще не показывать сайт. Большинство веб-мастеров могут удалить свой сайт из Google, но Google по-прежнему будет возвращать сайты с более высоким профилем, когда пользователи будут искать их.
Как вы думаете?
Это внутреннее обсуждение, которое мы вели по поводу метатегов NOINDEX. Теперь мне любопытно, что вы думаете. Вот опрос:
{демократия: 6}
Мне также были бы интересны (конструктивные) предложения в комментариях о том, как Google должен обрабатывать метатег NOINDEX.Прежде чем оставлять комментарий, постарайтесь занять место как обычного пользователя, так и владельца сайта.
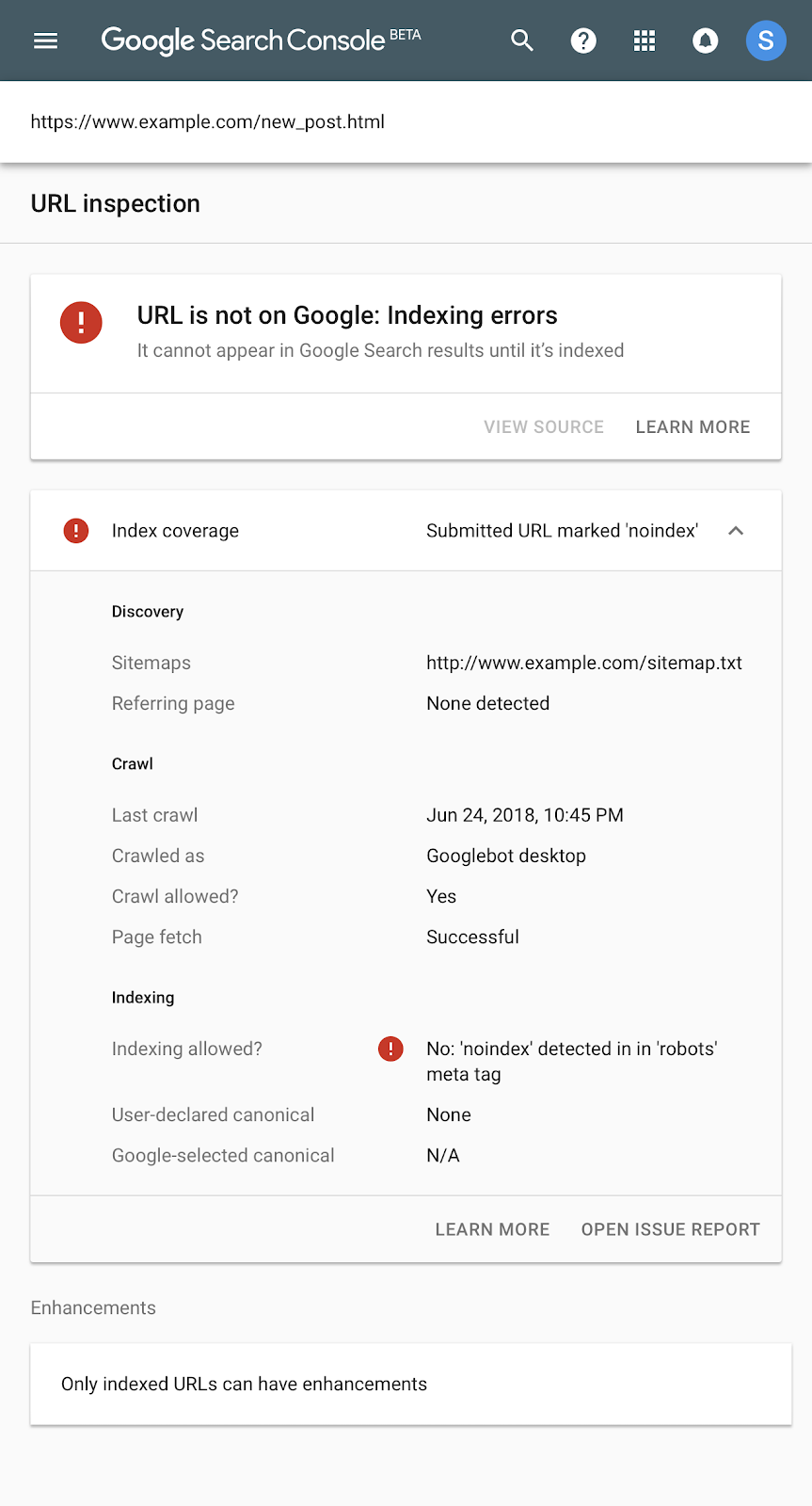
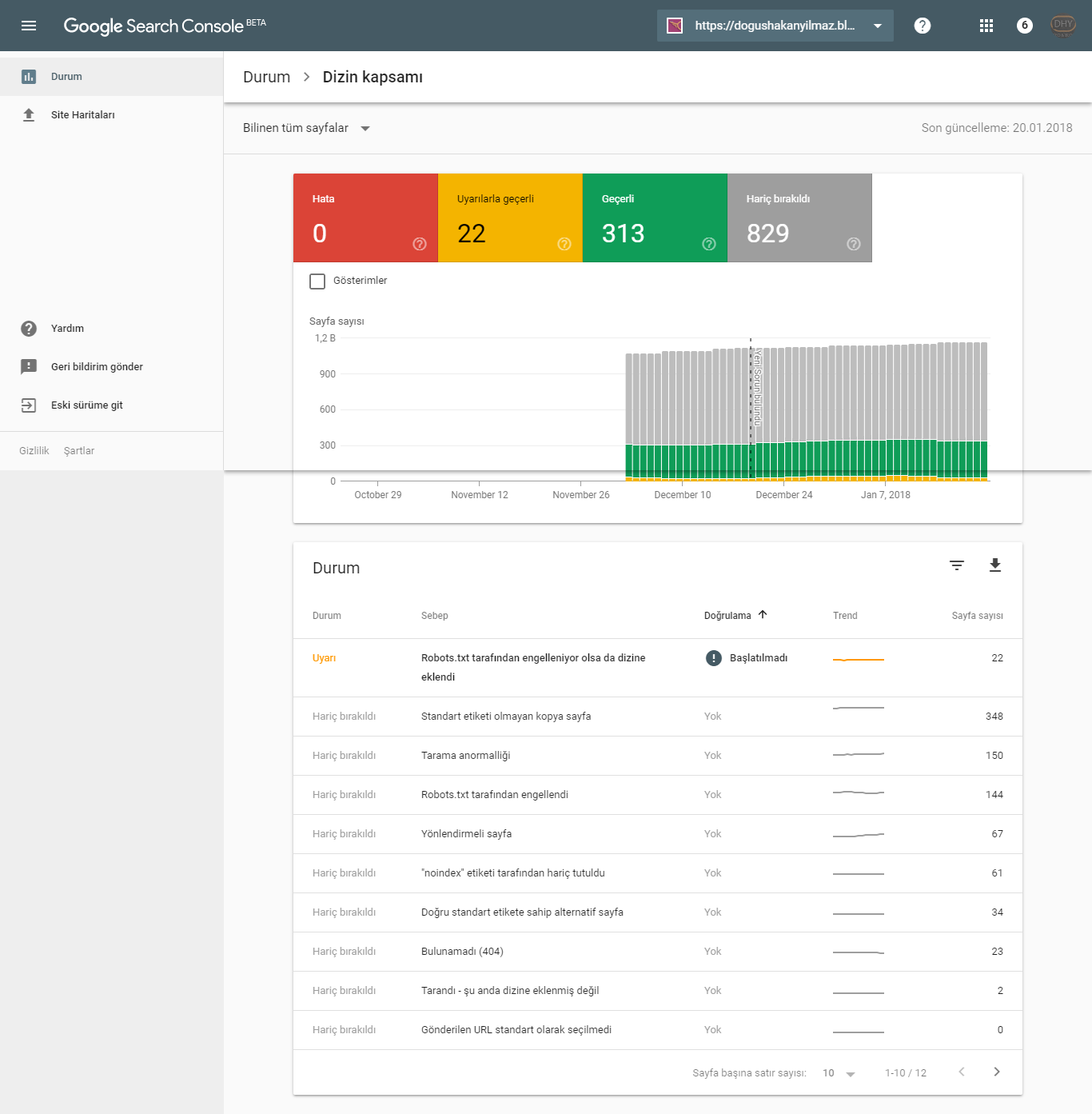
Отправленный URL с пометкой «noindex» — Google Search Console
ПОСЛЕ ОБНОВЛЕНИЯ: 25 ИЮЛЯ 2020 ГОДА
В текущей версии Google Search Console на вашем сайте может быть один или несколько результатов для этой ошибки: Статус> Охват индекса> Отправленный URL с пометкой «noindex»
Это не обязательно ошибка, хотя, если сайт не индексируется должным образом, это отличное место для начала.
Страница, для которой задано значение «noindex» (в отличие от «index» по умолчанию), запрашивает в Google, чтобы эта страница не индексировалась и не отображалась в результатах поиска. Google может сканировать эту страницу и переходить по исходящим ссылкам, а также может отображать сокращенный список в поисковой выдаче.
Вот пример. Наш клиентский портал называется noindex, потому что он предназначен только для клиентов. В результатах поиска нет контента, который мы хотели бы найти. Ниже вы можете увидеть, что Google знает, что этот сайт существует, а главная страница находится в индексе Google.Помимо этого, Google сообщает нам, что «информация об этой странице недоступна», что нас устраивает.
Зачем вам нужна страница с пометкой noindex?
В WordPress разделы сайта (будь то пользовательский тип сообщения или часть таксономии) могут быть помечены как «noindex» по разным причинам, особенно если нет дополнительной информации, помимо набора ссылок. Представьте, что пользователь попадает на такую страницу и пытается понять ее смысл. Если не добавлено никакой дополнительной ценности или контекста, вероятность участия пользователя снижается, что является упущенной возможностью и негативно воспринимается Google (по намерениям пользователя, продолжительности пребывания на сайте, показателю отказов и т. Д.).
Проверить все при запуске сайта: Asterisk обходится US Open в тысячи посетителей
При просмотре ошибки «Отправленный URL помечен как noindex» в новой консоли поиска Google сначала убедитесь, что ничего не помечено как «noindex», которого не должно быть. При создании веб-сайта для всего сайта обычно устанавливается значение «noindex», даже если он расположен на сервере, защищенном паролем. Поэтому, когда этот сайт запускается, иногда кто-то забывает изменить этот параметр на «индексировать», и сайт может быть скрыт от Google на неопределенное время! В статье справа представлен отличный пример того, как запустить веб-сайт, не забыв проверить основные настройки.
Woocommerce и noindex
WooCommerce, разработанный Automattic, представляет собой плагин электронной коммерции с открытым исходным кодом для WordPress. Это отличный вариант для небольших каталогов с возможностью добавления множества плагинов, некоторые из которых доступны за определенную плату. По сути, самые маленькие сайты могут развертывать Woocommerce бесплатно, а большие сайты могут платить за такие важные функции, как подписки и шлюзы.
По умолчанию в Woocommerce установлено noindex :
- тележка
- касса
- мой счет
Noindex на этих страницах Woocommerce НЕ является ошибкой.Давайте посмотрим на «цель поиска». Если кто-то ищет «синие виджеты» или «чехол для iPhone SE», для этого пользователя нет смысла переходить на пустую страницу корзины на вашем сайте.
Полезная информация для потребителей и посетителей сайта находится на страницах ваших продуктов, в сообщениях в блогах и т. Д. — это страницы, которые вы хотите установить на index . Любая страница с транзакцией (включая корзину, кассу и страницу «Моя учетная запись») не должна индексироваться, потому что это не то место, куда вы хотите, чтобы кто-то попадал.
Параметры noindex Search Console
- Test Robots.txt Blocking — как в «США. Открыть », файл robots.txt, расположенный в корневом каталоге вашего сайта, может быть причиной того, что страница, каталог или весь сайт не индексируются. Необходимо проверить файлы noindex и robots.txt на предмет возможных направлений в Google.
- Просмотреть как Google — посмотрите, как Google видит вашу страницу как на компьютере, так и на мобильном устройстве. Вы можете щелкнуть по нему, чтобы увидеть код страницы (то, что Google называет «загруженным HTTP-ответом») и то, как он отображается для Google vs.настоящие люди-посетители.
- Просмотреть как результат поиска — поскольку для страницы задано значение «noindex», она не должна отображать результаты или, возможно, скрытую версию, которую мы видели в примере клиентского портала выше.
- Отправить в индекс — это применимо только в том случае, если вы изменили страницу с «noindex» на «index» и впоследствии хотите убедиться, что Google ее видит. Как правило, мы хотим, чтобы Google органически сканировал только что проиндексированную страницу с помощью навигации веб-сайта и внутренней структуры ссылок, но использование параметра «Отправить в индекс» может быть полезным для решения проблемы.
Когда индексировать noindex
Просмотр страниц noindex в Google Search Console показывает нам, где могут быть возможности SEO, готовые для выбора. Это влечет за собой «индексирование» определенных страниц и добавление качественного полезного контента.
Страница автора по умолчанию обычно содержит только ссылки на сообщения этого автора. Глядя на это с точки зрения пользователя, как мы можем повысить ценность страницы автора, которая в противном случае представляет собой набор ссылок? Мы можем добавить полную биографию автора и карусель фотографий.Это создает более всесторонний контекст для ссылок на сообщения автора. Мы также можем настроить заголовок страницы, мета-заголовок и мета-описание.
Например, эти два элемента (Заголовок страницы и Мета-заголовок) могут по умолчанию называться «Архивы авторов: Боб Смит», а их лучше назвать как-то вроде «Боб Смит, избранный автор» или «Боб Смит, шеф-повар и еда. Критик». После того, как страница была изменена с «noindex» на «index», она стала намного лучше позиционироваться для ранжирования по релевантным поисковым запросам и , чтобы одновременно привлекать посетителей сайта.
Как удалить тег noindex в WordPress
Если вам нужно удалить noindex со страницы в WordPress, лучше всего использовать плагин Yoast SEO.
Когда бы вы хотели это сделать? Хорошим примером может быть ситуация, когда вы создаете новую домашнюю страницу и хотите показать ее нескольким людям, но пока не хотите, чтобы она была общедоступной (в качестве альтернативы вы можете установить на ней пароль для этих получателей).
Другой пример: вы создаете почти повторяющиеся целевые страницы для рекламных кампаний.Обычно вы не хотите, чтобы эти страницы индексировались для обычных результатов поиска.
Во-первых, отредактируйте страницу или сообщение, которое вы не хотите индексировать. Затем прокрутите вниз до поля Yoast SEO, которое должно появиться под областью основного контента, будь то редактор Classic или Gutenberg. Щелкните значок шестеренки.
Найдите это: Разрешить поисковым системам показывать это сообщение в результатах поиска? Это настройка noindex ! Измените «По умолчанию для сообщений, в настоящее время: Да» на «Нет» и нажмите синюю кнопку «Обновить».
Для тестирования перейдите к своему файлу Sitemap и просмотрите его. Если вы используете карту сайта Yoast SEO, вашим URL будет yoursite.com/sitemap_index.xml
.Щелкните файл post-sitemap.xml или page-sitemap.xml (в зависимости от того, устанавливаете ли вы noindex на странице или в сообщении) и убедитесь, что ваше предполагаемое действие правильное — вы не должны видеть страницу или сообщение, отмеченные как noindex. Вуаля.
Если у вас есть магазин Woocommerce, вы также можете сделать это для продуктов, просмотрев карту сайта продукта.xml, чтобы проверить свою работу.
Категории и теги
Категории и теги также являются вероятными кандидатами на «noindex». Это потому, что они просто собирают множество контента без добавления ценности. Эта возможность SEO (которую я называю SEO таксономии) заключается в добавлении качественного контента, который повышает ценность собранных сообщений по этой теме.
Например, допустим, на веб-сайте рецептов есть 8 рецептов, помеченных как «морковь». Посетив эту страницу, вы увидите восемь заголовков, возможно, с некоторыми дополнительными метаданными, такими как выдержка, автор, дата и количество комментариев.Он может иметь заголовок страницы и мета-заголовок «Архив тегов: морковь». Вот и все. Это не впечатляет.
Как добавить ценность? Начните с добавления 500 слов или более в верхнюю и / или нижнюю часть страницы, поместив слово «морковь» в контекст — кулинарное происхождение моркови, различные сорта моркови, как описывается вкус моркови, как морковь используется в как соленые, так и сладкие блюда и др.
Удобно для маркетологов: Руководство по размеру изображений и видео в социальных сетях
Измените мета-заголовок, мета-описание и заголовок страницы, чтобы более точно описывать рецепты моркови.Добавьте несколько высококачественных изображений, достаточно больших для публикации в социальных сетях.
Давайте поднимем его на ступеньку выше. Затем вы можете отредактировать каждую статью с тегом «морковь» и написать собственный отрывок из 50 слов или около того, который будет уникальным для содержания на странице. Это создает настоящую, уникальную, интересную страницу, представляющую ценность как для Google, так и для посетителей сайта.
Соберите все эти элементы вместе, и эта страница будет готова для индексации. Обратите внимание, что для выполнения вышеуказанных изменений может потребоваться плагин или некоторое время разработчика.
Проверьте свою карту сайта
Если у вашего сайта есть карта сайта, вот полезный совет. Посмотри на это! В карте сайта может быть любое количество страниц, которые вам на самом деле не нужны (которая, по сути, сообщает пауку поисковой системы, какие страницы он может сканировать). Например:
- тестовых страниц
- старые, устаревшие страницы
- административных страниц
- страниц подтверждения
Как узнать, есть ли у вас карта сайта? Сначала попробуйте зайти на ваш сайт .ru / sitemap.xml . Если это не дает никаких результатов, обратитесь к своему веб-разработчику, который обычно может включить карту сайта с помощью быстрого плагина. Также следует отметить, что карты сайта могут быть отправлены в Google Search Console для проверки и сканирования, хотя стратегия и эффективность этого являются темой другого сообщения.
Если на вашем сайте есть страницы в карте сайта, которые вы не хотите отображать, вам нужно сделать две вещи:
- изменить статус каждой страницы на «noindex»
- исключить страницу из карты сайта
То, как вы это делаете, во многом зависит от того, как настроен ваш сайт.В WordPress для управления обоими этими вещами широко используется бесплатный плагин Yoast SEO.
ОБНОВЛЕНИЕ: 23 июля 2020 г. — согласно Search Engine Journal, новая версия WordPress — 5.5 — будет поддерживать файлы Sitemap. Интересно! Очевидно, это потребует от веб-хостов установки расширения SimpleXML PHP. Для некоторых компаний, занимающихся веб-хостингом, это может быть нереально, но в целом я думаю, что мы, вероятно, увидим широкую поддержку этого, учитывая большую установленную базу пользователей WP.
Об этом noindex Summary
Google, помечающий страницы «noindex» как ошибки в Search Console, может быть весьма показательным.Используйте эту возможность, чтобы убедиться, что фактически скрытые страницы должны быть скрыты. Также ищите возможности для создания отличного содержания для ваших посетителей на страницах, которые можно было бы изменить на «индексировать». И проверьте свою карту сайта — она может быть довольно показательной в самых неожиданных случаях. Дайте нам знать в комментариях ниже, если у вас есть вопросы!
Вы дизайнер или разработчик WordPress? Мы — агентство веб-маркетинга, оптимизированное для WordPress. Ознакомьтесь с нашей партнерской программой (WP) и узнайте, как мы можем поддержать ваших клиентов и обеспечить вам долгосрочный бизнес.
канонических и метатегов через GTM / JavaScript
Google Tag Manager SEO: канонические и метатеги через GTM / JavaScriptМы используем файлы cookie на нашем веб-сайте. Некоторые из них очень важны, а другие помогают нам улучшить этот веб-сайт и улучшить ваш опыт.
Принять все
Сохранить
Индивидуальные настройки конфиденциальности
Детали куки политика конфиденциальности Отпечаток
Предпочтение конфиденциальностиЗдесь вы найдете обзор всех используемых файлов cookie.Вы можете дать свое согласие на использование целых категорий или отобразить дополнительную информацию и выбрать определенные файлы cookie.
| Имя | Borlabs Cookie |
|---|---|
| Провайдер | Владелец этого сайта |
| Назначение | Сохраняет предпочтения посетителей, выбранные в поле Cookie Borlabs Cookie. |
| Имя файла cookie | borlabs-cookie |
| Срок действия куки | 1 год |
| Имя | Диспетчер тегов Google |
|---|---|
| Провайдер | Google LLC |
| Назначение | Cookie от Google, используемый для управления расширенными скриптами и обработкой событий. |
| Политика конфиденциальности | https://policies.google.com/privacy?hl=en |
| Имя файла cookie | _ga, _gat, _gid |
| Срок действия куки | 2 года |
| Имя | Контактные формы |
|---|---|
| Провайдер | Hubspot Inc. |
| Назначение | Пользователь связался с searchVIU. |
| Политика конфиденциальности | https: //legal.hubspot.ru / политика конфиденциальности |
| Хост (ы) | hsforms.net |
| Имя файла cookie | __cfduid |
| Срок действия куки | 1 месяц |
| Принять | |
|---|---|
| Имя | HubSpot |
| Провайдер | HubSpot Inc. |
| Назначение | HubSpot — это служба управления базами данных пользователей, предоставляемая HubSpot, Inc. Мы используем HubSpot на этом веб-сайте для нашей маркетинговой деятельности в Интернете. |
| Политика конфиденциальности | https: // legal.hubspot.com/privacy-policy |
| Хост (ы) | * .hubspot.com, hubspot-avatars.s3.amazonaws.com, hubspot-realtime.ably.io, hubspot-rest.ably.io, js.hs-scripts.com |
| Имя файла cookie | __hs_opt_out, __hs_d_not_track, hs_ab_test, hs-messages-is-open, hs-messages-hide-welcome-message, __hstc, hubspotutk, __hssc, __hssrc, messagesUtk |
| Срок действия куки | сеанс / 30 минут / 1 день / 1 год / 13 месяцев |
мета-тегов роботов и роботов.txt Учебное пособие для Google, Bing и других поисковых систем
Как создавать файлы Robots.txt
Используйте наш генератор Robots.txt, чтобы создать файл robots.txt.
Анализируйте файл Robots.txt
Воспользуйтесь нашим анализатором Robots.txt, чтобы проанализировать свой файл robots.txt уже сегодня.
Google также предлагает аналогичный инструмент в Центре веб-мастеров Google и показывает ошибки сканирования вашего сайта Google.
Пример формата Robots.txt
Разрешить индексацию всего
Пользовательский агент: *
Disallow:
или
Пользовательский агент: *
Разрешить: /
Запретить индексацию всего
Пользовательский агент: *
Disallow: /
Запретить индексирование определенной папки
Пользовательский агент: *
Запретить: / folder /
Запретить роботу Googlebot индексировать папку, за исключением разрешения индексирования одного файла в этой папке
Пользовательский агент: Googlebot
Запретить: / folder1 /
Разрешить: / folder1 / myfile.HTML
Справочная информация о файлах Robots.txt
- Файлы Robots.txt информируют «пауков» поисковых систем о том, как взаимодействовать с индексированием вашего контента.
- По умолчанию поисковые системы жадные. Они хотят проиндексировать как можно больше высококачественной информации и будут считать, что могут сканировать все, если вы не укажете им иное.
- Если вы укажете данные для всех ботов (*) и данные для определенного бота (например, GoogleBot), тогда будут выполняться определенные команды бота, в то время как этот движок игнорирует глобальные / стандартные команды бота .
- Если вы создаете глобальную команду, которую хотите применить к определенному боту, и у вас есть другие особые правила для этого бота, вам необходимо поместить эти глобальные команды в раздел для этого бота, как указано в этой статье Энн Умный.
- Когда вы блокируете индексирование URL-адресов в Google через robots.txt, они могут по-прежнему отображать эти страницы как списки только URL-адресов в своих результатах поиска.Лучшее решение для полной блокировки индекса конкретной страницы — использовать метатег robots noindex для каждой страницы. Вы можете сказать им не индексировать страницу или не индексировать страницы и , чтобы не переходить по исходящим ссылкам, вставив один из следующих битов кода в заголовок HTML вашего документа, который вы не хотите индексировать.
- <- страница не проиндексирована, но по ссылкам можно переходить
- <- страница не индексируется и по ссылкам не переходят
- Обратите внимание, что если вы делаете и то, и другое: заблокируйте поисковые системы в robots.txt и через метатеги, тогда команда robots.txt является основным драйвером, поскольку они могут не сканировать страницу для просмотра метатегов, поэтому URL-адрес может по-прежнему отображаться в результатах поиска, перечисленных только для URL-адресов.
- Если у вас нет файла robots.txt, журналы вашего сервера будут возвращать ошибку 404 всякий раз, когда бот пытается получить доступ к вашему файлу robots.txt. Вы можете загрузить пустой текстовый файл с именем robots.txt в корне вашего сайта (например, seobook.com/robots.txt), если вы не хотите получать ошибки 404, но не хотите предлагать какие-либо конкретные команды для ботов.
- Некоторые поисковые системы позволяют вам указывать адрес XML Sitemap в вашем файле robots.txt, но если ваш сайт небольшой и хорошо структурирован с чистой структурой ссылок, вам не нужно создавать XML Sitemap. Для более крупных сайтов с несколькими подразделениями, сайтов, которые генерируют огромное количество контента каждый день, и / или сайтов с быстро меняющимся запасом, карты сайта XML могут быть полезным инструментом, помогающим индексировать важный контент и отслеживать относительную производительность глубины индексации по типу страницы.
Задержка сканирования
- Поисковые системы позволяют устанавливать приоритеты сканирования.
- Google не поддерживает команду задержки сканирования напрямую, но вы можете снизить приоритет сканирования в Центре веб-мастеров Google.
- Google имеет наибольшую долю рынка поиска на большинстве рынков и имеет один из самых эффективных приоритетов сканирования, поэтому вам не нужно менять приоритет сканирования Google.
- Google имеет наибольшую долю рынка поиска на большинстве рынков и имеет один из самых эффективных приоритетов сканирования, поэтому вам не нужно менять приоритет сканирования Google.
- Вы можете установить Yahoo! Задержки сканирования Slurp в вашем файле robots.txt. (Примечание : на большинстве основных рынков за пределами Японии Yahoo! Search поддерживается Bing, а Google поддерживает поиск в Yahoo! Японии).
- Их код задержки сканирования robots.txt выглядит как
User-agent: Slurp
Задержка сканирования: 5
где 5 в секундах.
- Их код задержки сканирования robots.txt выглядит как
- Google не поддерживает команду задержки сканирования напрямую, но вы можете снизить приоритет сканирования в Центре веб-мастеров Google.
Основы SEO: объяснение мета-роботов «Noindex, Nofollow»
Сегодня мы поговорим о , одной из самых больших ошибок SEO, , которую может сделать владелец веб-сайта (или веб-разработчик): noindex . Одно только упоминание об этом может вызвать у разработчика дрожь.
29.08.2018 Обновление: см. Примечания к обновлению в конце сообщения.
Что такое тег?
Проще говоря, этот метатег сообщает поисковым системам, какие действия они могут (или не предпринимать) на определенной странице.Основные поисковые системы будут соблюдать команды, включенные в этот тег.
Этот метатег может быть включен в любое место между тегами и в заголовке страницы, как показано ниже:
ВАЖНО: Этот тег не имеет общесайтового эффект. Он может содержать разные значения на разных страницах одного и того же веб-сайта.
Доступные значения для тега META ROBOTS
Вот список допустимых значений для тега META ROBOTS.
- Index ( значение по умолчанию )
- Noindex
- Нет
- Follow
- Nofollow
- Noarchive
- Nosnippet
- Noodp ( больше не актуально )
- Noydir ( больше не актуально
4)
90 - Дублированный контент
- Плагиат
- Тонкое содержание
- Спам, создаваемый пользователями
- Начинка ключевого слова
- Плохое взаимодействие с пользователем
- Некачественные ссылки со спамерских сайтов
- Ссылки с сайтов, созданных исключительно для построения ссылок SEO (PBN)
- Ссылки с тематически нерелевантных сайтов
- Платные ссылки
- Ссылки с чрезмерно оптимизированным якорным текстом
- Пиратский контент
- Большое количество сообщений о нарушении авторских прав
- Таргетинг на ключевые слова с точным соответствием
- Начинка ключевого слова
- Плохо оптимизированные страницы
- Неправильная настройка страницы в Google My Business
- Несогласованность NAP
- Отсутствие цитат в локальных справочниках (если есть)
Эти значения можно комбинировать, поэтому, например, все приведенные ниже варианты являются совершенно допустимыми метатегами роботов:
Эффект NOINDEX, NOFOLLOW
Значение NOINDEX указывает поисковым системам НЕ индексировать эту страницу, поэтому в основном эта страница не должна отображаться в результатах поиска.
Значение NOFOLLOW указывает поисковым системам НЕ следить (обнаруживать) страницы, на которые есть СВЯЗЬ на этой странице.
Иногда разработчики добавляют мета-теги роботов NOINDEX, NOFOLLOW на веб-сайты разработки, чтобы поисковые системы случайно не начали отправлять трафик на веб-сайт, который все еще находится в стадии разработки.
Или у вас может быть текущий (действующий) веб-сайт на www.example.com, но вы также храните копию для разработки на www.dev.example.com/. В этом случае рекомендуется использовать noindex, nofollow для версии Dev, чтобы избежать многих потенциальных проблем.
Часто случается так, что люди случайно добавляют этот тег к действующим веб-сайтам, забывают добавить его в разрабатываемые копии или, что еще хуже: забывают удалить его с действующих веб-сайтов после запуска.
Да, такие же результаты и проблемы могут возникнуть из-за плохого файла robots.txt в корне веб-сайта, но это выходит за рамки темы этой публикации.
~ 3% веб-сайтов отелей затронуты
Согласно независимому анализу, проведенному HermesThemes.com из более чем 50 000 веб-сайтов отелей со всего мира, было определено, что ~ 3% веб-сайтов блокируют индексацию своих веб-сайтов поисковыми системами.
Это было шокирующее открытие, которое побудило нас решить проблему в этой статье.
Как проверить, есть ли эта ошибка на моем веб-сайте?
К счастью, есть очень простой способ проверить любой веб-сайт / страницу на наличие этой ошибки.
Просто откройте страницу в своем браузере, щелкните правой кнопкой мыши где-нибудь на странице (но не по ссылкам или изображениям) и выберите «Просмотреть источник страницы».В большинстве браузеров в Windows вы можете просто нажать CTRL + U на клавиатуре.
Откроется новая вкладка с полным HTML-кодом (как его видит браузер) для текущей страницы. Как упоминалось ранее, метатеги обычно находятся в верхней части веб-сайта, как в этом примере:
Если вы видите на этой странице строку META ROBOTS со значением NOINDEX или NONE, вам необходимо немедленно принять меры !
Как затронутые веб-сайты выглядят в результатах поиска?
Я рад, что вы (надеюсь) спросили.
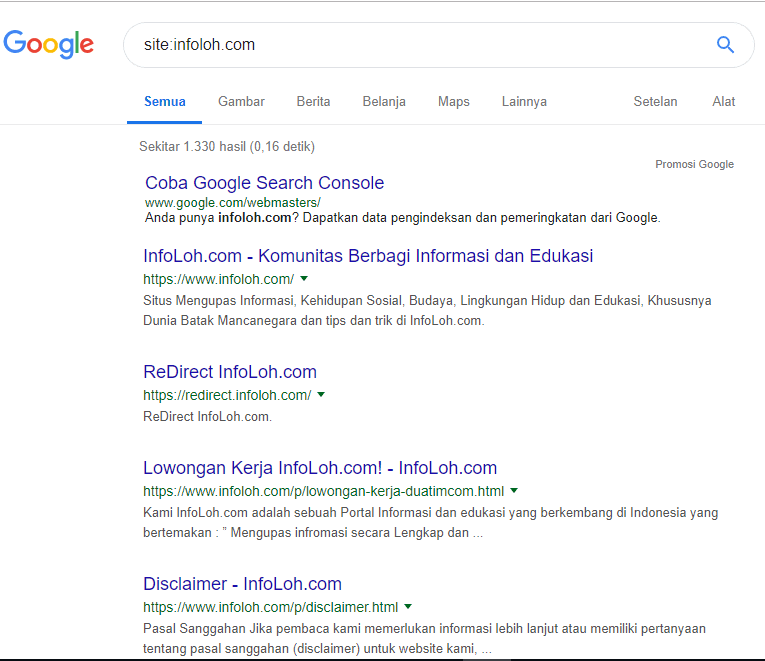
Существует очень удобный способ поиска в Google проиндексированных страниц с определенного доменного имени: [site: example.com] (без квадратных скобок).
Итак, мы заходим в Google и ищем домен, который использует мета-роботов NOINDEX на своем веб-сайте, и вот что мы получаем:
Я надеюсь, что вы понимаете, какой ущерб может быть нанесен, если ваш веб-сайт полностью удален из Google и другие поисковые системы. Ваш органический поисковый трафик упадет до нуля в течение нескольких дней.
Как исправить / удалить строку Meta Robots?
К счастью, решить эту проблему легко, и откладывать ее нельзя. Сначала вам нужно определить, откуда эта линия.
В WordPress первое, что вам нужно сделать, это перейти в Панель управления> Настройки> Чтение.
Убедитесь, что для Search Engine Visibility установлен флажок , не установлен флажок .
Если это не устранило проблему, проверьте, жестко ли закодирована эта строка в теме.
Чтобы проверить это, перейдите в «Внешний вид»> «Редактор», а затем выберите «Заголовок темы header.php» из списка файлов справа (действительно для большинства тем).
Просмотрите этот файл и убедитесь, что в нем нет тега META ROBOTS с вредоносным значением. Если есть — удалите и нажмите синюю кнопку «Обновить файл».
Заключение
Эта строка кода может вызвать большую головную боль, потерю дохода и негативное долгосрочное влияние на SEO.
На ваш сайт влияет NOINDEX? Проверьте сегодня!
Обновления от 29.08.2018:
Я хотел бы уделить время и упомянуть новые цифры от 29 августа 2018 г.
Количество сайтов, которые я анализирую, резко увеличилось. В исходной статье использовались данные, полученные с 50 000 веб-сайтов отелей. Сейчас я анализирую ~ 875 000 уникальных сайтов отелей (уникальных доменов).
Результаты этих 875 000+ веб-сайтов отелей показывают, что 1,502% веб-сайтов отелей используют NOINDEX или NONE в качестве значений мета-роботов.
Процент не кажется высоким, но это более 13 000 веб-сайтов отелей, которые эффективно блокируют индексацию своих веб-сайтов роботами поисковых систем.
Конечно, некоторые из них делают это во время обслуживания своих веб-сайтов. Другие веб-сайты на самом деле пытаются вести себя сдержанно и отображать свой бизнес только с помощью прямых ссылок.
Но я потратил время, чтобы вручную посетить более 200 случайных веб-сайтов из этого списка, и быстро прикинул, что 3/4 из них действительно используют NOINDEX по ошибке. Так вот что.
Связанные
14 основных обновлений алгоритмов Google
Шпаргалка по обновлениям алгоритмов Google
Ваше полное руководство по основным штрафам Google и изменениям алгоритмов
После обновлений 2002 года Google внес явные изменения в свой алгоритм.А когда с первыми обновлениями Panda и Penguin были введены суровые наказания, стало ясно, что компания серьезно относится к созданию этической среды для поиска пользователей.
Фактически, обновления Google происходят каждый день и в основном остаются незамеченными. Компания подтверждает только важные обновления алгоритмов, которые, как ожидается, существенно повлияют на поисковый рейтинг. Чтобы помочь вам разобраться в основных изменениях алгоритмов Google за последние годы и основных факторах ранжирования Google, мы подготовили памятку с наиболее важными обновлениями и штрафами, выпущенными за последние годы, а также список опасностей и способов предотвращения. советы для каждого.
Но прежде чем мы начнем, давайте быстро проверим, повлияло ли какое-либо обновление на трафик вашего собственного сайта. Счетчик рангов от SEO PowerSuite очень помогает в этом; инструмент автоматически сопоставляет даты всех основных обновлений Google с графиками вашего трафика и рейтинга.
1) Запустите трекер рангов (если он у вас не установлен, получите бесплатную версию SEO PowerSuite здесь) и создайте проект для своего сайта, введя его URL и указав целевые ключевые слова.
2) Нажмите кнопку Обновление посещений в верхнем меню Rank Tracker и введите свои учетные данные Google Analytics, чтобы синхронизировать свою учетную запись с инструментом.
3) В нижней части панели инструментов Rank Tracker перейдите на вкладку Organic Traffic .
Пунктирными линиями на вашем графике отмечены даты основных обновлений алгоритмов Google. Изучите график, чтобы увидеть, коррелируют ли падения (или всплески!) Посещений с обновлениями. Наведите указатель мыши на любую из строк, чтобы увидеть, что было за обновление.
Примечание
В настоящее время график в Rank Tracker содержит даты только основных обновлений, а именно обновления Panda, обновления Pigeon, обновления Fred и т. Д. Но график редактируемый и позволяет добавлять те события, которые вы считаете важными для вашей собственной истории отслеживания. Просто щелкните правой кнопкой мыши в поле графика выполнения и выберите добавление события из меню.
Повлияло ли какое-либо изменение алгоритма Google на ваш органический трафик? Прочтите, чтобы узнать, о чем было каждое из обновлений, в чем заключаются основные опасности и как обеспечить безопасность своего сайта.
1. Обновление Panda
Запущено: 24 февраля 2011 г.
Внедрение: ~ ежемесячно
Цель: Понизить рейтинг сайтов с некачественным контентом
Google Panda — это алгоритм, используемый для присвоения оценки качества содержания веб-страницам и сайтам с пониженным рейтингом с низким качеством, спамом или тонким содержанием. Изначально обновление Panda было поисковым фильтром, а не частью основного алгоритма Google, но в январе 2016 года оно было официально включено в алгоритм ранжирования.Хотя это не означает, что Panda теперь применяется к результатам поиска в режиме реального времени, это указывает на то, что как фильтрация, так и восстановление из Google Panda теперь происходит быстрее, чем раньше.
Опасности
Как оставаться в безопасности с Panda
1. Проверьте, нет ли на вашем сайте дублированного контента. Внутренний дублированный контент — один из наиболее распространенных триггеров обновления Google Panda, поэтому рекомендуется проводить регулярные аудиты сайта, чтобы убедиться, что не обнаружено проблем с дублированным контентом. Вы можете сделать это с помощью SEO PowerSuite Website Auditor (если у вас небольшой сайт с менее чем 500 ресурсами, бесплатной версии должно быть достаточно; для больших веб-сайтов вам понадобится лицензия WebSite Auditor).
Чтобы запустить проверку на дублирующийся контент, запустите WebSite Auditor и создайте проект для своего сайта.Подождите, пока приложение не завершит сканирование. Когда закончите, обратите внимание на раздел факторов SEO на странице слева, особенно на Дублирующиеся заголовки и Дублирующиеся метаописания . Если какой-либо из них имеет статус Ошибка , нажмите на проблемный фактор, чтобы увидеть полный список страниц с повторяющимися заголовками / описаниями.
Проверить дубликаты в разделе на странице
Если по какой-то причине вы не можете удалить повторяющиеся страницы, о которых говорило обновление Google Panda, используйте 301 редирект или канонический тег; в качестве альтернативы вы можете заблокировать страницы от индексации Google Spider с помощью robots.txt или метатег noindex.
2. Проверить на плагиат. Внешний дублированный контент — еще один триггер Panda. Если вы подозреваете, что некоторые из ваших страниц могут дублироваться извне, рекомендуется проверить их с помощью Copyscape. Copyscape предоставляет некоторые данные бесплатно (например, позволяет сравнивать два определенных URL-адреса), но для полной проверки вам может потребоваться платная учетная запись.
Многие отрасли (например, интернет-магазины с тысячами товарных страниц) не всегда могут иметь 100% уникальный контент.Если у вас есть сайт электронной коммерции, постарайтесь использовать оригинальные изображения там, где это возможно, и поощряйте отзывы пользователей, чтобы описания ваших продуктов выделялись из общей массы.
3. Определите тонкое содержимое. Тонкое содержимое — это немного расплывчатый термин, но обычно он используется для описания недостаточного количества уникального содержимого на странице. Тонкие страницы состоят из дублированного контента, очищенного или созданного автоматически. Как правило, тонкий контент появляется на страницах с небольшим количеством слов, заполненных рекламой, партнерскими ссылками и т. Д., и имеют небольшую первоначальную ценность. Если вы чувствуете, что ваш сайт может быть оштрафован обновлением Google Panda за тонкий контент, попробуйте измерить его с точки зрения количества слов и количества исходящих ссылок на странице.
Чтобы проверить тонкое содержимое, перейдите к модулю Pages в своем проекте WebSite Auditor. Найдите столбец Word count (если его там нет, щелкните правой кнопкой мыши заголовок любого столбца, чтобы войти в режим редактирования рабочей области, и добавьте столбец Word count в активные столбцы).Затем отсортируйте страницы по количеству слов, щелкнув заголовок столбца, чтобы мгновенно определить страницы с очень небольшим содержанием, которые могут быть поражены Panda.
Определение тонкого содержимого в модуле Pages
Затем перейдите на вкладку Ссылки и найдите столбец Внешние ссылки , в котором отображается количество исходящих внешних ссылок на странице. Вы также можете отсортировать свои страницы по этому столбцу, щелкнув его заголовок. Вы также можете добавить в это рабочее пространство столбец Word count , чтобы увидеть корреляцию между исходящими ссылками и количеством слов на каждой из ваших страниц.Следите за страницами с небольшим содержанием и большим количеством исходящих ссылок.
Имейте в виду, что «желаемое» количество слов на любой странице связано с целью страницы и ключевыми словами, на которые она нацелена. Например. для запросов, подразумевающих, что пользователь ищет быструю информацию («какая столица Нигерии», «заправочные станции в Лас-Вегасе»), страницы с содержанием из сотни слов могут исключительно хорошо работать в Google. То же самое и с пользователями, которые ищут видео или изображения.Но если это не те запросы, на которые вы нацеливаетесь, слишком много страниц с тонким контентом (<250 слов) могут доставить вам неприятности.
Что касается исходящих ссылок, Google рекомендует, чтобы общее количество ссылок на каждой странице не превышало 100. Так что, если вы обнаружите страницу с , менее 250 слов контента и более 100 ссылок , это довольно надежный показатель тонкой страницы с контентом.
4. Проведите аудит своего сайта на предмет наполнения ключевыми словами. Наполнение ключевыми словами — это термин, используемый для описания чрезмерной оптимизации данного элемента страницы для ключевого слова.Когда все усилия по оптимизации терпят неудачу и ваши страницы не достигают желаемой десятки, это может указывать на проблемы с заполнением ключевыми словами и санкциями за обновление Google Panda. Чтобы выяснить, так ли это, просмотрите страницы ваших лучших конкурентов (это именно то, что SEO PowerSuite WebSite Auditor использует в своей формуле наполнения ключевыми словами, в дополнение к общим лучшим практикам SEO).
В своем проекте WebSite Auditor перейдите к Content Analysis и добавьте страницу, которую вы хотите проанализировать на предмет проблем, связанных с Panda.Введите ключевые слова, на которые вы нацелены на этой странице, и дайте инструменту провести быструю проверку. По завершении аудита обратите внимание на Ключевые слова в заголовке , Ключевые слова в метаописании , Ключевые слова в теле и Ключевые слова в h2 . Просмотрите эти факторы один за другим и посмотрите на столбец Ключевые слова . Вы увидите здесь значение Да, , если вы чрезмерно используете ключевые слова в любом из этих элементов страницы. Чтобы узнать, как ваши основные конкуренты используют ключевые слова, перейдите на вкладку Competitors .
Сделайте SEO оптимизацию на странице в модуле аудита страницы
5. Устраните обнаруженные проблемы. После того, как вы определили уязвимости, подверженные Panda, постарайтесь исправить их как можно скорее, чтобы избежать попадания в следующую итерацию алгоритма Panda (или для быстрого восстановления, если вы были оштрафованы). Для небольшого количества страниц с повторяющимся содержанием используйте редактор содержимого веб-сайта аудитора, чтобы редактировать эти страницы прямо в модуле и видеть, как улучшается коэффициент качества на ходу.Перейдите в Content Analysis> Content Editor и отредактируйте содержимое в редакторе WYSIWYG или HTML. Здесь вы можете поиграть со своими заголовками и метаописанием в удобном редакторе с предварительным просмотром фрагмента Google. Слева коэффициенты на странице будут пересчитываться по мере ввода. После того, как вы внесете необходимые изменения, нажмите кнопку «Загрузить PDF» или нажмите кнопку «Ошибка вниз», чтобы экспортировать документ в виде HTML-файла на жесткий диск.
Оптимизируйте на ходу в модуле редактора контента
Скачать SEO PowerSuite
Если вам нужны более подробные инструкции, перейдите к этому 6-этапному руководству по проведению аудита содержимого на предмет проблем с обновлением Panda.
2. Обновление Penguin
Запущен: 24 апреля 2012 г.
Внедрение: 25 мая 2012 г .; 5 октября 2012 г .; 22 мая 2013 г .; 4 октября 2013 г .; 17 октября 2014 г .; 27 сентября 2016 г .; 6 октября 2016 г .; в реальном времени с
Цель: Понизить рейтинг сайтов со спамом и манипулятивными ссылочными профилями
Обновление Google Penguin направлено на выявление и снижение рейтинга сайтов с неестественными ссылочными профилями, которые, как считается, рассылают спам в результатах поиска с помощью тактики манипуляции ссылками .Google выпускал обновления Penguin один или два раза в год до 2016 года, когда Penguin стал частью основного алгоритма ранжирования Google. Теперь он работает в режиме реального времени, а это означает, что штрафы алгоритма применяются быстрее, а восстановление также занимает меньше времени.
Опасности
Как оставаться в безопасности с Penguin
1.Следите за ростом ссылочного профиля. Google вряд ли накажет сайт за одну или две спамерские ссылки, но внезапный приток токсичных обратных ссылок может стать проблемой. Чтобы избежать наказания за обновления Google Penguin, следите за любыми необычными всплесками в своем профиле ссылок и всегда обращайте внимание на новые ссылки, которые вы приобретаете. Создавая проект для своего сайта в SEO PowerSuite SEO SpyGlass , вы сразу увидите графики прогресса как для количества ссылок в вашем профиле, так и для количества ссылающихся доменов.Необычный всплеск на любом из этих графиков является достаточной причиной для проверки ссылок, которые внезапно получил ваш сайт, чтобы защитить его от штрафа Google.
Найдите резкие спуски или всплески в своем профиле обратных ссылок
2. Проверить риски штрафа. Статистика, которую, вероятно, рассматривает обновление Penguin, включена в SEO SpyGlass и его формулу Penalty Risk , поэтому вместо того, чтобы рассматривать каждый отдельный фактор по отдельности, вы можете взвесить их в целом, как это делает алгоритм Google.
В своем проекте SEO SpyGlass переключитесь на панель Linking Domains и перейдите на вкладку Link Penalty Risks . Выберите все домены в списке и нажмите Обновить риск наказания за ссылку . Дайте SEO SpyGlass минуту, чтобы оценить все виды качественной статистики для каждого из доменов. Когда проверка будет завершена, изучите столбец Penalty Risk и обязательно вручную изучите каждый домен со значением Penalty Risk , превышающим 50%.
Просмотрите обратные ссылки с высокой оценкой риска штрафа
Если вы используете бесплатную версию SEO SpyGlass, вы сможете проанализировать до 1000 ссылок; если вы хотите проверить больше ссылок, вам понадобится лицензия Professional или Enterprise.
3. Избавьтесь от вредоносных ссылок. В идеале вам следует попытаться запросить удаление спам-ссылок в вашем профиле Google, связавшись с веб-мастерами сайтов, на которые есть ссылки. Но если у вас есть много вредоносных ссылок, от которых нужно избавиться, или если вы не получили ответа от веб-мастеров, единственное средство, которое у вас есть, — это отклонить некачественные ссылки с помощью инструмента Google Disavow.Таким образом, вы укажете пауку Google игнорировать эти ссылки при оценке вашего ссылочного профиля. Файлы Disavow могут быть сложными с точки зрения синтаксиса и кодировки, но SEO SpyGlass может автоматически сгенерировать их для вас в нужном формате.
В своем проекте SEO SpyGlass выберите ссылки, которые вы собираетесь отклонить, щелкните выделение правой кнопкой мыши и нажмите Отклонить обратные ссылки . Выберите режим отклонения для ваших ссылок (как правило, вы хотите отклонять целые домены, а не отдельные URL-адреса).Сделав это для всех вредоносных ссылок в своем проекте, перейдите в «Настройки »> «Черный список» / «Отклонить обратные ссылки» , просмотрите свой список и нажмите « Экспорт », чтобы сохранить файл на жесткий диск. Наконец, загрузите только что созданный файл отклонения в инструмент Google Disavow.
Создайте файл отклонения и отправьте его в Google с помощью инструмента отклонения.
Поскольку он стал основным алгоритмом ранжирования, нельзя с уверенностью сказать, что обновление Penguin произойдет в тот или иной день.Если вы заметили, что авторитет или видимость вашего сайта упали, это может быть сигналом о том, что Penguin наложил на сайт штрафы. Точно так же нельзя точно сказать, когда произойдет полное восстановление после удаления всех вредоносных ссылок. Положительные эффекты должны иметь место еще со следующим сканированием пауков Google. Однако нельзя ожидать, что авторитет сайта вернется прямо на прежний уровень, поскольку он был завален искусственными ссылками. Вам нужно будет применить более точную тактику построения ссылок.
Примечание
Иногда сайты подвергаются ручному наказанию Google, а не санкциям алгоритма Penguin. Это происходит, когда рецензенты в Google замечают тактику манипуляций на сайте, которая осталась незамеченной в обновлении Penguin. Вы получите уведомление о ручном наказании Google на вкладке «Ручные действия» в Search Console. Ваши действия здесь следуют аналогичному пути восстановления: перейдите, чтобы удалить или отклонить плохие обратные ссылки, и попросите Google пересмотреть ручное действие.
Скачать SEO PowerSuite
Для получения более подробных инструкций по проведению аудита ссылок с защитой от Penguin перейдите сюда.
3. Пиратское обновление
Запущено: августа 2012 г.
Внедрение: окт. 2014 г.
Цель: Понизить рейтинг сайтов с сообщениями о нарушении авторских прав
Google Pirate Update был разработан, чтобы не дать сайтам, получившим многочисленные сообщения о нарушении авторских прав, занять высокие позиции в поиске Google.Большинство затронутых сайтов являются относительно большими и хорошо известными веб-сайтами, на которых делало пиратский контент (например, фильмы, музыку или книги) доступным для посетителей бесплатно , особенно торрент-сайты. Тем не менее, Google по-прежнему не в силах довести до конца многочисленные новые сайты с пиратским контентом, которые появляются буквально каждый день.
Опасности
Как оставаться в безопасности с Pirate
Не распространяйте чей-либо контент без разрешения владельца авторских прав.Действительно, вот и все.
4. Обновление Hummingbird
Запущен: 22 августа 2013 г.
Внедрение: —
Цель: Обеспечение более релевантных результатов поиска за счет лучшего понимания смысла запросов
Google Hummingbird — это серьезное изменение алгоритма, которое касается интерпретации поисковых запросов (особенно длинных, разговорных) и предоставления результатов поиска , которые соответствуют намерениям поисковика, а не отдельным ключевым словам в запросе.Название алгоритма Google было получено из сравнения его точности и скорости с колибри.
Хотя ключевые слова в запросе по-прежнему важны, Hummingbird добавляет больше силы к смыслу запроса в целом. Использование синонимов также было оптимизировано с помощью Hummingbird; вместо того, чтобы перечислять результаты с точным соответствием ключевому слову, алгоритм Google показывает больше результатов, связанных с темой, в результатах поиска, которые не обязательно содержат ключевые слова из запроса в своем содержании.
Опасности
Как оставаться в безопасности с Hummingbird
1. Расширьте область исследования ключевых слов. Используя Hummingbird, вам нужно сосредоточиться на связанных поисковых запросах, синонимах и совпадающих терминах, чтобы разнообразить свой контент, вместо того, чтобы полагаться исключительно на короткие термины, которые вы получили бы от Google Рекламы. Отличные источники удобных для колибри идей ключевых слов — это поисковые запросы по теме Google, автозаполнение Google и Google Trends.Все они включены в программу Rank Tracker SEO PowerSuite.
Чтобы начать расширять список целевых ключевых слов, откройте Rank Tracker и создайте или откройте проект. Введите исходные термины, на которых будет основано ваше исследование, и нажмите для поиска. На следующем этапе перейдите к модулю Keyword Research и сначала проверьте свои ключевые слова в рейтинге. Затем, одно за другим, исследуйте свои потенциальные ключевые слова для ранжирования с помощью всех доступных методов исследования ключевых слов. Например, выберите метод Relates Searches , добавьте ключевые слова темы и нажмите Search .
Используйте исследование ключевых слов, чтобы найти больше идей для контента и возможностей ранжирования
Подождите, пока Rank Tracker будет предлагать вам предложения, и когда это будет сделано, все варианты ключевых слов будут в песочнице, откуда вы сможете выбрать те, которые заслуживают добавления в свой список отслеживания рейтинга. Затем повторите процесс еще раз, на этот раз выбрав Google Autocomplete Tools в качестве метода исследования. Сделайте то же самое для Связанные вопросы . Затем перейдите к анализу эффективности и сложности ключевых слов и выберите основные термины, чтобы сопоставить их с целевыми страницами.
2. Узнайте, какой язык использует ваша аудитория. Вполне логично, что копия вашего веб-сайта должна говорить на том же языке, что и ваша аудитория, а Колибри — еще одна причина активизировать семантическую игру. Отличный способ сделать это — использовать инструмент для прослушивания социальных сетей (например, Awario), чтобы изучить упоминания ваших ключевых слов (ваш бренд, конкуренты, отраслевые термины и т. Д.) И увидеть, как ваша аудитория говорит об этих вещах в социальных сетях. СМИ и Интернет в целом.
3. Откажитесь от точного соответствия, подумайте о концепциях. Неестественные фразы, особенно в заголовках и метаописаниях, по-прежнему популярны среди веб-сайтов, но с растущей способностью поисковых систем обрабатывать естественный язык это может стать проблемой. Если вы по какой-то причине по-прежнему используете на своих страницах язык роботов, с обновлением Hummingbird (или, если честно, за четыре года до этого) самое время остановиться.
Включение ключевых слов в заголовок и описание по-прежнему имеет значение; но не менее важно, чтобы вы походили на человека.В качестве приятного побочного эффекта улучшение заголовка и метаописания обязательно увеличит количество кликов, получаемых вашим листингом в Google.
Чтобы поэкспериментировать с заголовками и метаописаниями, используйте SEO PowerSuite WebSite Auditor . Запустите инструмент, создайте или откройте проект и перейдите к модулю Pages . Просмотрите заголовки и метаописания своих страниц и найдите те, которые выглядят так, как будто они были созданы исключительно для ботов поисковых систем. Когда вы обнаружите заголовок, который хотите исправить, щелкните страницу правой кнопкой мыши и выберите Анализировать содержимое страницы .Инструмент попросит вас ввести ключевые слова, под которые вы хотите оптимизировать свою страницу. Когда анализ будет завершен, перейдите в Content Editor , перейдите на вкладку Title & Meta tags и перепишите заголовок и / или мета-описание. Справа внизу вы увидите предварительный просмотр своего фрагмента кода Google.
Измените заголовок и мета-описание и получите предварительный просмотр фрагмента
Скачать SEO PowerSuite
5. Обновление Pigeon
Запущен: 24 июля 2014 г. (США)
Внедрение: 22 декабря 2014 г. (Великобритания, Канада, Австралия)
Цель: Обеспечение высококачественных релевантных результатов местного поиска
Google Pigeon (изначально опробованный только на английском) резко изменил результаты, которые Google возвращает для запросов, в которых играет роль местоположение искателя.Согласно Google, Pigeon установил более тесные связи между локальным алгоритмом и основным алгоритмом поиска, а это означает, что те же факторы SEO теперь используются для ранжирования локальных и нелокальных результатов Google . Это обновление также использует местоположение и расстояние как ключевые факторы при ранжировании результатов.
Pigeon привел к значительному (по крайней мере, 50%) снижению количества запросов, по которым возвращаются локальные пакеты, повысил рейтинг локальных сайтов-каталогов и более согласованно соединил поиск Google в Интернете и поиск Google Map.
Опасности
Как оставаться в безопасности с Pigeon
1. Оптимизируйте свои страницы должным образом. Pigeon ввел те же критерии SEO для местных списков, что и для всех других результатов поиска Google. Это означает, что местным компаниям теперь необходимо приложить немало усилий для оптимизации страниц.Хорошей отправной точкой является анализ страницы с помощью SEO PowerSuite WebSite Auditor . Инструментальная панель Content Analysis даст вам хорошее представление о том, на каких аспектах оптимизации на странице вам нужно сосредоточиться (ищите факторы со статусами Предупреждение или Ошибка ). Всякий раз, когда вы чувствуете, что можете использовать какую-либо информацию, переключитесь на вкладку Competitors , чтобы увидеть, как ваши ведущие конкуренты справляются с той или иной частью на странице SEO.
Изучите контент своих конкурентов, чтобы узнать об их методах оптимизации
Подробное руководство по оптимизации на странице можно найти в разделе «Рабочий процесс SEO» на странице.
2. Создайте страницу Google My Business. Создание страницы Google My Business для вашего местного бизнеса — это первый шаг к включению в локальный индекс Google. Ваш второй шаг будет заключаться в подтверждении вашего права собственности на листинг; Обычно это связано с получением письма от Google с пин-кодом, который необходимо ввести для завершения проверки.
При настройке страницы убедитесь, что вы правильно классифицируете свой бизнес — в противном случае ваше объявление не будет отображаться для соответствующих запросов. Не забудьте указать в номере телефона код вашего города; код города должен соответствовать коду, традиционно связанному с вашим местоположением. Количество положительных отзывов также может повлиять на рейтинг в локальном поиске, поэтому вам следует побуждать довольных клиентов оставлять отзывы о вашем месте.
3. Убедитесь, что ваш NAP согласован во всех ваших местных списках. Поисковая система Google просмотрит веб-сайт, на который вы перешли со страницы Google My Business, и сопоставит имя, адрес и номер телефона вашей компании. Если все элементы совпадают, все готово.
Если ваша компания также представлена в любых местных каталогах, убедитесь, что название компании, адрес и номер телефона также совпадают во всех этих списках. Например, разные адреса, указанные для вашей компании на Yelp и TripAdvisor, могут привести к потере вашего местного рейтинга.
4. Разместитесь в соответствующих местных каталогах. Местные каталоги Yelp, TripAdvisor и другие компании значительно повысили рейтинг после обновления Pigeon. Поэтому, хотя сейчас вашему сайту может быть труднее попасть в топ, рекомендуется убедиться, что вы представлены в бизнес-каталогах, которые, вероятно, будут иметь высокий рейтинг. Вы можете легко найти качественные каталоги и обратиться к веб-мастерам, чтобы запросить функцию с помощью инструмента построения ссылок SEO PowerSuite, LinkAssistant .
Запустите LinkAssistant и откройте или создайте проект для своего сайта. Щелкните Ищите потенциальных клиентов в верхнем левом углу и выберите Каталоги в качестве метода исследования.
Введите ключевые слова — просто как подсказку, укажите ключевые слова категории плюс ваше местоположение (например, «дантист Денвер») — и дайте инструменту секунду, чтобы найти соответствующие каталоги в вашей нише.
Через минуту вы увидите список каталогов вместе с контактными адресами электронной почты веб-мастеров.Теперь выберите один из каталогов, в который вы хотите добавить, щелкните его правой кнопкой мыши и нажмите Отправить электронное письмо выбранному партнеру . Настройте параметры электронной почты, составьте сообщение (или выберите готовый шаблон электронной почты) и отправьте его!
Скачать SEO PowerSuite